Tutorial 2: Data Parallel and Fully Sharded Data Parallel Training
![]()
In the previous tutorial, we explored the basics of JAX parallelization, including device meshes, sharded matrices, and collective operations. In this tutorial, we’ll build on those concepts to explore the first parallelism strategy used in scaling models: data parallelism (DP). After data parallelism, we will learn about the second parallelism strategy used in scaling models: Fully Sharded Data Parallelism (FSDP).
Learning objectives:
Understand data parallelism
Learn about implementing neural networks in Flax
Learn about the Fully Sharded Data Parallel (FSDP) strategy
Prerequisites (covered in Tutorial 1):
Basic familiarity with JAX
Understanding of JAX sharding
Understanding of sharded matrix operations
0. Background
0.1 Setup
Let’s start by importing the necessary libraries and initializing our environment.
[1]:
import os
# Force JAX to use 8 GPU devices for this tutorial (only use if not using TPU runtime)
#os.environ['XLA_FLAGS'] = '--xla_force_host_platform_device_count=8'
import jax
import jax.numpy as jnp
from jax.sharding import Mesh, PartitionSpec as P, NamedSharding
from jax.experimental import mesh_utils
import numpy as np
import matplotlib.pyplot as plt
import time
from functools import partial
import dataclasses
[2]:
# Check available devices
print(f"JAX version: {jax.__version__}")
print(f"Available devices: {jax.devices()[:4]}...")
print(f"Number of devices: {jax.device_count()}")
JAX version: 0.5.2
Available devices: [TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0), TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1), TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0), TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1)]...
Number of devices: 8
0.2 Model Representation
For simplicity, we will start with a simple feed-forward model. The model consists of two fully-connected (or dense) layers:
Win:
bf16[D, F](up-projection)Wout:
bf16[F, D](down-projection)
And the input and output are defined as:
Input:
bf16[B, D]Out:
bf16[B, D]
Where:
D = dmodel (input/output dimension)
F = dff (feed-forward or hidden dimension)
B = batch size (total tokens)
Image Source: How To Scale Your Model
0.3 Why Parallelism?
As we scale up our models and datasets, we need to distribute the computation across multiple devices in order to train these models in reasonable periods of time. For example, 2048 A100 GPUs were used to train LLaMa. If they were to train LLama 3 8B model (the smallest Llama 3 model) on a single A100 GPU, it would take approximately 1.46 million hours (or 166 years) to complete the training. This is why we need parallelism.
We also want to optimize the time spent doing various computations in the training process - since some operations are independent of each other, we can spread them across multiple devices to speed up the training process. We will see more examples of this when we discuss each training strategy.
0.4 Communication vs Computation Trade-offs
The goal of scaling is to achieve strong scaling, a linear increase in throughput with more chips. In order to achieve good scaling performance, parallel algorithms are designed to hide inter-chip communication by overlapping it with useful FLOPs.
Let \(T_\text{ops}\) represent the time spent on computation (FLOPs) and \(T_{\text{comms}}\) represent the time spent on communication (data transfer). For the purpose of this tutorial, let us ignore intra-chip communication cost and focus on inter-chip communication costs (although in the real world, you would consider both - but let’s assume that intra-chip communication and computation overlap have already been optimized).
The ratio of these two times (\(T_\text{ops}\) and \(T_{\text{comms}}\)) is crucial for determining the efficiency of our parallel training:
An algorithm become compute-bound when:
This means that the time spent on computation is greater than the time spent on communication, and we can achieve good scaling performance by hiding communication time between the time spend on computation. Let us see what this means in practice.
1. Data Parallel
Data parallelism (DP) is a parallelization strategy where we split the input data batch across multiple devices, allowing each device to compute on a different subset of the data. This is particularly useful for large datasets that cannot fit into the memory of a single device. When the model is small enough to fit on a single device, we can use data parallelism to scale up the training by distributing the data across multiple devices.
1.1 Data Parallelism Theory
Sharding: Input data and model activations are sharded along batch dimension across devices, model parameters are replicated on each device.
Equation (for our MLP example):
where \(B_X\) indicates the batch is sharded across \(X\) devices.

Image Source: How To Scale Your Model
2. Data Parallel Algorithm
One of the key advantages of data parallelism is that there is no communication between devices during the forward pass. Each device computes its own forward pass independently on the sharded batch without moving any data around.
2.1 Forward pass
Tmp[BX, F] = In[BX, D] ×D Win[D, F]
Out[BX, D] = Tmp[BX, F] ×F Wout[F, D]
Loss[BX] = …
In the backward pass, we need the gradients from the full batch across all devices. In order to do so, we first compute the gradients for each device (Steps 2 and 5 below). However, these are only the gradients for the sharded batch on each device. To compute the gradients for the full batch, we need to aggregate the gradients across all devices (Steps 3 and 6 below). This is done with AllReduce operation on the gradients from all devices.
One important thing to note is that the backward pass computation for the current iteration does not involve the collected gradients from this iteration. We say that the gradient accumulation in the backward passs is not on a critical path - the rest of the backward pass can continue while the gradients are being communicated. This means that we can overlap the communication of the gradients with the computation on each device. This is crucial for achieving good scaling performance.
2.2 Backward pass
dOut[BX, D] = …
dWout[F, D] {UX} = Tmp[BX, F] *B dOut[BX, D]
dWout[F, D] = AllReduce(dWout[F, D] {UX}) (not on critical path, can be done async)
dTmp[BX, F] = dOut[BX, D] *D Wout[F, D]
dWin[D, F] {UX} = In[BX, D] *B dTmp[BX, F]
dWin[D, F] = AllReduce(dWin[D, F] {UX}) (not on critical path, can be done async)
dIn[BX, D] = dTmp[BX, F] *F Win[D, F] (needed for previous layers)
2.3 Compute Bound versus Communication Bound
As we can see above, we have two AllReduces per layer, each of size
(for bf16 weights). When does data parallelism make us communication bound?
