Tutorial 4: Up Next
![]()
We have started to scratch the surface of distributed training with our first three tutorials. Why is that?
We have been using JAX’s underlying GSPMD compiler to distribute our model across multiple devices. This is a powerful tool, but it abstracts away most of the complexities of distributed training such as implementing the collectives operations for us. For finer-grained control over distributed training, we would often need to implement our own sharded layers, collectives, training loops, and even backward passes.
There are several libraries that provide a lot of underlying primitives for distributed training, the two most popular ones being Megatron-LM and DeepSpeed. If you want to continue working with JAX, you can look at the MaxText library, which was used for traiing the PaLM language model. A Pytorch native library in active development for distributed training is Torch Titan.
While all of these libraries are great, they might be a bit overwhelming to get started with if you are new to distributed deep learning. At the end of this tutorial is a list of resources to help you get started with more accessible resources.
In the rest of this notebook, we will get a sense of what lies ahead in the landscape of distributed training and where you can read more about it.
1. Other Forms of Parallelism in Distributed Deep Learning

Image Source: UvA Deep Learning Tutorials
1.1 Pipeline Parallelism
Data and Tensor parallelism can be grouped together as intra-layer parallelism, where each layer is sharded across different devices. In contrast, pipeline parallelism is a form of inter-layer parallelism. In this approach, the model is divided into multiple stages (several groups of layers), and each stage is assigned to a different device. The input data flows through these stages sequentially, and each accelerator handles one stage (figure below). It effectively reduces memory usage of each accelerator.
Both tensor and pipeline parallelism involve splitting the model across multiple devices, and are grouped together as model parallelism.
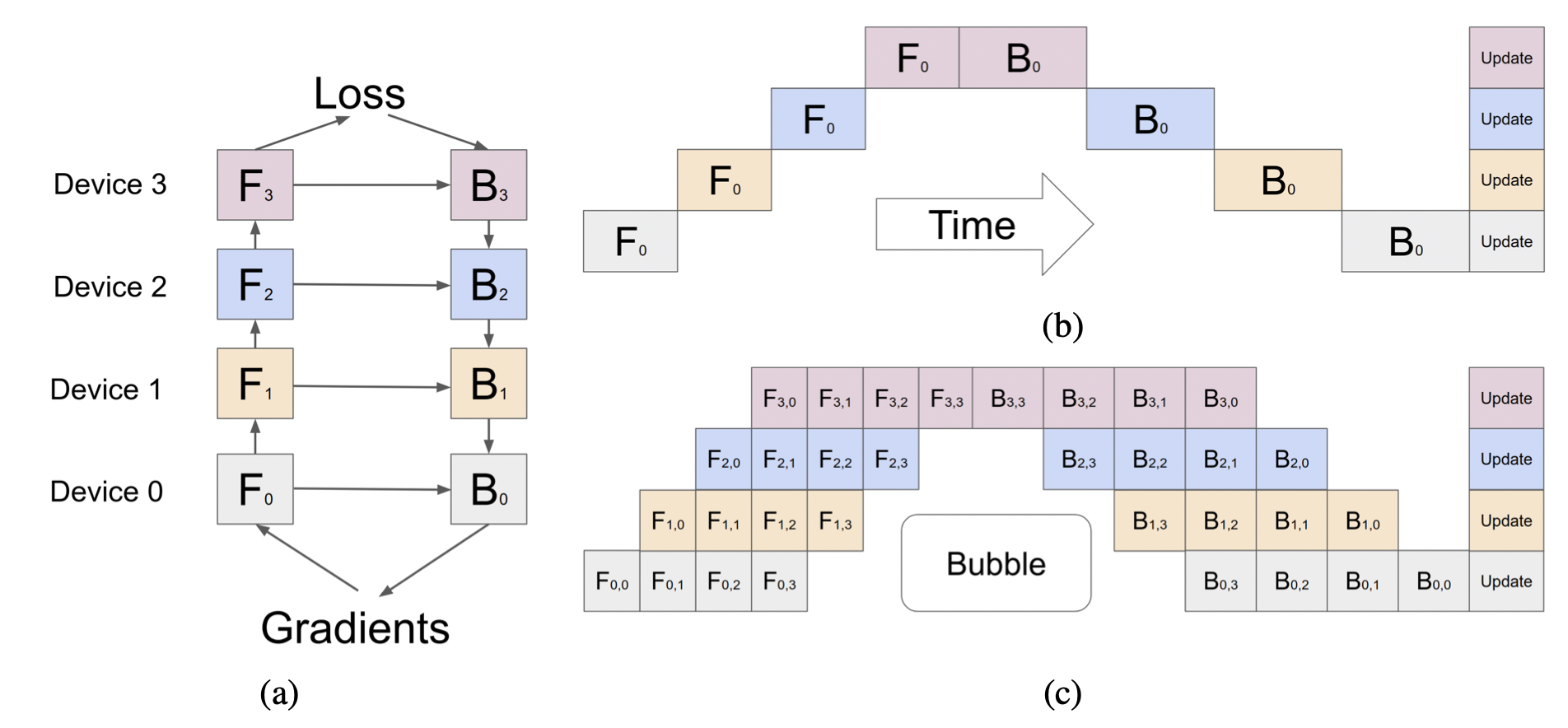
Image Source: Google GPipe
Pipeline parallelism is very common for distirbuted training on GPUs, but not used as much on TPUs.
Training with a combination of data, tensor, and pipeline parallelism is often referred to as 3D parallelism.
