{
"cells": [
{
"cell_type": "markdown",
"id": "17be077e",
"metadata": {
"id": "17be077e"
},
"source": [
"# Tutorial 3: Tensor Parallel and Transformers Scaling\n",
"\n",
"[](https://github.com/sshkhr/MinText/blob/main/docs/tutorials/3_Tensor_Parallel_and_Transformers.ipynb)\n",
"[](https://colab.research.google.com/github/sshkhr/MinText/blob/main/docs/tutorials/3_Tensor_Parallel_and_Transformers.ipynb)"
]
},
{
"cell_type": "markdown",
"id": "47d7d9d3",
"metadata": {
"id": "47d7d9d3"
},
"source": [
"In the previous tutorial, we learned about data parallelism and how to use it to shard data batches across devices. We also learned about Fully Sharded Data Parallel (FSDP) and how it can be used to shard model parameters, gradients and optimizer states across devices. In this part, we will cover tensor parallelism and how it can be used to shard model layers across devices. We will also learn how to use the different parallelism techniques together to scale up training of an actual transformer model."
]
},
{
"cell_type": "markdown",
"id": "992ec8d3",
"metadata": {
"id": "992ec8d3"
},
"source": [
"## 0. Setup\n",
"\n",
"Let's start by importing the necessary libraries and initializing our environment."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "bd37fc51",
"metadata": {
"id": "bd37fc51"
},
"outputs": [],
"source": [
"import os\n",
"# Force JAX to see 8 devices for this tutorial (only use if not using TPU runtime)\n",
"#os.environ['XLA_FLAGS'] = '--xla_force_host_platform_device_count=8'\n",
"\n",
"import jax\n",
"import jax.numpy as jnp\n",
"from jax.sharding import Mesh, PartitionSpec as P, NamedSharding\n",
"from jax.experimental import mesh_utils\n",
"from flax import nnx\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import time\n",
"from functools import partial\n",
"import dataclasses\n",
"\n",
"import optax"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "ea947ba6",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "ea947ba6",
"outputId": "3b056705-36ea-4bb3-ed1a-a7770c36ec3d"
},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"JAX version: 0.5.2\n",
"Available devices: [TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0), TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1), TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0), TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1)]...\n",
"Number of devices: 8\n"
]
}
],
"source": [
"# Check available devices\n",
"print(f\"JAX version: {jax.__version__}\")\n",
"print(f\"Available devices: {jax.devices()[:4]}...\")\n",
"print(f\"Number of devices: {jax.device_count()}\")"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "nm_GcLiSWxbx",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "nm_GcLiSWxbx",
"outputId": "7967fad5-fecf-4c5d-d817-7a289a663cd8"
},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/1.2 MB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[91m━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[90m╺\u001b[0m\u001b[90m━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.7/1.2 MB\u001b[0m \u001b[31m22.2 MB/s\u001b[0m eta \u001b[36m0:00:01\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m1.2/1.2 MB\u001b[0m \u001b[31m21.3 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
"\u001b[?25h\u001b[?25l \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m0.0/485.5 kB\u001b[0m \u001b[31m?\u001b[0m eta \u001b[36m-:--:--\u001b[0m\r\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m485.5/485.5 kB\u001b[0m \u001b[31m35.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
"\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m8.6/8.6 MB\u001b[0m \u001b[31m127.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
"\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m65.3/65.3 kB\u001b[0m \u001b[31m6.4 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
"\u001b[?25h"
]
}
],
"source": [
"# Requirements for Language Modelling\n",
"!pip install -Uq tiktoken grain matplotlib"
]
},
{
"cell_type": "markdown",
"id": "425d3061",
"metadata": {
"id": "425d3061"
},
"source": [
"## 1. Tensor Parallelism\n",
"\n",
"While fully-sharded data parallelism distributes model weights across different devices during the AllReduce operation, tensor parallelism takes a different approach. Also known as \"1D model parallelism\" or Megatron sharding, this technique shards the feedforward dimensions of individual model layers and distributes activations between devices during computation. This method enables smaller effective batch sizes per device, making it particularly useful for training very large models. The diagram below illustrates how a single matrix is partitioned across devices using this approach:"
]
},
{
"cell_type": "markdown",