Let \(C\) = per-chip FLOPs, \(W_{\text{ici}}\) = bidirectional network bandwidth, and \(X\) = number of shards across which the batch is partitioned. Let’s calculate the time required to perform the relevant matmuls (compute time), \(T_\text{math}\), and the required communication time \(T_\text{comms}\). Since this parallelism scheme requires no communication in the forward pass, we only need to calculate these quantities for the backwards pass.
Communication time
Time required to perform an AllReduce in a 1D mesh depends only on the total bytes of the array being AllReduced and the ICI bandwidth \(W_\text{ici}\); specifically the AllReduce time is \(2 \cdot \text{total bytes} / W_\text{ici}\). Since we need to AllReduce for both \(W_\text{in}\) and \(W_\text{out}\), we have 2 AllReduces per layer. Each AllReduce is for a weight matrix, i.e. an array of \(DF\) parameters, or \(2DF\) bytes. Putting this all together, the total time for the AllReduce in a single layer is
Computation time
Each layer comprises two matmuls in the forward pass, or four matmuls in the backwards pass, each of which requires \(2(B/X)DF\) FLOPs. Thus, for a single layer in the backward pass, we have
Since we overlap, the total time per layer is the max of these two quantities:
We become compute-bound when \(T_\text{math}/T_\text{comms} > 1\), or when \(\frac{B}{X} > \frac{C}{W_\text{ici}}.\)
The upshot is that, to remain compute-bound with data parallelism, we need the per-device batch size
to exceed the ICI operational intensity, \(C / W_\text{ici}\). This is ultimately a consequence of the fact that the computation time scales with the per-device batch size, while the communication time is independent of this quantity (since we are transferring model weights).
For TPU v2 pods, we follow the same analytical framework to determine when data parallelism becomes communication-bound.
TPU v2 Specifications:
Per-chip compute: C = 4.5e13 FLOPS (45 TFLOPS at bfloat16)
ICI bandwidth: W_ici = 2.48e11 bytes/s (4 links @ 496 Gbits/s per direction = 248 GB/s unidirectional)
2D torus topology connecting up to 256 chips
Critical Condition: Data parallelism remains compute-bound when the per-device batch size exceeds:
Key Results:
Minimum batch size per chip: ~181 tokens to avoid communication bottleneck
For a full 256-chip TPU v2 pod, this translates to a minimum global batch size of ~46K tokens
Practical Implications: The relatively low threshold of 181 tokens per chip makes TPU v2 pods well-suited for typical training workloads. This tells us that it’s fairly hard to become bottlenecked by pure data parallelism! Most production models use batch sizes well above this threshold, ensuring efficient utilization without communication bottlenecks during data-parallel training.
3. Example: 8-way Data Parallel Training with Plain JAX
3.1 Create dataset and define model
First, let’s generate our synthetic dataset and simple feed-forward neural network.
[3]:
def get_linear_layer(key, dim_in, dim_hidden):
k1, k2 = jax.random.split(key)
W = jax.random.normal(k1, (dim_in, dim_hidden)) / jnp.sqrt(dim_in)
b = jax.random.normal(k2, (dim_hidden,))
return W, b
def get_model_and_data(key, layer_sizes, batch_size):
keys, *keys = jax.random.split(key, len(layer_sizes))
model = list(map(get_linear_layer, keys, layer_sizes[:-1], layer_sizes[1:]))
# The model is just a list of linear layers. A more readable version of the above is:
# model = [
# get_linear_layer(k, in_dim, out_dim)
# for k, in_dim, out_dim in zip(keys, layer_sizes[:-1], layer_sizes[1:])
#]
keys, *keys = jax.random.split(key, 2)
input_data = jax.random.normal(keys[0], (batch_size, layer_sizes[0]))
target_data = jax.random.normal(keys[0], (batch_size, layer_sizes[-1]))
# data is just random numbers for both inputs and outputs
return model, (input_data, target_data)
We will use a simple feed-forward neural network with two linear layers, as described in the background section. The input and output dimensions are set to 128, which is a common choice of hidden dimension in transformer models. The batch size is set to 8192.
[4]:
# A simple sqeuence-modelling architecture: 128 -> 2048 -> 2048 -> 128
layer_sizes = [128, 2048, 2048, 128]
batch_size = 8192
[5]:
model, batch = get_model_and_data(jax.random.key(0), layer_sizes, batch_size)
Now we define our model’s forward pass and loss function. We are using JAX for now, so this might seem a bit verbose if you are coming from PyTorch or TensorFlow, but we will see how to simplify the neural network modelling with Flax in the next section.
[6]:
def predict(model, inputs):
for W, b in model:
outputs = jnp.dot(inputs, W) + b
inputs = jnp.maximum(outputs, 0) # ReLU activation
return outputs
def loss(model, batch):
inputs, targets = batch
predictions = predict(model, inputs)
return jnp.mean(jnp.sum((predictions - targets)**2, axis=-1))
Finally, we will compile our model using jax.jit to utilize JAX compiler to optimize the performance of our forward and backward pass.
[7]:
loss_jit = jax.jit(loss)
gradfun = jax.jit(jax.grad(loss))
3.2 Single-Device Baseline
Let’s first establish a baseline by training on a single device.
[8]:
batch_single = jax.device_put(batch, jax.devices()[0])
params_single = jax.device_put(model, jax.devices()[0])
[9]:
loss_jit(params_single, batch_single)
[9]:
Array(435.76917, dtype=float32)
[10]:
%timeit -n 5 -r 5 gradfun(params_single, batch_single)[0][0].block_until_ready()
The slowest run took 20.17 times longer than the fastest. This could mean that an intermediate result is being cached.