1.2 Sequence Parallelism
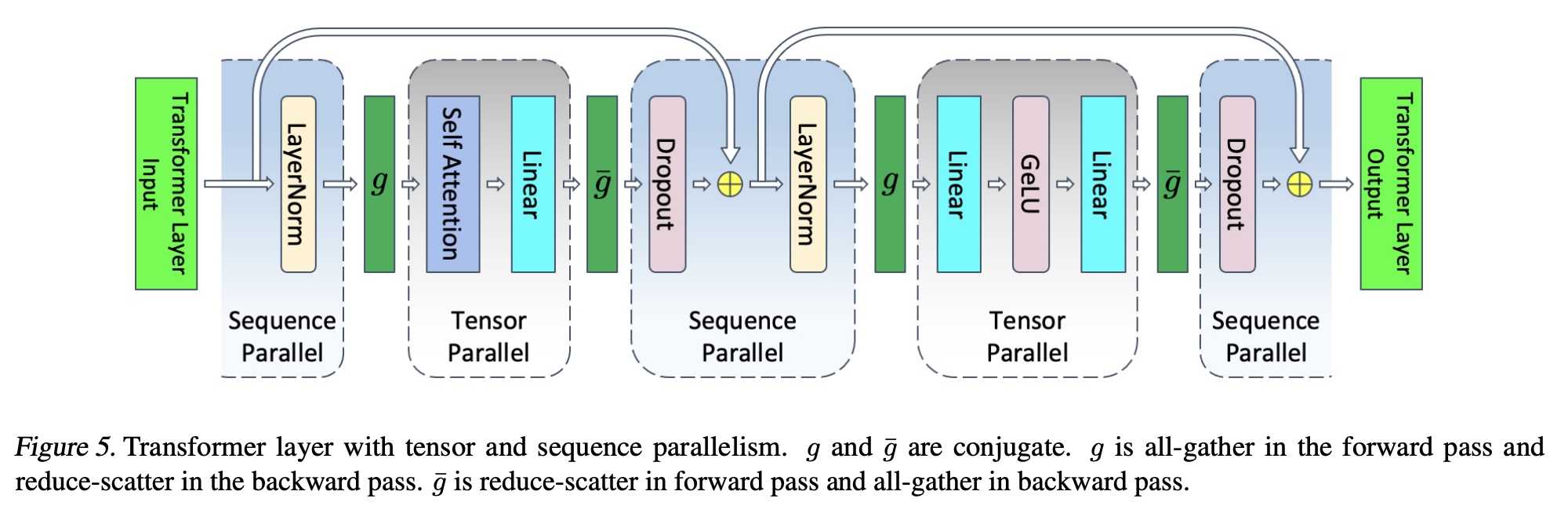
Image Source: Reducing Activation Recomputation in Large Transformer Models
Sequence parallelism was introduced with tensor parallelism by NVIDIA. When we covered tensor parallelism in the last tutorial, we only applied it to the MLP and Attention layers. But it cannot be applied to other layers which involve access to feature level statistics, such as the LayerNor layer. Sequence parallelism is a technique that allows us to apply tensor parallelism to these layers as well. These operations are independent along the sequence dimension (i.e. along token dimension), so they can be parallelized along the sequence dimension.
1.3 Context Parallelism

Image Source: xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Context parallelism can be thought of as a form of sequence parallelism, but it is applied independently of tensor parallelism (unlike sequence parallelism).It parallelizes training/inference prefill on a long sequence by partitioning the sequence into multiple subsets of tokens which are distributed across devices. To maintain the context and relationship between tokens, each device needs to communicate to compute attention exactly the same as local attention computation.
1.4 Expert Parallelism
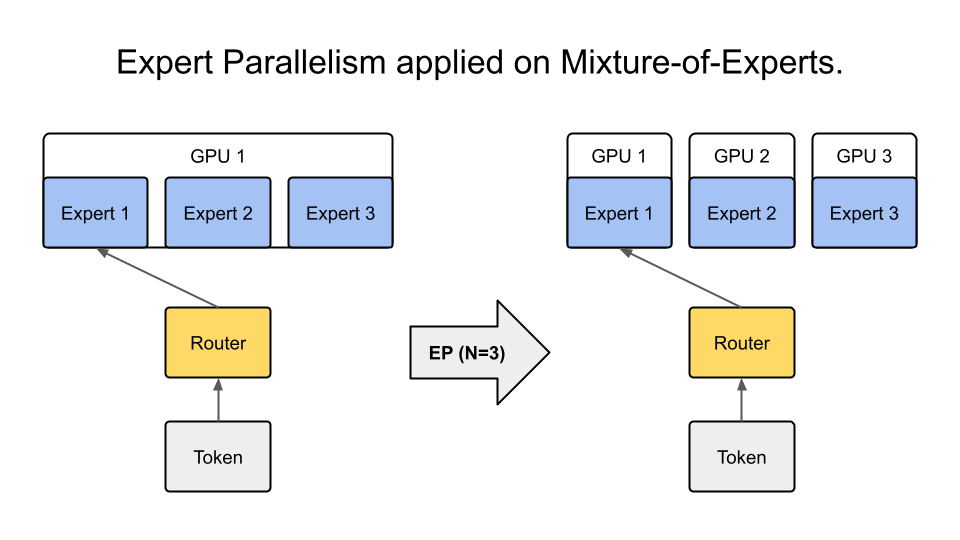
In expert parallelism, the weights of each expert in a Mixture of Experts (MoE) model are distributed across different GPUs. This is still a very new area of research, and overlapping communication and computation for MoEs is still an open problem.
2. What to Read Next
These are some accessible resources to get you started with distributed training and inference:
HuggingFace Nanotron Pytorch library for minimalistic large language model 3D-parallelism training, and Ultrascale Playbook - a comprehensive guide to efficiently scale LLM training with Nanotron
How to Scale Your Model book and High Performance LLMs Course for an equivalent in the JAX ecosystem
[Reference] Awesome Distributed Machine Learning Systems - a curated list of resources on distributed machine learning systems.