"id": "7c76edab",
"metadata": {
"id": "7c76edab"
},
"source": [
"### 1.1 Tensor Parallelism Theory\n",
"\n",
"**Sharding**: Model layer activations are sharded along tensor axes across devices, model parameters are replicated on each device.\n",
"\n",
"**Equation** (for our MLP example):\n",
"$$\\text{In}[B, D_Y] \\cdot_D W_\\text{in}[D, F_Y] \\cdot_F W_\\text{out}[F_Y, D] \\rightarrow \\text{Out}[B, D_Y]$$\n",
"\n",
"where $F_Y$ indicates the activations are sharded across $Y$ devices."
]
},
{
"cell_type": "markdown",
"id": "01006675",
"metadata": {
"id": "01006675"
},
"source": [
"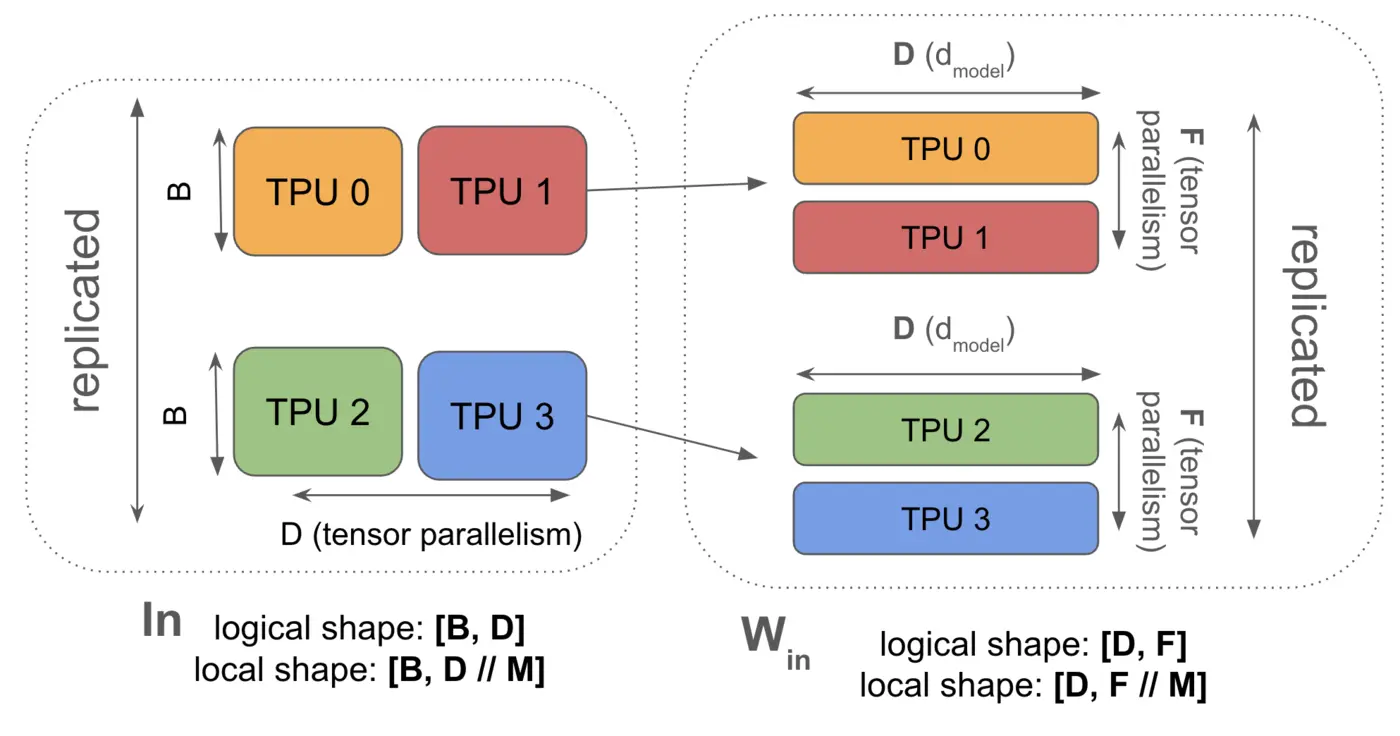"
]
},
{
"cell_type": "markdown",
"id": "2f540e70",
"metadata": {
"id": "2f540e70"
},
"source": [
" Image Source: [How To Scale Your Model](https://jax-ml.github.io/scaling-book) "
]
},
{
"cell_type": "markdown",
"id": "6a24d684",
"metadata": {
"id": "6a24d684"
},
"source": [
"### 1.2 Tensor Parallelism Algorithm\n",
"\n",
"The computation pattern In[B, D_Y] * W_in[D, F_Y] * W_out[F_Y, D] → Out[B, D_Y] requires gathering activations prior to the initial matrix multiplication. This approach becomes more efficient than ZeRO sharding when activation sizes are smaller than weight sizes.\n",
"\n",
"**Forward pass:** need to compute Loss[B]\n",
"\n",
"1. In[B, D] = **AllGather**(In[B, DY]) *(on critical path)*\n",
"2. Tmp[B, FY] = In[B, D] \\*D Win[D, FY] *(not sharded along contracting, so no comms)*\n",
"3. Out[B, D] {UY} = Tmp[B, FY] \\*F Wout[FY, D]\n",
"4. Out[B, DY] = **ReduceScatter**(Out[B, D] {UY}) *(on critical path)*\n",
"5. Loss[B] = ...\n",
"\n",
"**Backward pass:** need to compute dWout[FY, D], dWin[D, FY]\n",
"\n",
"1. dOut[B, DY] = ...\n",
"2. dOut[B, D] = **AllGather**(dOut[B, DY]) *(on critical path)*\n",
"3. dWout[FY, D] = Tmp[B, FY] \\*B dOut[B, D]\n",
"4. dTmp[B, FY] = dOut[B, D] \\*D Wout[FY, D] *(can throw away dOut[B, D] here)*\n",
"5. In[B, D] = **AllGather**(In[B, DY]) *(this can be skipped by sharing with (1) from the forward pass)*\n",
"6. dWin[D, FY] = dTmp[B, FY] \\*B In[B, D]\n",
"7. dIn[B, D] {U.Y} = dTmp[B, FY] \\*F Win[D, FY] *(needed for previous layers)*\n",
"8. dIn[B, DY] = **ReduceScatter**(dIn[B, D] {U.Y}) *(on critical path)*\n",
"\n",
"A key advantage of the two matrix operations in our MLP forward pass is that tensor parallelism integrates nicely with this setup. Without this optimization, we would need to perform an AllReduce operation after each matrix multiplication. However, the sequential computation In[B, D_Y] * W_in[D, F_Y] → Tmp[B, F_Y] followed by Tmp[B, F_Y] * W_out[F_Y, D] → Out[B, D_Y] allows us to perform a single AllGather on the input at the start and a single ReduceScatter on the output at the end, eliminating the need for intermediate AllReduce operations."
]
},
{
"cell_type": "markdown",
"id": "5334a065",
"metadata": {
"id": "5334a065"
},
"source": [
"## 2. Combining Parallelism Techniques\n",
"\n",
"In this section, we will combine FSDP, and tensor parallelism to implemnt distributed training of a simple MLP model. The efficiency from gathering activations prior to matrix multiplyin tensor parallelism typically emerges only when combined with some degree of ZeRO sharding, which reduces the gather operation's overhead. This synergy explains why ZeRO sharding and model parallelism are commonly used together in practice.\n"
]
},
{
"cell_type": "markdown",
"id": "60a857dc",
"metadata": {
"id": "60a857dc"
},
"source": [
"### 2.1 Mesh Definition"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "45ed2560",
"metadata": {
"id": "45ed2560"
},
"outputs": [],
"source": [
"# Assign logical names 'data' and 'model' to the axes of this grid.\n",
"# The first dimension (size 2) is named 'data'.\n",
"# The second dimension (size 4) is named 'model'.\n",
"mesh = jax.sharding.Mesh(\n",
" mesh_utils.create_device_mesh((2, 4)),\n",
" ('data', 'model'),\n",
")"
]
},
{
"cell_type": "markdown",
"id": "9ce31aa1",
"metadata": {
"id": "9ce31aa1"
},
"source": [
"### 2.2 Sharding Helper Functions"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "5d266bc6",
"metadata": {
"id": "5d266bc6"
},
"outputs": [],
"source": [
"# A helper function to quickly create a NamedSharding object\n",
"# using the globally defined 'mesh'.\n",
"def named_sharding(*names: str | None) -> NamedSharding:\n",
" # P(*names) creates a PartitionSpec, e.g., P('data', None)\n",
" # NamedSharding binds this PartitionSpec to the 'mesh'.\n",
" return NamedSharding(mesh, P(*names))\n",
"\n",
"\n",
"@dataclasses.dataclass(unsafe_hash=True)\n",
"class MeshRules:\n",
" \"\"\"Rules for combined FSDP (data parallel) + tensor parallel sharding\"\"\"\n",
" weight_0: str | None = None # First dimension of weights\n",