58.1 ms ± 92 ms per loop (mean ± std. dev. of 5 runs, 5 loops each)
3.3 8-way Data Parallel Training
Now let’s implement 8-way data parallel training where we’ll shard the batch across 8 devices.
[11]:
# Create an 8-device mesh for data parallelism
mesh = jax.make_mesh((8,), ('batch',))
print(f"Mesh shape: {mesh.shape}")
print(f"Mesh axis names: {mesh.axis_names}")
# Create sharding specifications
## Shard data along the batch dimension
batch_sharding = NamedSharding(mesh, P('batch'))
## Replicate parameters across all devices
replicated_sharding = NamedSharding(mesh, P())
Mesh shape: OrderedDict([('batch', 8)])
Mesh axis names: ('batch',)
We shard our batch along batch dimension, while our model is replicated across all devices.
[12]:
batch = jax.device_put(batch, batch_sharding)
params = jax.device_put(model, replicated_sharding)
Let’s visualize how the batch is sharded across devices.
[13]:
print("Visualizing batch sharding across 8 devices:")
print("Original batch shape:", batch[0].shape)
for shard in batch[0].addressable_shards:
print(shard.device, shard.index[0], shard.data.shape)
jax.debug.visualize_array_sharding(batch[0])
Visualizing batch sharding across 8 devices:
Original batch shape: (8192, 128)
TPU_0(process=0,(0,0,0,0)) slice(0, 1024, None) (1024, 128)
TPU_1(process=0,(0,0,0,1)) slice(1024, 2048, None) (1024, 128)
TPU_2(process=0,(1,0,0,0)) slice(2048, 3072, None) (1024, 128)
TPU_3(process=0,(1,0,0,1)) slice(3072, 4096, None) (1024, 128)
TPU_6(process=0,(1,1,0,0)) slice(4096, 5120, None) (1024, 128)
TPU_7(process=0,(1,1,0,1)) slice(5120, 6144, None) (1024, 128)
TPU_4(process=0,(0,1,0,0)) slice(6144, 7168, None) (1024, 128)
TPU_5(process=0,(0,1,0,1)) slice(7168, 8192, None) (1024, 128)
TPU 0 TPU 1 TPU 2 TPU 3 TPU 6 TPU 7 TPU 4 TPU 5
[14]:
loss_jit(params, batch)
[14]:
Array(435.7692, dtype=float32)
[15]:
%timeit -n 5 -r 5 gradfun(params, batch)[0][0].block_until_ready()
The slowest run took 82.19 times longer than the fastest. This could mean that an intermediate result is being cached.
60 ms ± 113 ms per loop (mean ± std. dev. of 5 runs, 5 loops each)
[16]:
step_size = 1e-5
losses = []
for step in range(30):
grads = gradfun(params, batch)
params = [(W - step_size * dW, b - step_size * db)
for (W, b), (dW, db) in zip(params, grads)]
current_loss = loss_jit(params, batch)
losses.append(float(current_loss))
if step % 5 == 0:
print(f"Step {step}, loss: {current_loss:.6f}")
print(f"\nFinal loss: {loss_jit(params, batch):.6f}")
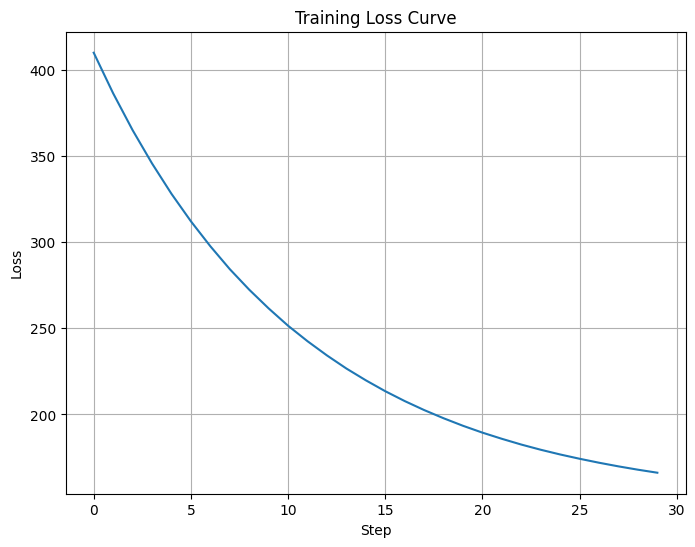
Step 0, loss: 409.836945
Step 5, loss: 312.069946
Step 10, loss: 251.479156
Step 15, loss: 213.499405
Step 20, loss: 189.462906
Step 25, loss: 174.309052
Final loss: 166.210480
[17]:
# Visualize the loss curve
plt.figure(figsize=(8, 6))
plt.plot(losses)
plt.xlabel('Step')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.grid(True)
plt.show()
4. Data Parallel Training with Flax NNX
While JAX has its own advantages, it is often too low level of an API when implementing neural networks. For people familiar with PyTorch, the JAX ecosystem offers Flax - a neural network modelling library with an API much more similar to that offered by PyTorch. Let’s implement the same 8-way data parallel training using the Flax NNX API, which provides higher-level abstractions.
4.1 Import Flax
We need to import (or install) the flax library, which provides a high-level API for building neural networks in JAX called nnx (analogous to torch.nn API in PyTorch).
[3]:
# Import Flax NNX
try:
import flax.nnx as nnx
import optax
except ImportError:
!pip install -q flax optax
import flax.nnx as nnx
import optax
4.2 Define Model using Flax NNX API
We define our two layer model as before, but using the flax nnx.Module API.
[42]:
class MLP(nnx.Module):
def __init__(self, din, dmid, dout, *, rngs: nnx.Rngs):
self.linear1 = nnx.Linear(din, dmid, rngs=rngs)
self.linear2 = nnx.Linear(dmid, dout, rngs=rngs)
def __call__(self, x):
x = nnx.relu(self.linear1(x))
return self.linear2(x)
4.3 Replicate Model and Optimizer State across devices
We replicated the model and optimizer state across the replicated sharding we defined earlier.