" weight_1: str | None = 'model' # Second dimension of weights (tensor parallel)\n",
" bias: str | None = 'model' # Bias sharded along model axis\n",
" data: str | None = 'data' # Data sharded along data axis\n",
"\n",
" def __call__(self, *keys: str) -> tuple[str, ...]:\n",
" return tuple(getattr(self, key) for key in keys)\n",
"\n",
"mesh_rules = MeshRules()"
]
},
{
"cell_type": "markdown",
"id": "8f6e98b3",
"metadata": {
"id": "8f6e98b3"
},
"source": [
"### 2.3 Define The Sharded Model"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "31970b77",
"metadata": {
"id": "31970b77"
},
"outputs": [],
"source": [
"# Modified MLP using nnx.Linear with tensor parallelism\n",
"class MLP(nnx.Module):\n",
" def __init__(self, din, dmid, dout, *, rngs: nnx.Rngs):\n",
" # For linear1: (128, 2048) -> shard second dimension\n",
" self.linear1 = nnx.Linear(\n",
" din, dmid,\n",
" kernel_init=nnx.with_metadata(\n",
" nnx.initializers.lecun_normal(),\n",
" sharding=mesh_rules('weight_0', 'weight_1') # (None, 'model')\n",
" ),\n",
" bias_init=nnx.with_metadata(\n",
" nnx.initializers.zeros_init(),\n",
" sharding=mesh_rules('bias') # ('model',)\n",
" ),\n",
" rngs=rngs\n",
" )\n",
"\n",
" # For linear2: (2048, 128) -> shard first dimension\n",
" self.linear2 = nnx.Linear(\n",
" dmid, dout,\n",
" kernel_init=nnx.with_metadata(\n",
" nnx.initializers.lecun_normal(),\n",
" sharding=('model', None) # Custom sharding for this layer\n",
" ),\n",
" bias_init=nnx.with_metadata(\n",
" nnx.initializers.zeros_init(),\n",
" sharding=(None,) # Don't shard output bias\n",
" ),\n",
" rngs=rngs\n",
" )\n",
"\n",
" def __call__(self, x):\n",
" x = nnx.relu(self.linear1(x))\n",
" return self.linear2(x)"
]
},
{
"cell_type": "markdown",
"id": "06d184b8",
"metadata": {
"id": "06d184b8"
},
"source": [
"### 2.4 Handling Sharded Optimizer State"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "1d9f4258",
"metadata": {
"id": "1d9f4258"
},
"outputs": [],
"source": [
"# Define a custom type for SGD momentum state, inheriting from nnx.Variable.\n",
"# This allows it to be tracked as part of the NNX state tree.\n",
"class SGDState(nnx.Variable):\n",
" pass\n",
"\n",
"# Define the SGD optimizer using NNX API.\n",
"class SGD(nnx.Object):\n",
" # Constructor takes the model parameters (as nnx.State), learning rate, and decay.\n",
" def __init__(self, params: nnx.State, lr, decay=0.9):\n",
" # Helper function to initialize momentum buffer for a given parameter.\n",
" def init_optimizer_state(variable: nnx.Variable):\n",
" # Create momentum state with zeros, same shape and metadata (incl. sharding)\n",
" # as the parameter it corresponds to.\n",
" return SGDState(\n",
" jnp.zeros_like(variable.value), **variable.get_metadata()\n",
" )\n",
"\n",
" self.lr = lr\n",
" # Store a reference to the parameter State tree.\n",
" self.params = params\n",
" # Create the momentum state tree, mirroring the structure of 'params',\n",
" # using the helper function. Momentum will have the same sharding as params.\n",
" self.momentum = jax.tree.map(init_optimizer_state, self.params)\n",
" self.decay = decay\n",
"\n",
" # Method to update parameters based on gradients.\n",
" def update(self, grads: nnx.State):\n",
" # Define the update logic for a single parameter/momentum/gradient triple.\n",
" def update_fn(\n",
" params: nnx.Variable, momentum: SGDState, grad: nnx.VariableState\n",
" ):\n",
" # Standard SGD with momentum update rule.\n",
" # v_t = β * v_{t-1} + (1 - β) * ∇J(θ_t)\n",
" momentum.value = self.decay * momentum.value + (1 - self.decay) * grad.value\n",
" # θ_{t+1} = θ_t - α * v_t\n",
" params.value -= self.lr * momentum.value # NOTE: Direct mutation of param value!\n",
"\n",
" # Apply the update function across the parameter, momentum, and gradient trees.\n",
" # This performs the update in-place on the parameter values referenced by self.params.\n",
" jax.tree.map(update_fn, self.params, self.momentum, grads)\n"
]
},
{
"cell_type": "markdown",
"id": "850d7981",
"metadata": {
"id": "850d7981"
},
"source": [
"### 2.5 Applying Sharding to the Model and Optimizer"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "3f54c41e",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 434
},
"id": "3f54c41e",
"outputId": "3100ce64-0cd4-4c5c-ff23-c0bfe3d7beb0"
},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Linear1 kernel sharding (128, 2048):\n"
]
},
{
"output_type": "display_data",
"data": {
"text/plain": [
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n"
],
"text/html": [
" \n",
" \n",
" \n",
" \n",
" \n",
" \n",
" \n",
" \n",
" \n",
" \n",
"\n"
]
},
"metadata": {}
},
{
"output_type": "stream",
"name": "stdout",
"text": [
"\n",
"Linear2 kernel sharding (2048, 128):\n"
]
},
{
"output_type": "display_data",