[43]:
model = MLP(128, 2048, 128, rngs=nnx.Rngs(0))
optimizer = nnx.Optimizer(model, optax.adamw(1e-2))
# replicate model and optimizer states across shards
state = nnx.state((model, optimizer))
state = jax.device_put(state, replicated_sharding)
nnx.update((model, optimizer), state)
[44]:
# visualize model sharding
print('model sharding')
jax.debug.visualize_array_sharding(model.linear1.kernel.value)
model sharding
TPU 0,1,2,3,4,5,6,7
4.4 Define Train Step
Simple MSE loss
[45]:
@nnx.jit
def train_step(model: MLP, optimizer: nnx.Optimizer, x, y):
def loss_fn(model: MLP):
y_pred = model(x)
return jnp.mean((y - y_pred) ** 2)
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grads)
return loss
4.5 Distributed Training
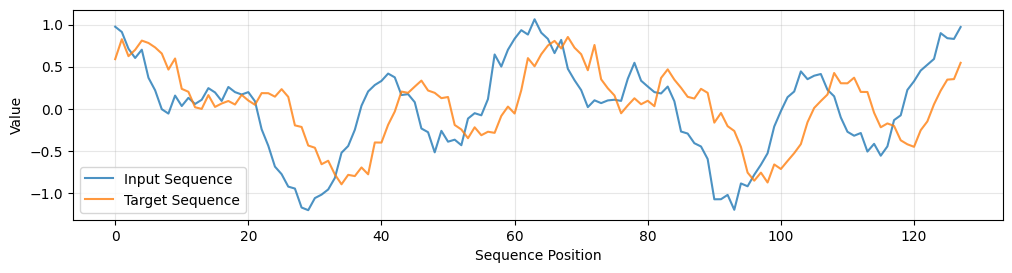
In order to simulate sequence modelling, we will use a synthetic dataset of sequences which are random weighted sums of periodic functions (sin and cosine).
[46]:
def dataset(steps, batch_size):
"""Generate 128D sequence data with underlying pattern."""
for _ in range(steps):
# Generate input sequences
# Create a pattern where the output is a transformed version of input
# First few dimensions have strong pattern, rest have weaker signal
# Generate base signal
t = np.linspace(0, 4*np.pi, 128)
base_patterns = np.array([
np.sin(t + np.random.uniform(0, 2*np.pi)),
np.cos(2*t + np.random.uniform(0, 2*np.pi)),
np.sin(3*t + np.random.uniform(0, 2*np.pi))
])
# Create batch of sequences
x = np.zeros((batch_size, 128))
y = np.zeros((batch_size, 128))
for i in range(batch_size):
# Mix base patterns with random weights
weights = np.random.randn(3)
signal = np.sum(weights[:, np.newaxis] * base_patterns, axis=0)
# Add noise
x[i] = signal + np.random.normal(0, 0.1, 128)
# Output is a non-linear transformation of input
# Shift and apply non-linear transformation
y[i] = np.roll(x[i], 5) * 0.8 + 0.1 * x[i]**2
y[i] += np.random.normal(0, 0.05, 128)
yield x.astype(np.float32), y.astype(np.float32)
We can visualize a sample from the dataset to see what it looks like.
[47]:
x, y = next(dataset(1, 1))
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(x[0], label='Input Sequence', alpha=0.8)
plt.plot(y[0], label='Target Sequence', alpha=0.8)
plt.xlabel('Sequence Position')
plt.ylabel('Value')
plt.legend()
plt.grid(True, alpha=0.3)
[48]:
# Training parameters
batch_size = 8192
num_steps = 501
losses = []
[49]:
# The training loop will be a bit slow (in actual wall clock time) since the dataset is generating samples for each step on the fly
# It is not slow due to using FSDP 😅
for step, (x, y) in enumerate(dataset(num_steps, batch_size)):
# shard data
x, y = jax.device_put((x, y), batch_sharding)
# train
loss = train_step(model, optimizer, x, y)
losses.append(float(loss))
if step == 0:
print('data sharding')
jax.debug.visualize_array_sharding(x)
if step % 100 == 0:
print(f'step={step}, loss={loss}')
data sharding
TPU 0 TPU 1 TPU 2 TPU 3 TPU 6 TPU 7 TPU 4 TPU 5
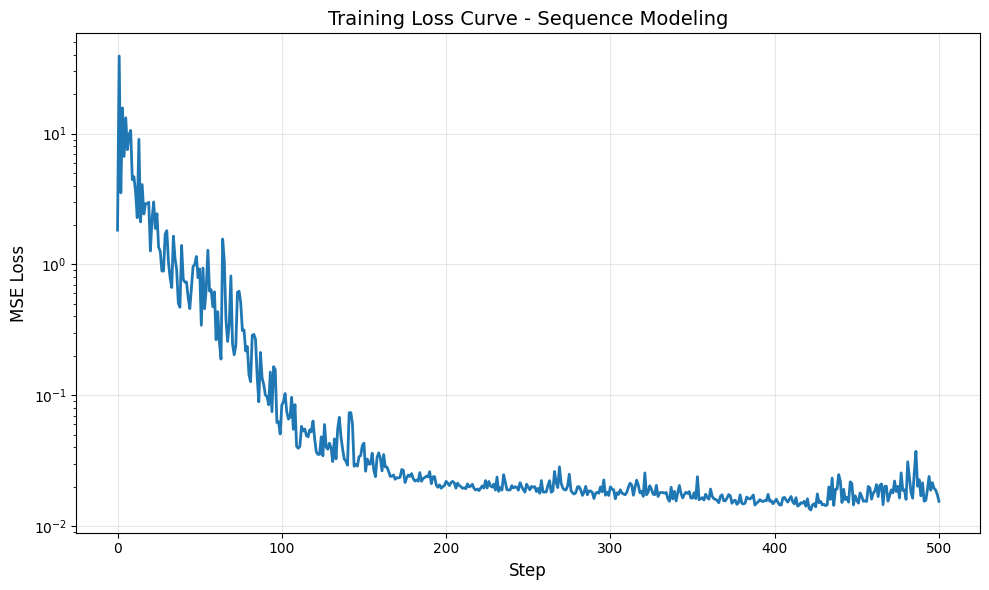
step=0, loss=1.8279016017913818
step=100, loss=0.08409085869789124
step=200, loss=0.021983487531542778
step=300, loss=0.01996900513768196
step=400, loss=0.015401830896735191
step=500, loss=0.015486905351281166
[50]:
# dereplicate state
state = nnx.state((model, optimizer))
state = jax.device_get(state)
nnx.update((model, optimizer), state)
We can now visualize the training loss curve, as well as the sequence model learned by our data parallel training.