"data": {
"text/plain": [
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\u001b[38;2;255;255;255;48;2;57;59;121mTPU 0,6\u001b[0m\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;57;59;121m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214mTPU 1,7\u001b[0m\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;222;158;214m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74mTPU 2,4\u001b[0m\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\n",
"\u001b[38;2;255;255;255;48;2;173;73;74m \u001b[0m\n",
"\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107mTPU 3,5\u001b[0m\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n",
"\u001b[38;2;0;0;0;48;2;181;207;107m \u001b[0m\n"
],
"text/html": [
" \n",
" TPU 0,6 \n",
" \n",
" \n",
" TPU 1,7 \n",
" \n",
" \n",
" TPU 2,4 \n",
" \n",
" \n",
" TPU 3,5 \n",
" \n",
"\n"
]
},
"metadata": {}
}
],
"source": [
"@nnx.jit\n",
"def create_model():\n",
" model = MLP(128, 2048, 128, rngs=nnx.Rngs(0))\n",
" optimizer = SGD(nnx.variables(model, nnx.Param), 0.01, decay=0.9)\n",
"\n",
" # Extract state\n",
" state = nnx.state(optimizer)\n",
"\n",
" # Define sharding for the state pytree\n",
" def get_named_shardings(path: tuple, value: nnx.VariableState):\n",
" if path[0] == 'params':\n",
" return value.replace(NamedSharding(mesh, P(*value.sharding)))\n",
" elif path[0] == 'momentum':\n",
" return value.replace(NamedSharding(mesh, P(*value.sharding)))\n",
" else:\n",
" raise ValueError(f'Unknown path: {path}')\n",
"\n",
" named_shardings = state.map(get_named_shardings)\n",
" sharded_state = jax.lax.with_sharding_constraint(state, named_shardings)\n",
" nnx.update(optimizer, sharded_state)\n",
"\n",
" return model, optimizer\n",
"\n",
"model, optimizer = create_model()\n",
"\n",
"# Visualize sharding\n",
"print(\"Linear1 kernel sharding (128, 2048):\")\n",
"jax.debug.visualize_array_sharding(model.linear1.kernel.value)\n",
"print(\"\\nLinear2 kernel sharding (2048, 128):\")\n",
"jax.debug.visualize_array_sharding(model.linear2.kernel.value)"
]
},
{
"cell_type": "markdown",
"id": "0bcf251c",
"metadata": {
"id": "0bcf251c"
},
"source": [
"### 2.6 Distributed Training"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "ca7002f6",
"metadata": {
"id": "ca7002f6"
},
"outputs": [],
"source": [
"# JIT-compile the training step function.\n",
"@nnx.jit\n",
"def train_step(model: MLP, optimizer: SGD, x, y):\n",
" # Define the loss function (Mean Squared Error).\n",
" # Takes the model object as input, consistent with nnx.value_and_grad.\n",
" def loss_fn(model):\n",
" y_pred = model(x) # Forward pass\n",
" loss = jnp.mean((y - y_pred) ** 2)\n",
" return loss\n",
"\n",
" # Calculate loss and gradients w.r.t the model's state (its nnx.Param variables).\n",
" # 'grad' will be an nnx.State object mirroring model's Param structure.\n",
" loss, grad = nnx.value_and_grad(loss_fn)(model)\n",
"\n",
" # Call the optimizer's update method to apply gradients.\n",
" # This updates the model parameters in-place.\n",
" optimizer.update(grad)\n",
"\n",
" # Return the calculated loss.\n",
" return loss\n"
]
},
{
"cell_type": "markdown",
"id": "7296dd13",
"metadata": {
"id": "7296dd13"
},
"source": [
"### 2.7 Training Loop and Results"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "ba4d14ce",
"metadata": {
"id": "ba4d14ce"
},
"outputs": [],
"source": [
"# Dataset function (as before)\n",
"def dataset(steps, batch_size):\n",
" \"\"\"Generate 128D sequence data with underlying pattern.\"\"\"\n",
" for _ in range(steps):\n",
" # Generate base signal\n",
" t = np.linspace(0, 4*np.pi, 128)\n",
" base_patterns = np.array([\n",
" np.sin(t + np.random.uniform(0, 2*np.pi)),\n",
" np.cos(2*t + np.random.uniform(0, 2*np.pi)),\n",
" np.sin(3*t + np.random.uniform(0, 2*np.pi))\n",
" ])\n",
"\n",
" # Create batch of sequences\n",
" x = np.zeros((batch_size, 128))\n",
" y = np.zeros((batch_size, 128))\n",
"\n",
" for i in range(batch_size):\n",
" # Mix base patterns with random weights\n",
" weights = np.random.randn(3)\n",
" signal = np.sum(weights[:, np.newaxis] * base_patterns, axis=0)\n",
"\n",
" # Add noise\n",
" x[i] = signal + np.random.normal(0, 0.1, 128)\n",
"\n",
" # Output is a non-linear transformation of input\n",
" y[i] = np.roll(x[i], 5) * 0.8 + 0.1 * x[i]**2\n",
" y[i] += np.random.normal(0, 0.05, 128)\n",
"\n",
" yield x.astype(np.float32), y.astype(np.float32)\n"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "beed9e47",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "beed9e47",
"outputId": "0a46bed1-5f28-4daf-f2cc-88441a0702c3"
},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Step 0: Loss = 1.7442927360534668\n",
"Step 100: Loss = 0.13562121987342834\n",
"Step 200: Loss = 0.10096409171819687\n",