[51]:
# Plot loss curve
plt.figure(figsize=(10, 6))
plt.plot(losses, linewidth=2)
plt.xlabel('Step', fontsize=12)
plt.ylabel('MSE Loss', fontsize=12)
plt.title('Training Loss Curve - Sequence Modeling', fontsize=14)
plt.grid(True, alpha=0.3)
plt.yscale('log') # Log scale to better see the decrease
plt.tight_layout()
plt.show()
[52]:
x_test, y_test = next(dataset(1, 1))
y_pred = model(x_test)
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(x_test[0], label='Input Sequence', alpha=0.8)
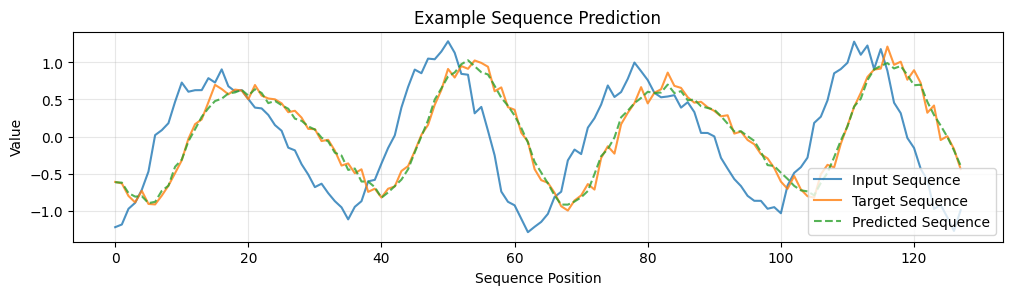
plt.plot(y_test[0], label='Target Sequence', alpha=0.8)
plt.plot(y_pred[0], label='Predicted Sequence', linestyle='--', alpha=0.8)
plt.xlabel('Sequence Position')
plt.ylabel('Value')
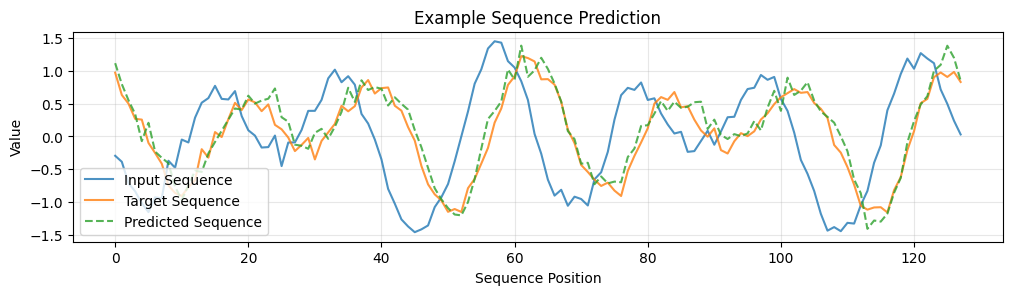
plt.title('Example Sequence Prediction')
plt.legend()
plt.grid(True, alpha=0.3)
5. Fully Sharded Data Parallelism (FSDP)
5.1 What limits Data Parallelism?
Data Parallelism involves a lot of duplicated work. Once each device AllReduces the gradients, each device updates:
full optimzer state (duplicated across all devices)
full parameter update for the model (duplicated across all devices)
5.2 ZeRO (Zero Redundancy Optimizer)
The paper ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (linked below) the memory optimizations by sharding not just the data along the batch axis, but also sharding the optimizer states (e.g. momentum vector), gradients, as well as the parameters.
The rows below show the memory consumption of:
Pure Data Parallelism: Parameters and optimizer states fully replicated
ZeRO-1: Optimizer states sharded
ZeRO-2: Optimizer states and gradients sharded
ZeRO-3: Parameters, gradients, and optimizer states all sharded

Image Source: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
5.3 FSDP Theory
Definition: ZeRO-3 is also known as Fully Sharded Data Parallel since activations, weights, and optimizer states are sharded along batch dimension. Weights are gathered just-in-time before use.
Mathematical representation:
where both batch and weight dimensions are sharded across \(X\) devices.

Image Source: How To Scale Your Model
5.3 FSDP Algorithm
As mentioned earlier, data parallelism involves a lot of duplicated work. Fully Sharded Data Parallelism (FSDP) addresses this by sharding the model weights and activations across devices. Instead of using AllReduce to communicate the full model weights and optimizer states, FSDP splits the AllReduce operation into two steps: AllGather and ReduceScatter. See the previous tutorial on how this is mathematically equivalent.
Splitting the collective allows us to gather the weights from all devices just-in-time before use, and scatter the gradients back to each device after the backward pass. While this adds extra communication during the forward pass compared to data parallelism, but its in proportion to the reduction in comms during the backward pass - so the overall communication cost is same.