"Step 300: Loss = 0.07630820572376251\n",
"Step 400: Loss = 0.06262542307376862\n",
"Step 500: Loss = 0.05251384899020195\n"
]
}
],
"source": [
"# Training Loop\n",
"losses = []\n",
"for step, (x_batch, y_batch) in enumerate(\n",
" dataset(batch_size=8192, steps=501)\n",
"):\n",
" # Shard data along 'data' axis\n",
" x_batch, y_batch = jax.device_put((x_batch, y_batch), named_sharding('data'))\n",
"\n",
" loss = train_step(model, optimizer, x_batch, y_batch)\n",
" losses.append(float(loss))\n",
"\n",
" if step % 100 == 0:\n",
" print(f'Step {step}: Loss = {loss}')"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "7dcef594",
"metadata": {
"id": "7dcef594",
"outputId": "a406443e-480f-4462-877d-9afeef367b04",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 490
}
},
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"Text(0, 0.5, 'MSE Loss')"
]
},
"metadata": {},
"execution_count": 12
},
{
"output_type": "display_data",
"data": {
"text/plain": [
""
],
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAkAAAAHHCAYAAABXx+fLAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjAsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvlHJYcgAAAAlwSFlzAAAPYQAAD2EBqD+naQAAVZNJREFUeJzt3XtcVGX+B/DPXJgZhvv9oiAoinnBu4hl2oqhWatledlaL5VtWm1FbSvtqlntz7Ld1izLtjK0m2mZXUzTMDQLNRG83zAR5A4Cw3CZgZnz+4M4OgEKwsyZYT7v12teyznnOYfvOfhqPvs8zzlHJgiCACIiIiInIpe6ACIiIiJbYwAiIiIip8MARERERE6HAYiIiIicDgMQEREROR0GICIiInI6DEBERETkdBiAiIiIyOkwABEREZHTYQAiIsnNnTsXERER17Xvc889B5lM1rkFEVGXxwBERK2SyWRt+qSmpkpdqiTmzp0Ld3d3qcsgousg47vAiKg1H374ocXy+vXrsXPnTnzwwQcW6ydMmICgoKDr/j319fUwm81Qq9Xt3rehoQENDQ3QaDTX/fuv19y5c/HZZ59Br9fb/HcTUccopS6AiOzXfffdZ7G8b98+7Ny5s9n636upqYFWq23z73Fxcbmu+gBAqVRCqeR/yoiofTgERkQdMm7cOAwYMADp6em4+eabodVq8eyzzwIAvvzyS0yePBmhoaFQq9Xo1asXXnjhBZhMJotj/H4OUHZ2NmQyGf7973/jf//7H3r16gW1Wo0RI0bgl19+sdi3pTlAMpkMjz76KLZs2YIBAwZArVajf//+2L59e7P6U1NTMXz4cGg0GvTq1Qtvv/12p88r2rRpE4YNGwZXV1f4+/vjvvvuQ15enkWbwsJCzJs3D927d4darUZISAimTJmC7Oxssc3BgweRkJAAf39/uLq6IjIyEvfff3+n1UnkTPh/m4iow8rKyjBp0iTMnDkT9913nzgclpycDHd3dyQmJsLd3R27du3CkiVLoNPp8Morr1zzuB9//DGqqqrwl7/8BTKZDCtWrMBdd92FX3/99Zq9Rnv37sXmzZuxcOFCeHh4YNWqVZg2bRpycnLg5+cHAMjIyMDEiRMREhKCZcuWwWQy4fnnn0dAQEDHL8pvkpOTMW/ePIwYMQLLly9HUVERXnvtNfz000/IyMiAt7c3AGDatGk4fvw4HnvsMURERKC4uBg7d+5ETk6OuHzrrbciICAAixYtgre3N7Kzs7F58+ZOq5XIqQhERG30yCOPCL//z8bYsWMFAMKaNWuata+pqWm27i9/+Yug1WqFuro6cd2cOXOEHj16iMvnz58XAAh+fn7CpUuXxPVffvmlAED4+uuvxXVLly5tVhMAQaVSCVlZWeK6w4cPCwCE119/XVx3xx13CFqtVsjLyxPXnT17VlAqlc2O2ZI5c+YIbm5urW43Go1CYGCgMGDAAKG2tlZc/8033wgAhCVLlgiCIAjl5eUCAOGVV15p9VhffPGFAED45ZdfrlkXEV0bh8CIqMPUajXmzZvXbL2rq6v4c1VVFUpLSzFmzBjU1NTg1KlT1zzujBkz4OPjIy6PGTMGAPDrr79ec9/4+Hj06tVLXI6JiYGnp6e4r8lkwvfff4+pU6ciNDRUbBcVFYVJkyZd8/htcfDgQRQXF2PhwoUWk7QnT56Mvn37YuvWrQAar5NKpUJqairKy8tbPFZTT9E333yD+vr6TqmPyJkxABFRh3Xr1g0qlarZ+uPHj+POO++El5cXPD09ERAQIE6grqysvOZxw8PDLZabwlBrIeFq+zbt37RvcXExamtrERUV1axdS+uux4ULFwAA0dHRzbb17dtX3K5Wq/Hyyy9j27ZtCAoKws0334wVK1agsLBQbD927FhMmzYNy5Ytg7+/P6ZMmYL3338fBoOhU2olcjYMQETUYVf29DSpqKjA2LFjcfjwYTz//PP4+uuvsXPnTrz88ssAALPZfM3jKhSKFtcLbXh6R0f2lcITTzyBM2fOYPny5dBoNFi8eDFuuOEGZGRkAGic2P3ZZ58hLS0Njz76KPLy8nD//fdj2LBhvA2f6DowABGRVaSmpqKsrAzJycl4/PHHcfvttyM+Pt5iSEtKgYGB0Gg0yMrKaratpXXXo0ePHgCA06dPN9t2+vRpcXuTXr164amnnsKOHTtw7NgxGI1G/Oc//7FoM2rUKPzrX//CwYMH8dFHH+H48ePYsGFDp9RL5EwYgIjIKpp6YK7scTEajXjzzTelKsmCQqFAfHw8tmzZgvz8fHF9VlYWtm3b1im/Y/jw4QgMDMSaNWsshqq2bduGkydPYvLkyQAan5tUV1dnsW+vXr3g4eEh7ldeXt6s92rw4MEAwGEwouvA2+CJyCpGjx4NHx8fzJkzB3/9618hk8nwwQcf2NUQ1HPPPYcdO3bgxhtvxIIFC2AymfDGG29gwIAByMzMbNMx6uvr8eKLLzZb7+vri4ULF+Lll1/GvHnzMHbsWMyaNUu8DT4iIgJPPvkkAODMmTMYP348pk+fjn79+kGpVOKLL75AUVERZs6cCQBYt24d3nzzTdx5553o1asXqqqq8M4778DT0xO33XZbp10TImfBAEREVuHn54dvvvkGTz31FP75z3/Cx8cH9913H8aPH4+EhASpywMADBs2DNu2bcPTTz+NxYsXIywsDM8//zxOnjzZprvUgMZercWLFzdb36tXLyxcuBBz586FVqvFSy+9hL///e9wc3PDnXfeiZdfflm8syssLAyzZs1CSkoKPvjgAyiVSvTt2xcbN27EtGnTADROgj5w4AA2bNiAoqIieHl5YeTIkfjoo48QGRnZadeEyFnwXWBERL8zdepUHD9+HGfPnpW6FCKyEs4BIiKnVltba7F89uxZfPvttxg3bpw0BRGRTbAHiIicWkhICObOnYuePXviwoULeOutt2AwGJCRkYHevXtLXR4RWQnnABGRU5s4cSI++eQTFBYWQq1WIy4uDv/3f//H8EPUxbEHiIiIiJwO5wARERGR02EAIiIiIqfDOUAtMJvNyM/Ph4eHB2QymdTlEBERURsIgoCqqiqEhoZCLr96Hw8DUAvy8/MRFhYmdRlERER0HXJzc9G9e/ertmEAaoGHhweAxgvo6ekpcTVERETUFjqdDmFhYeL3+NUwALWgadjL09OTAYiIiMjBtGX6CidBExERkdNhACIiIiKnwwBERERETocBiIiIiJwOAxARERE5HQYgIiIicjoMQEREROR0GICIiIjI6TAAERERkdNhACIiIiKnwwBERERETocBiIiIiJwOA5BEao0mqUsgIiJyWgxAEliVchY3LNmO/b+WSV0KERGRU2IAksCrO88AABZ/eUziSoiIiJwTA5CElHJefiIiIinwG1hCLkpefiIiIinwG1hCLnKZ1CUQERE5JQYgCbkoePmJiIikIOk38J49e3DHHXcgNDQUMpkMW7ZsuWr7uXPnQiaTNfv0799fbPPcc8812963b18rn0nb1ZvM4s9KBXuAiIiIpCBpAKqursagQYOwevXqNrV/7bXXUFBQIH5yc3Ph6+uLe+65x6Jd//79Ldrt3bvXGuVfl6q6BvFnJYfAiIiIJKGU8pdPmjQJkyZNanN7Ly8veHl5ictbtmxBeXk55s2bZ9FOqVQiODi40+rsTFV19eLP9SZBwkqIiIicl0NPQnnvvfcQHx+PHj16WKw/e/YsQkND0bNnT9x7773IycmRqMLmdLWXe4BqjA1XaUlERETWImkPUEfk5+dj27Zt+Pjjjy3Wx8bGIjk5GdHR0SgoKMCyZcswZswYHDt2DB4eHi0ey2AwwGAwiMs6nc4qNdebzNh9plhcrq03X6U1ERERWYvDBqB169bB29sbU6dOtVh/5ZBaTEwMYmNj0aNHD2zcuBEPPPBAi8davnw5li1bZs1yAQD/2noSyT9ni8u17AEiIiKShEMOgQmCgLVr1+LPf/4zVCrVVdt6e3ujT58+yMrKarVNUlISKisrxU9ubm5nlwwAGB7hY7FcW88XohIREUnBIQPQ7t27kZWV1WqPzpX0ej3OnTuHkJCQVtuo1Wp4enpafKxhZISvxXIN3whPREQkCUkDkF6vR2ZmJjIzMwEA58+fR2ZmpjhpOSkpCbNnz26233vvvYfY2FgMGDCg2bann34au3fvRnZ2Nn7++WfceeedUCgUmDVrllXPpS0CPTUWy3X1JggC7wQjIiKyNUkD0MGDBzFkyBAMGTIEAJCYmIghQ4ZgyZIlAICCgoJmd3BVVlbi888/b7X35+LFi5g1axaio6Mxffp0+Pn5Yd++fQgICLDuybRRrwA38ed6k4AR/0pBZU39VfYgIiKiziYT2AXRjE6ng5eXFyorKzt9OKywsg4f77+AVbsuz0laMS0G00eEdervISIicjbt+f52yDlAjizYS4MnJ/SxWOeucdib8YiIiBwSA5AEZDLLV2CwD46IiMi2GIDsAJ8ITUREZFsMQHaAzwMiIiKyLQYgO8DnAREREdkWA5AdYAAiIiKyLQYgiay4O0b8me8EIyIisi0GIIlMHx6Gx8f3BsAeICIiIltjAJKQVqUAANQyABEREdkUA5CEmgIQe4CIiIhsiwFIQq6qxidA1/A2eCIiIptiAJLQ5SEwToImIiKyJQYgCblyCIyIiEgSDEAS0rpwEjQREZEUGIAkpG2aA8QAREREZFMMQBK6PATGOUBERES2xAAkIXESNO8CIyIisikGIAk1BaB6k4B6k1niaoiIiJwHA5CEmobAAM4DIiIisiUGIAmpFHIo5DIAvBOMiIjIlhiAJCSTycRb4TkRmoiIyHYYgCTmyonQRERENscAJDG+EZ6IiMj2GIAk5sqHIRIREdkcA5DEtHwfGBERkc0xAEns8sMQOQmaiIjIVhiAJObqwh4gIiIiW2MAkhgnQRMREdkeA5DEOAmaiIjI9hiAJMZJ0ERERLbHACSxy0NgnARNRERkKwxAEnNlDxAREZHNMQBJTHwXGF+FQUREZDMMQBLT/jYJmneBERER2Q4DkMQuD4FxDhAREZGtMABJjM8BIiIisj0GIIlxEjQREZHtSRqA9uzZgzvuuAOhoaGQyWTYsmXLVdunpqZCJpM1+xQWFlq0W716NSIiIqDRaBAbG4sDBw5Y8Sw6RssHIRIREdmcpAGouroagwYNwurVq9u13+nTp1FQUCB+AgMDxW2ffvopEhMTsXTpUhw6dAiDBg1CQkICiouLO7v8TnH5Zagm5FXU4rvjhbhUbZS4KiIioq5NKeUvnzRpEiZNmtTu/QIDA+Ht7d3itldffRXz58/HvHnzAABr1qzB1q1bsXbtWixatKgj5VpF08tQL1UbceNLuwAAUwaH4rWZQ6Qsi4iIqEtzyDlAgwcPRkhICCZMmICffvpJXG80GpGeno74+HhxnVwuR3x8PNLS0qQo9ZqaeoCu9GtJtQSVEBEROQ+HCkAhISFYs2YNPv/8c3z++ecICwvDuHHjcOjQIQBAaWkpTCYTgoKCLPYLCgpqNk/oSgaDATqdzuJjKz5aFW6M8kOghxq3RAcAAIfAiIiIrEzSIbD2io6ORnR0tLg8evRonDt3Dv/973/xwQcfXPdxly9fjmXLlnVGie0ml8vw0YOjAAA5ZTX44ZUfGICIiIiszKF6gFoycuRIZGVlAQD8/f2hUChQVFRk0aaoqAjBwcGtHiMpKQmVlZXiJzc316o1t8bHzQVA44RoPheIiIjIehw+AGVmZiIkJAQAoFKpMGzYMKSkpIjbzWYzUlJSEBcX1+ox1Go1PD09LT5ScFcr4aKQAQDKa9gLREREZC2SDoHp9Xqx9wYAzp8/j8zMTPj6+iI8PBxJSUnIy8vD+vXrAQArV65EZGQk+vfvj7q6Orz77rvYtWsXduzYIR4jMTERc+bMwfDhwzFy5EisXLkS1dXV4l1h9kwmk8HXTYUinQGXqo0I9XaVuiQiIqIuSdIAdPDgQdxyyy3icmJiIgBgzpw5SE5ORkFBAXJycsTtRqMRTz31FPLy8qDVahETE4Pvv//e4hgzZsxASUkJlixZgsLCQgwePBjbt29vNjHaXvloLwcgIiIisg6ZIAiC1EXYG51OBy8vL1RWVtp8OOxP7+zDz+fK8NrMwZgyuJtNfzcREZEja8/3t8PPAepqfNxUAHgrPBERkTUxANkZX21jACpnACIiIrIaBiA7I/YA8S4wIiIiq2EAsjO+2sZnAZVX10tcCRERUdfFAGRnvH8bAqusZQAiIiKyFgYgO+P1Ww9QRS2HwIiIiKyFAcjOeLv+FoBq2ANERERkLQxAdsbrtwBUyQBERERkNQxAdqZpDlCVoQH1JrPE1RAREXVNDEB2xlNz+e0kOk6EJiIisgoGIDujVMjh8VsIqmAAIiIisgoGIDvkreVEaCIiImtiALJD3q5NzwLirfBERETWwABkh9gDREREZF0MQHbIi88CIiIisioGIDt0uQeIQ2BERETWwABkh9zVjQFIbzBJXAkREVHXxABkh1xdFACA2noGICIiImtgALJDWlVjAKpjACIiIrIKBiA7pPktANUaGYCIiIisgQHIDnEIjIiIyLoYgOwQAxAREZF1MQDZIVdV45+Fc4CIiIisgwHIDmlcOAeIiIjImhiA7BCHwIiIiKyLAcgOufI2eCIiIqtiALJDWhclAA6BERERWQsDkB3S/DYJuqbeBEEQJK6GiIio62EAskNNc4AEATA0mCWuhoiIqOthALJDTXeBAZwHREREZA0MQHbIRSGHi0IGgHeCERERWQMDkJ3is4CIiIishwHITvFZQERERNbDAGSn+CwgIiIi62EAslNiD5CRd4ERERF1NgYgO9XUA8QhMCIios7HAGSnOAeIiIjIeiQNQHv27MEdd9yB0NBQyGQybNmy5artN2/ejAkTJiAgIACenp6Ii4vDd999Z9Hmueeeg0wms/j07dvXimdhHZeHwBokroSIiKjrkTQAVVdXY9CgQVi9enWb2u/ZswcTJkzAt99+i/T0dNxyyy244447kJGRYdGuf//+KCgoED979+61RvlWpVHxNngiIiJrUUr5yydNmoRJkya1uf3KlSstlv/v//4PX375Jb7++msMGTJEXK9UKhEcHNxZZUri8hAYJ0ETERF1NoeeA2Q2m1FVVQVfX1+L9WfPnkVoaCh69uyJe++9Fzk5ORJVeP04B4iIiMh6JO0B6qh///vf0Ov1mD59urguNjYWycnJiI6ORkFBAZYtW4YxY8bg2LFj8PDwaPE4BoMBBoNBXNbpdFav/Vr4HCAiIiLrcdgA9PHHH2PZsmX48ssvERgYKK6/ckgtJiYGsbGx6NGjBzZu3IgHHnigxWMtX74cy5Yts3rN7eHKV2EQERFZjUMOgW3YsAEPPvggNm7ciPj4+Ku29fb2Rp8+fZCVldVqm6SkJFRWVoqf3Nzczi653fgcICIiIutxuAD0ySefYN68efjkk08wefLka7bX6/U4d+4cQkJCWm2jVqvh6elp8ZEa5wARERFZj6RDYHq93qJn5vz588jMzISvry/Cw8ORlJSEvLw8rF+/HkDjsNecOXPw2muvITY2FoWFhQAAV1dXeHl5AQCefvpp3HHHHejRowfy8/OxdOlSKBQKzJo1y/Yn2AFNAaiOQ2BERESdTtIeoIMHD2LIkCHiLeyJiYkYMmQIlixZAgAoKCiwuIPrf//7HxoaGvDII48gJCRE/Dz++ONim4sXL2LWrFmIjo7G9OnT4efnh3379iEgIMC2J9dBGg6BERERWY2kPUDjxo2DIAitbk9OTrZYTk1NveYxN2zY0MGq7AOHwIiIiKzH4eYAOQveBUZERGQ9DEB2ylXV+KdhDxAREVHnYwCyUxr2ABEREVkNA5Cd0qoap2fp6upRUmW4RmsiIiJqDwYgOyXeBl9vxoh/fY/s0mqJKyIiIuo6GIDsVFMAavJFRp5ElRAREXU9DEB2SqOy/NOYr/K4ACIiImofBiA7pVJY/mlqOBmaiIio0zAA2SmZTGaxXFBZK1ElREREXQ8DkIPIr6iTugQiIqIugwHIQeRXsAeIiIioszAAOYgSvQHGBrPUZRAREXUJDEAOQhDYC0RERNRZGIAcyOGLFVKXQERE1CUwANmxzxfEYf6YSPwpNhwAkH6hXOKKiIiIugYGIDs2rIcv/jG5H27s5Q+AAYiIiKizMAA5gKE9vAEAJwt0MDTwgYhEREQdxQDkAALc1QAAswDUGBiAiIiIOooByAEoFXIo5Y1PhjbwVngiIqIOYwByEJrf3g5fV88eICIioo5iAHIQGpfGP1Ud5wARERF1GAOQg1Arm3qAOARGRETUUQxADkLd1APEITAiIqIOYwByEJrfeoA4CZqIiKjjGIAchIY9QERERJ2m3QGotrYWNTU14vKFCxewcuVK7Nixo1MLI0u8C4yIiKjztDsATZkyBevXrwcAVFRUIDY2Fv/5z38wZcoUvPXWW51eIDVSKxv/VAZOgiYiIuqwdgegQ4cOYcyYMQCAzz77DEFBQbhw4QLWr1+PVatWdXqB1KipB4ivwiAiIuq4dgegmpoaeHh4AAB27NiBu+66C3K5HKNGjcKFCxc6vUBqdHkIjD1AREREHdXuABQVFYUtW7YgNzcX3333HW699VYAQHFxMTw9PTu9QGrESdBERESdp90BaMmSJXj66acRERGB2NhYxMXFAWjsDRoyZEinF0iNxAchcgiMiIiow5Tt3eHuu+/GTTfdhIKCAgwaNEhcP378eNx5552dWhxddvlBiBwCIyIi6qh2ByAACA4ORnBwMABAp9Nh165diI6ORt++fTu1OLrs8oMQ2QNERETUUe0eAps+fTreeOMNAI3PBBo+fDimT5+OmJgYfP75551eIDXiJGgiIqLO0+4AtGfPHvE2+C+++AKCIKCiogKrVq3Ciy++2OkFUiNOgiYiIuo87Q5AlZWV8PX1BQBs374d06ZNg1arxeTJk3H27NlOL5Aa8W3wREREnafdASgsLAxpaWmorq7G9u3bxdvgy8vLodFoOr1AatTUA8Q5QERERB3X7gD0xBNP4N5770X37t0RGhqKcePGAWgcGhs4cGC7jrVnzx7ccccdCA0NhUwmw5YtW665T2pqKoYOHQq1Wo2oqCgkJyc3a7N69WpERERAo9EgNjYWBw4caFdd9kh8EjR7gIiIiDqs3QFo4cKFSEtLw9q1a7F3717I5Y2H6NmzZ7vnAFVXV2PQoEFYvXp1m9qfP38ekydPxi233ILMzEw88cQTePDBB/Hdd9+JbT799FMkJiZi6dKlOHToEAYNGoSEhAQUFxe3qzZ7I84BYg8QERFRh8kEQRCud+emXWUyWccLkcnwxRdfYOrUqa22+fvf/46tW7fi2LFj4rqZM2eioqIC27dvBwDExsZixIgR4p1qZrMZYWFheOyxx7Bo0aI21aLT6eDl5YXKykq7ebr1z1ml+NO7+9EnyB07nhwrdTlERER2pz3f3+3uAQKA9evXY+DAgXB1dYWrqytiYmLwwQcfXFex7ZGWlob4+HiLdQkJCUhLSwMAGI1GpKenW7SRy+WIj48X2ziqpgchninS47vjhRJXQ0RE5NjaHYBeffVVLFiwALfddhs2btyIjRs3YuLEiXj44Yfx3//+1xo1igoLCxEUFGSxLigoCDqdDrW1tSgtLYXJZGqxTWFh66HBYDBAp9NZfOxN011gAPCXD9IlrISIiMjxtftJ0K+//jreeustzJ49W1z3xz/+Ef3798dzzz2HJ598slMLtIXly5dj2bJlUpdxVU2ToJsIgtApQ49ERETOqN09QAUFBRg9enSz9aNHj0ZBQUGnFNWa4OBgFBUVWawrKiqCp6cnXF1d4e/vD4VC0WKbpld3tCQpKQmVlZXiJzc31yr1d0QPPy36hVwez6w2cjI0ERHR9Wp3AIqKisLGjRubrf/000/Ru3fvTimqNXFxcUhJSbFYt3PnTvGN9CqVCsOGDbNoYzabkZKSIrZpiVqthqenp8XH3rgo5Pj28TFwUzX2BJVUGSSuiIiIyHG1ewhs2bJlmDFjBvbs2YMbb7wRAPDTTz8hJSWlxWB0NXq9HllZWeLy+fPnkZmZCV9fX4SHhyMpKQl5eXlYv349AODhhx/GG2+8gWeeeQb3338/du3ahY0bN2Lr1q3iMRITEzFnzhwMHz4cI0eOxMqVK1FdXY158+a191TtUoCHGtVlNSipMiDS303qcoiIiBxSuwPQtGnTsH//fvz3v/8VH1x4ww034MCBAxgyZEi7jnXw4EHccsst4nJiYiIAYM6cOUhOTkZBQQFycnLE7ZGRkdi6dSuefPJJvPbaa+jevTveffddJCQkiG1mzJiBkpISLFmyBIWFhRg8eDC2b9/ebGK0o/J3VyO7rAalevYAERERXa8OPQfoSsXFxXj33Xfx7LPPdsbhJGWPzwFqsuDDdGw7Vohlf+yPOaMjpC6HiIjIblj9OUAtKSgowOLFizvrcNSKAA81AM4BIiIi6ohOC0BkG/7ujQGIQ2BERETXjwHIwbAHiIiIqOMYgByMj1YFACivMUpcCRERkeNq811gTXdotaakpKTDxdC1eWga/2TVBj4IkYiI6Hq1OQBlZGRcs83NN9/coWLo2tzVjX8yvaFB4kqIiIgcV5sD0A8//GDNOqiN3H4LQFV19RJXQkRE5Lg4B8jBiENgRhM66RFORERETocByME0DYGZzALq6s0SV0NEROSYGIAcjFalgEzW+HOVgcNgRERE14MByMHIZDK4q36bCF3HidBERETXgwHIAbnzVngiIqIOaXMAWrFiBWpra8Xln376CQbD5acRV1VVYeHChZ1bHbWoaR4Qh8CIiIiuT5sDUFJSEqqqqsTlSZMmIS8vT1yuqanB22+/3bnVUYuaeoASPz2M7NJqiashIiJyPG0OQL+/5Zq3YEunqQeoUFeHxz659gMqiYiIyBLnADmgpgAEAEfzKiWshIiIyDExADmgKwOQVqWQsBIiIiLH1OZXYQDAu+++C3d3dwBAQ0MDkpOT4e/vDwAW84PIuq4cfPR2dZGsDiIiIkfV5gAUHh6Od955R1wODg7GBx980KwNWV9hZZ34s9HEp0ETERG1V5sDUHZ2thXLoPZoehI0AFyqNsJkFqCQy1rfgYiIiCxwDpAD+sfkGxDp7wYAMAtARY1R4oqIiIgcS5sDUFpaGr755huLdevXr0dkZCQCAwPx0EMPWTwYkaynb7Anfnh6HHy0jfN/yqoZgIiIiNqjzQHo+eefx/Hjx8Xlo0eP4oEHHkB8fDwWLVqEr7/+GsuXL7dKkdQyP3c1AKBUz+BJRETUHm0OQJmZmRg/fry4vGHDBsTGxuKdd95BYmIiVq1ahY0bN1qlSGqZn5sKAFCqZw8QERFRe7Q5AJWXlyMoKEhc3r17NyZNmiQujxgxArm5uZ1bHV2Vf1MPUBV7gIiIiNqjzQEoKCgI58+fBwAYjUYcOnQIo0aNErdXVVXBxYXPpLGlEC8NACCvovYaLYmIiOhKbQ5At912GxYtWoQff/wRSUlJ0Gq1GDNmjLj9yJEj6NWrl1WKpJb18NMCAHIu1UhcCRERkWNp83OAXnjhBdx1110YO3Ys3N3dsW7dOqhUKnH72rVrceutt1qlSGpZmO9vAaiMAYiIiKg92hyA/P39sWfPHlRWVsLd3R0KheU7qDZt2iS+JoNso4df47OAci7VQBAEyGR8GCIREVFbtPtBiF5eXs3CDwD4+vpa9AiR9XXzdoVcBtTWm1DCidBERERt1uYeoPvvv79N7dauXXvdxVD7qJRyhHi5Iq+iFjmXahDoqZG6JCIiIofQ5gCUnJyMHj16YMiQIRAE4do7kE2E+2qRV1GLvIpaDJe6GCIiIgfR5gC0YMECfPLJJzh//jzmzZuH++67D76+vtasjdrA+7fXYehq6yWuhIiIyHG0eQ7Q6tWrUVBQgGeeeQZff/01wsLCMH36dHz33XfsEZKQu7oxw+rqGiSuhIiIyHG0axK0Wq3GrFmzsHPnTpw4cQL9+/fHwoULERERAb1eb60a6So8NI09QHoDAxAREVFbtfsuMHFHuRwymQyCIMBkMnVmTdQO7prGHqCqOg6BERERtVW7ApDBYMAnn3yCCRMmoE+fPjh69CjeeOMN5OTk8BlAEvH8LQDpOQRGRETUZm0OQAsXLkRISAheeukl3H777cjNzcWmTZtw2223QS6/7o4kAI3ziyIiIqDRaBAbG4sDBw602nbcuHGQyWTNPpMnTxbbzJ07t9n2iRMndqhGe9U0B+hIXiV+yb4kcTVERESOoc13ga1Zswbh4eHo2bMndu/ejd27d7fYbvPmze0q4NNPP0ViYiLWrFmD2NhYrFy5EgkJCTh9+jQCAwNbPL7RaBSXy8rKMGjQINxzzz0W7SZOnIj3339fXFar1e2qy1E0zQH6taQa96xJQ8pTY9ErgL1xREREV9PmADR79myrvGrh1Vdfxfz58zFv3jwAjUFr69atWLt2LRYtWtSs/e9vvd+wYQO0Wm2zAKRWqxEcHNzp9dqbpjlATcb/Zzf+FBuO/7tzoEQVERER2b92PQixsxmNRqSnpyMpKUlcJ5fLER8fj7S0tDYd47333sPMmTPh5uZmsT41NRWBgYHw8fHBH/7wB7z44ovw8/Pr1PrtgYem+Z/w4/05DEBERERX0eYAZA2lpaUwmUwICgqyWB8UFIRTp05dc/8DBw7g2LFjeO+99yzWT5w4EXfddRciIyNx7tw5PPvss5g0aRLS0tJafI+ZwWCAwXD5XVo6ne46z8j2PNQt/wnrTWa4KDo2N4uIiKirkjQAddR7772HgQMHYuTIkRbrZ86cKf48cOBAxMTEoFevXkhNTcX48eObHWf58uVYtmyZ1eu1hqY5QL9XV29iACIiImqFpN+Q/v7+UCgUKCoqslhfVFR0zfk71dXV2LBhAx544IFr/p6ePXvC398fWVlZLW5PSkpCZWWl+MnNzW37SUjs93OAmtTW89lMRERErZE0AKlUKgwbNgwpKSniOrPZjJSUFMTFxV11302bNsFgMOC+++675u+5ePEiysrKEBIS0uJ2tVoNT09Pi4+jcFM1H9IDAEO92caVEBEROQ7Jx0gSExPxzjvvYN26dTh58