Forward pass:
Win[D, F] = AllGather(Win[DX, F]) (not on critical path, can do it during previous layer)
Tmp[BX, F] = In[BX, D] *D Win[D, F] (can throw away Win[D, F] now)
Wout[F, D] = AllGather(Wout[F, DX]) (not on critical path, can do it during previous layer)
Out[BX, D] = Tmp[BX, F] *F Wout[F, D]
Loss[BX] = …
Backward pass:
dOut[BX, D] = …
dWout[F, D] {UX} = Tmp[BX, F] *B dOut[BX, D]
dWout[F, DX] = ReduceScatter(dWout[F, D] {UX}) (not on critical path, can be done async)
Wout[F, D] = AllGather(Wout[F, DX]) (can be done ahead of time)
dTmp[BX, F] = dOut[BX, D] *D Wout[F, D] (can throw away Wout[F, D] here)
dWin[D,F] {UX} = dTmp[BX, F] *B In[BX, D]
dWin[DX, F] = ReduceScatter(dWin[D, F] {UX}) (not on critical path, can be done async)
Win[D, F] = AllGather(Win[DX, F]) (can be done ahead of time)
dIn[BX, D] = dTmp[BX, F] *F Win[D, F] (needed for previous layers) (can throw away Win[D, F] here)
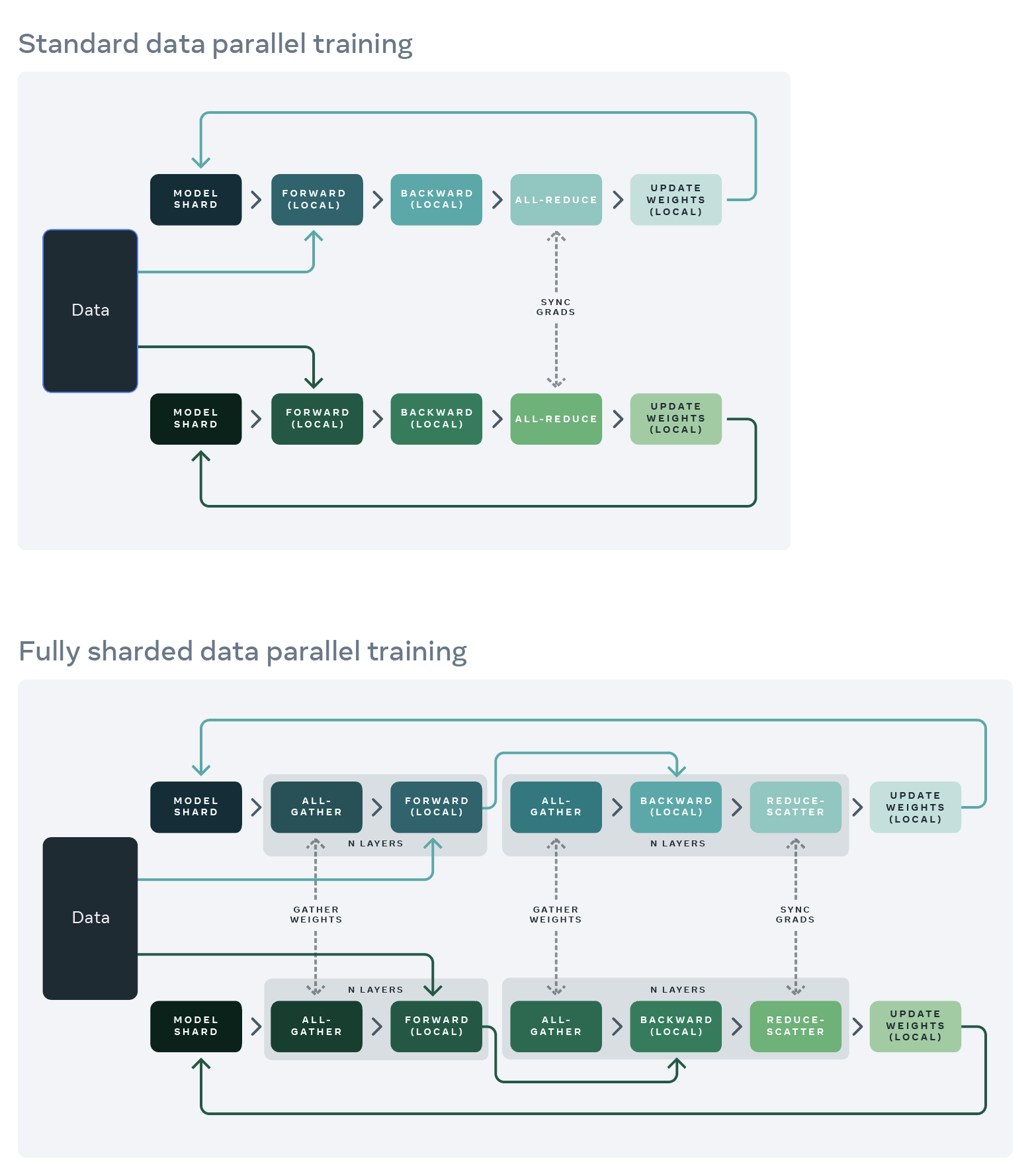
Image Source: FB Engineering Blog
5.5 FSDP Compute versus Communication Bound
Communication Analysis:
FSDP has the same roofline as pure data parallelism because:
AllReduce = AllGather + ReduceScatter
Total communication volume is identical
Same condition: \(\frac{B}{X} > \frac{C}{W_{\text{ici}}} = 2550\)
6. Fully Sharded Data Parallel (FSDP) Training with Flax NNX
Now let’s implement FSDP using the Flax NNX API.
6.1 Mesh and Sharding
[4]:
# Create a 1D mesh for FSDP
fsdp_mesh = jax.sharding.Mesh(
mesh_utils.create_device_mesh((8,)), # 1D mesh
('fsdp',) # Single axis for FSDP
)
[5]:
# A helper function to quickly create a NamedSharding object
# using the globally defined 'mesh'.
def named_sharding(*names: str | None) -> NamedSharding:
return NamedSharding(fsdp_mesh, P(*names))
[6]:
# A dataclass to hold sharding rules for different parts of the model/data.
# Makes it easy to manage and change sharding strategies.
@dataclasses.dataclass(unsafe_hash=True)
class FSDPRules:
"""Rules for FSDP sharding - all parameters sharded along the same axis"""
weight_0: str | None = 'fsdp' # Shard first dimension of weights
weight_1: str | None = None # Don't shard second dimension
bias: str | None = None # Don't shard biases (they're small)
data: str | None = 'fsdp' # Shard data along batch dimension
def __call__(self, *keys: str) -> tuple[str, ...]:
return tuple(getattr(self, key) for key in keys)
fsdp_rules = FSDPRules()
6.2 Build the Sharded Model
We can pass the sharding rule corresponding to the mesh we created earlier as parameters to various layer init functions in flax to tell the JAX compiler how to shard those layers.
[10]:
class MLP(nnx.Module):
def __init__(self, din, dmid, dout, *, rngs: nnx.Rngs):
# Create Linear layers with custom initialization that includes sharding
self.linear1 = nnx.Linear(
din, dmid,
kernel_init=nnx.with_metadata(
nnx.initializers.lecun_normal(),
sharding=fsdp_rules('weight_0', 'weight_1') # ('fsdp', None)
),
bias_init=nnx.with_metadata(
nnx.initializers.zeros_init(),
sharding=fsdp_rules('bias') # (None,)
),
rngs=rngs
)
self.linear2 = nnx.Linear(
dmid, dout,
kernel_init=nnx.with_metadata(
nnx.initializers.lecun_normal(),
sharding=fsdp_rules('weight_0', 'weight_1') # ('fsdp', None)
),
bias_init=nnx.with_metadata(
nnx.initializers.zeros_init(),
sharding=fsdp_rules('bias') # (None,)
),
rngs=rngs
)
def __call__(self, x):
x = nnx.relu(self.linear1(x))
return self.linear2(x)
6.2 Build the Sharded Optimizer
[11]:
# Define a custom type for SGD momentum state, inheriting from nnx.Variable.
# This allows it to be tracked as part of the NNX state tree.
class SGDState(nnx.Variable):
pass
# Define the SGD optimizer using NNX API.
class SGD(nnx.Object):
# Constructor takes the model parameters (as nnx.State), learning rate, and decay.
def __init__(self, params: nnx.State, lr, decay=0.9):
# Helper function to initialize momentum buffer for a given parameter.
def init_optimizer_state(variable: nnx.Variable):
# Create momentum state with zeros, same shape and metadata (incl. sharding)
# as the parameter it corresponds to.
return SGDState(
jnp.zeros_like(variable.value), **variable.get_metadata()
)
self.lr = lr
# Store a reference to the parameter State tree.
self.params = params
# Create the momentum state tree, mirroring the structure of 'params',
# using the helper function. Momentum will have the same sharding as params.
self.momentum = jax.tree.map(init_optimizer_state, self.params)
self.decay = decay
# Method to update parameters based on gradients.
def update(self, grads: nnx.State):
# Define the update logic for a single parameter/momentum/gradient triple.
def update_fn(
params: nnx.Variable, momentum: SGDState, grad: nnx.VariableState
):
# Standard SGD with momentum update rule.
# v_t = β * v_{t-1} + (1 - β) * ∇J(θ_t)
momentum.value = self.decay * momentum.value + (1 - self.decay) * grad.value
# θ_{t+1} = θ_t - α * v_t
params.value -= self.lr * momentum.value # NOTE: Direct mutation of param value!
# Apply the update function across the parameter, momentum, and gradient trees.
# This performs the update in-place on the parameter values referenced by self.params.
jax.tree.map(update_fn, self.params, self.momentum, grads)
6.3 Enforce Sharding in Model and Optimizer States
[13]:
# JIT-compile the model and optimizer creation function.
@nnx.jit
def create_model():
# Instantiate the MLP model. rngs=nnx.Rngs(0) provides PRNG keys.
model = MLP(128, 2048, 128, rngs=nnx.Rngs(0))
# Create the optimizer. nnx.variables(model, nnx.Param) extracts
# only the nnx.Param state variables from the model object.
optimizer = SGD(nnx.variables(model, nnx.Param), 0.01, decay=0.9)
# === Explicit Sharding Application ===
# 1. Extract ALL state (model params + optimizer momentum) into a flat State pytree.
state = nnx.state(optimizer)
# 2. Define the target sharding for the state pytree.
# This function maps state paths to NamedSharding objects based on stored metadata.
def get_named_shardings(path: tuple, value: nnx.VariableState):
# Assumes params and momentum use the sharding defined in their metadata.
if path[0] == 'params':
# value.sharding contains the tuple like ('model',) or (None, 'model')
return value.replace(NamedSharding(fsdp_mesh, P(*value.sharding)))
elif path[0] == 'momentum':
# Momentum states have the same sharding as their corresponding parameters
return value.replace(NamedSharding(fsdp_mesh, P(*value.sharding)))
else:
# Handle other state if necessary (e.g., learning rate if it were a Variable)
raise ValueError(f'Unknown path: {path}')
# Create the pytree of NamedSharding objects.
named_shardings = state.map(get_named_shardings)
# 3. Apply sharding constraint. This tells JAX how the 'state' pytree
# SHOULD be sharded when computations involving it are run under jit/pjit.
# It doesn't immediately move data but sets up the constraint for the compiler.
sharded_state = jax.lax.with_sharding_constraint(state, named_shardings)
# 4. Update the original objects (model params, optimizer momentum)
# with the constrained state values. This step makes the sharding
# "stick" to the objects themselves for subsequent use outside this function.
nnx.update(optimizer, sharded_state)
# Return the model and optimizer objects, now containing sharded state variables.
return model, optimizer
# Call the function to create the sharded model and optimizer.
model, optimizer = create_model()
# Visualize sharding - now using the Linear layer's kernel parameters
print("Linear 1 kernel sharding:")
jax.debug.visualize_array_sharding(model.linear1.kernel.value)
print("\nLinear 2 kernel sharding:")
jax.debug.visualize_array_sharding(model.linear2.kernel.value)
print("\nLinear 1 kernel momentum state sharding:")
jax.debug.visualize_array_sharding(optimizer.momentum.linear1.kernel.value)
Linear 1 kernel sharding:
TPU 0 TPU 1 TPU 2 TPU 3 TPU 6 TPU 7 TPU 4 TPU 5
Linear 2 kernel sharding:
TPU 0 TPU 1 TPU 2 TPU 3 TPU 6 TPU 7 TPU 4 TPU 5
Linear 1 kernel momentum sharding:
TPU 0 TPU 1 TPU 2 TPU 3 TPU 6 TPU 7 TPU 4 TPU 5
6.4 Distributed Training
[14]:
# JIT-compile the training step function (same as before)
@nnx.jit
def train_step(model: MLP, optimizer: SGD, x, y):
def loss_fn(model):
y_pred = model(x)
loss = jnp.mean((y - y_pred) ** 2)
return loss
# Calculate loss and gradients w.r.t the model's state (its nnx.Param variables).
# 'grad' will be an nnx.State object mirroring model's Param structure.
loss, grad = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grad)
return loss
[15]:
def dataset(steps, batch_size):
"""Generate 128D sequence data with underlying pattern."""
for _ in range(steps):
# Generate input sequences
# Create a pattern where the output is a transformed version of input
# First few dimensions have strong pattern, rest have weaker signal
# Generate base signal
t = np.linspace(0, 4*np.pi, 128)
base_patterns = np.array([
np.sin(t + np.random.uniform(0, 2*np.pi)),
np.cos(2*t + np.random.uniform(0, 2*np.pi)),
np.sin(3*t + np.random.uniform(0, 2*np.pi))
])
# Create batch of sequences
x = np.zeros((batch_size, 128))
y = np.zeros((batch_size, 128))
for i in range(batch_size):
# Mix base patterns with random weights
weights = np.random.randn(3)
signal = np.sum(weights[:, np.newaxis] * base_patterns, axis=0)
# Add noise
x[i] = signal + np.random.normal(0, 0.1, 128)
# Output is a non-linear transformation of input
# Shift and apply non-linear transformation
y[i] = np.roll(x[i], 5) * 0.8 + 0.1 * x[i]**2
y[i] += np.random.normal(0, 0.05, 128)
yield x.astype(np.float32), y.astype(np.float32)
[16]:
# --- Training Loop ---
losses = [] # To store loss values for plotting
# Iterate through the dataset generator for 10,000 steps.
for step, (x_batch, y_batch) in enumerate(
dataset(batch_size=8192, steps=501)
):
# CRITICAL: Place the NumPy data onto JAX devices AND apply sharding.
# named_sharding('data') -> Shard along the 'data' mesh axis (first dim, size 2).
# Each device along the 'data' axis gets a slice of the batch.
x_batch, y_batch = jax.device_put((x_batch, y_batch), named_sharding('fsdp'))
# Execute the JIT-compiled training step with the sharded model, optimizer, and data.
loss = train_step(model, optimizer, x_batch, y_batch)
# Record the loss (move scalar loss back to host CPU).
losses.append(float(loss))
# Log progress periodically.
if step % 100 == 0:
print(f'Step {step}: Loss = {loss}')
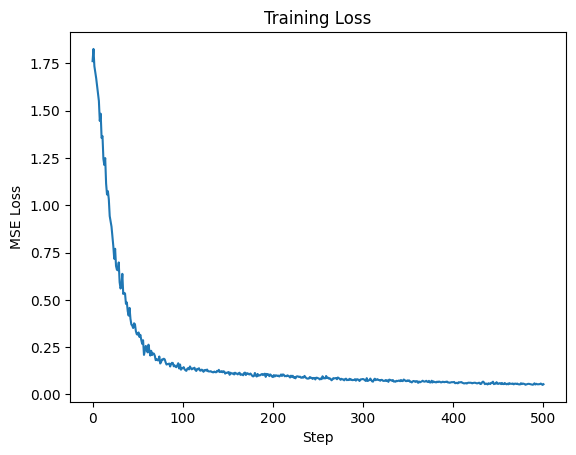
Step 0: Loss = 1.761734962463379
Step 100: Loss = 0.13825155794620514
Step 200: Loss = 0.09147088974714279
Step 300: Loss = 0.0810324028134346
Step 400: Loss = 0.06444019079208374
Step 500: Loss = 0.05355063080787659
[17]:
# --- Plotting Results ---
plt.figure()
plt.title("Training Loss")
plt.plot(losses)
plt.xlabel("Step")
plt.ylabel("MSE Loss")
[17]:
Text(0, 0.5, 'MSE Loss')
[18]:
x_test, y_test = next(dataset(1, 1))
y_pred = model(x_test)
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(x_test[0], label='Input Sequence', alpha=0.8)
plt.plot(y_test[0], label='Target Sequence', alpha=0.8)
plt.plot(y_pred[0], label='Predicted Sequence', linestyle='--', alpha=0.8)
plt.xlabel('Sequence Position')
plt.ylabel('Value')
plt.title('Example Sequence Prediction')
plt.legend()
plt.grid(True, alpha=0.3)