iQWLFiA6upq8a6w2bNnW0ySbvLee+9h6tSpzSY26/V6/O1vf8O+ffuQnZ2NlJQUTJkyBVFRUUhISLDJOdlSa3fmsQeIiIiodZLPAZoxYwZKSkqwZMkSFBYWYvDgwdi+fbs4MTonJ6fZgxZPnz6NvXv3YseOHc2Op1AocOTIEaxbtw4VFRUIDQ3FrbfeihdeeKHLPguoyV1Du2Hb0ULU1ptQa2QAIiIiao1M4Kvcm9HpdPDy8kJlZaVDDIf1/se3qDcJWH//SDz39XH8WlKNTx8ahdieXe+2fyIiota05/tb8h4g6rjUv92Cs0VVuLlPAFxdGucEcQiMiIiodQxAXUA3b1d083YFADEA1TEAERERtUrySdDUuTRiAOJdYERERK1hAOpiNBwCIyIiuiYGoC7GVcUhMCIiomthAOpiNMrGPyl7gIiIiFrHANTFiD1AfA4QERFRqxiAuhjxLrAGToImIiJqDQNQF6NumgTNHiAiIqJWMQB1MXwQIhER0bUxAHUxri6Nf1LeBUZERNQ6BqAuRsMnQRMREV0TA1AX03QXGIfAiIiIWscA1MXwVRhERETXxgDUxbjyLjAiIqJrYgDqYvguMCIiomtjAOpiuvu4AgAulFWjsqZe4mqIiIjsEwNQFxPq7Yrege4wC8CesyVSl0NERGSXGIC6oHHRAQCA1NMlSL9QjgfX/YLs0mqJqyIiIrIfDEBd0M19GgPQvl/LMO2tn/H9yWIs2nxE4qqIiIjsBwNQFzSshw+UchnyKmrFdbmXaq+yBxERkXNhAOqCtColBnTzsljn6eoiUTVERET2hwGoi4qN9LVY9lArJaqEiIjI/jAAdVE39fa3WOZzgYiIiC5jAOqiRvX0s1i+VG2UqBIiIiL7wwDURbko5Ojp7yYul9cwABERETVhAOrCPp4/CncMCgUA1BhNqOMwGBEREQAGoC4t2EuDVTMHQyGXAQAq+GoMIiIiAAxAXZ5MJoOPtvEWeA6DERERNWIAcgI+WhUAoJwToYmIiAAwADmFpgD0p3f3MwQRERGBAcgp3Bh1+ZlA3x0vlLASIiIi+8AA5AQej++NWSPDAAA/ZpXC2GCWuCIiIiJpMQA5iSmDuwEAth4pQPyru1FvYggiIiLnxQDkJIaEe0OlbPxz51yqQWFlncQVERERSYcByEmolQq8OGWAuFzGydBEROTEGICcyPQRYegf6gmAt8QTEZFzs4sAtHr1akRERECj0SA2NhYHDhxotW1ycjJkMpnFR6PRWLQRBAFLlixBSEgIXF1dER8fj7Nnz1r7NByCr1vjLfHsASIiImcmeQD69NNPkZiYiKVLl+LQoUMYNGgQEhISUFxc3Oo+np6eKCgoED8XLlyw2L5ixQqsWrUKa9aswf79++Hm5oaEhATU1XHeS1MAYg8QERE5M8kD0Kuvvor58+dj3rx56NevH9asWQOtVou1a9e2uo9MJkNwcLD4CQoKErcJgoCVK1fin//8J6ZMmYKYmBisX78e+fn52LJliw3OyL6xB4iIiEjiAGQ0GpGeno74+HhxnVwuR3x8PNLS0lrdT6/Xo0ePHggLC8OUKVNw/Phxcdv58+dRWFhocUwvLy/ExsZe9ZjOwpevxSAiIpI2AJWWlsJkMln04ABAUFAQCgtbfmJxdHQ01q5diy+//BIffvghzGYzRo8ejYsXLwKAuF97jmkwGKDT6Sw+XZWvO3uAiIiIJB8Ca6+4uDjMnj0bgwcPxtixY7F582YEBATg7bffvu5jLl++HF5eXuInLCysEyu2L35Nc4D4ZngiInJikgYgf39/KBQKFBUVWawvKipCcHBwm47h4uKCIUOGICsrCwDE/dpzzKSkJFRWVoqf3Nzc9p6Kw2h6MWr6hXIcy6uUuBoiIiJpSBqAVCoVhg0bhpSUFHGd2WxGSkoK4uLi2nQMk8mEo0ePIiQkBAAQGRmJ4OBgi2PqdDrs37+/1WOq1Wp4enpafLoqv9+GwADg8Q0ZElZCREQkHaXUBSQmJmLOnDkYPnw4Ro4ciZUrV6K6uhrz5s0DAMyePRvdunXD8uXLAQDPP/88Ro0ahaioKFRUVOCVV17BhQsX8OCDDwJovEPsiSeewIsvvojevXsjMjISixcvRmhoKKZOnSrVadqNbt5a8edzJdUSVkJERCQdyQPQjBkzUFJSgiVLlqCwsBCDBw/G9u3bxUnMOTk5kMsvd1SVl5dj/vz5KCwshI+PD4YNG4aff/4Z/fr1E9s888wzqK6uxkMPPYSKigrcdNNN2L59e7MHJjojV5UCPz5zC8as+AEAUGNsgFYl+T8DIiIim5IJgiBIXYS90el08PLyQmVlZZccDhMEAdGLt8PYYMbev9+C7j7aa+9ERERk59rz/e1wd4FRx8lkMvFusEu8HZ6IiJwQA5CTarobjAGIiIicEQOQk2q6G4wBiIiInBEDkJPyvWII7FShDiYzp4IREZHzYAByUk1DYCu/P4uJK3/EqztPS1wRERGR7TAAOammSdB6QwMAYPUP51BjbJCyJCIiIpthAHJSPm6qZuu+Pdryy2KJiIi6GgYgJ+Xv3jwA/Vqil6ASIiIi2+MjgJ3UjVH+uLVfEEZG+kJX14BVKWehq6uXuiwiIiKbYAByUh4aF/xv9nAAwLs//goAqKrjHCAiInIOHAIjeLq6AAB0tewBIiIi58AARPDUNHYEsgeIiIicBQMQwVPT2AN0okCHbUcLwPfjEhFRV8cARPD4LQDVGE1Y8NEhbD1aIHFFRERE1sUARPB0tZwLv/0YnwdERERdGwMQiUNgTY7mVeJkgU6iaoiIiKyPAYjgrrHsAbpQVoPbX9+Lihq+KZ6IiLomBiCCi6L5PwOTWcCJfPYCERFR18QARK06XVQldQlERERWwQBErTp4oRxTV/+Et3efk7oUIiKiTsUARBYi/LRYNWsIAGDrkQJk5lZg+bZTaDCZJa6MiIio8zAAkYXeQR7oG+zRbH1mboXtiyEiIrISBiACALw/dwTG9gnAi1MHIMxH22z7njMlElRFRERkHXwbPAEAbukbiFv6BorLri4K1NabxOUM9gAREVEXwh4gapGvm8piuVhnkKgSIiKizscARC3yc/9dAKqqk6gSIiKizscARC36fQ9QeU09DA2mVloTERE5FgYgapGfm7rZupIqDoMREVHXwABELfr9EBgAFHEeEBERdREMQNSiK4fA/H8LQ8U6zgMiIqKugQGIWuSpcRF/7hPU+GDErGI9DmZfgiAIUpVFRETUKRiAqEVXviA+KtAdAPCfnWdw95o0vLz9tERVERERdQ4GIGqRu/pyD1Dv3wJQkzW7zyEjp9zWJREREXUaPgmaWjShXxBu7hOAIWHeuGd4GLy0KmiUcmw8eBHfnyzCzhNFqKs3w0Uhw/AIX6nLJSIiaheZwAkdzeh0Onh5eaGyshKenp5Sl2NXPk+/iKc2HYa31gUVNfUAgDMvToJKyc5EIiKSVnu+v/mtRe0yprc/AIjhBwDKa4xSlUNERHRdGICoXQI9NRgc5m2xrkzPAERERI7FLgLQ6tWrERERAY1Gg9jYWBw4cKDVtu+88w7GjBkDHx8f+Pj4ID4+vln7uXPnQiaTWXwmTpxo7dNwGitnDBafDQQAl6oZgIiIyLFIHoA+/fRTJCYmYunSpTh06BAGDRqEhIQEFBcXt9g+NTUVs2bNwg8//IC0tDSEhYXh1ltvRV5enkW7iRMnoqCgQPx88skntjgdpxDh74bvE8eip78bAKCsmk+IJiIixyJ5AHr11Vcxf/58zJs3D/369cOaNWug1Wqxdu3aFtt/9NFHWLhwIQYPHoy+ffvi3XffhdlsRkpKikU7tVqN4OBg8ePj42OL03Ea3loV+oY0PiDxyh6gunq+MJWIiOyfpAHIaDQiPT0d8fHx4jq5XI74+HikpaW16Rg1NTWor6+Hr6/lrdipqakIDAxEdHQ0FixYgLKysk6tnS6/LmPZ1yew61QRln97Ev2WbMeXmXnX2JOIiEhakj4HqLS0FCaTCUFBQRbrg4KCcOrUqTYd4+9//ztCQ0MtQtTEiRNx1113ITIyEufOncOzzz6LSZMmIS0tDQqFotkxDAYDDIbLwzg6ne46z8i5+F7xxvj7kw+KP3+WfhFTBneToiQiIqI2cegHIb700kvYsGEDUlNTodFoxPUzZ84Ufx44cCBiYmLQq1cvpKamYvz48c2Os3z5cixbtswmNXclfm7N3xgPAEfzKmE2C5DLZTauiIiIqG0kHQLz9/eHQqFAUVGRxfqioiIEBwdfdd9///vfeOmll7Bjxw7ExMRctW3Pnj3h7++PrKysFrcnJSWhsrJS/OTm5rbvRJyU7+8C0LSh3aFxkaOiph5ZJXqJqiIiIro2SQOQSqXCsGHDLCYwN01ojouLa3W/FStW4IUXXsD27dsxfPjwa/6eixcvoqysDCEhIS1uV6vV8PT0tPjQtXlrL78v7JvHbsK/74nBkLDGyebpF/iuMCIisl+S3wWWmJiId955B+vWrcPJkyexYMECVFdXY968eQCA2bNnIykpSWz/8ssvY/HixVi7di0iIiJQWFiIwsJC6PWNPQ56vR5/+9vfsG/fPmRnZyMlJQVTpkxBVFQUEhISJDnHrsrf/fIcoBtCPCGTyRAd3Hhn2IWyGnGbrq4exgazzesjIiJqjeRzgGbMmIGSkhIsWbIEhYWFGDx4MLZv3y5OjM7JyYFcfjmnvfXWWzAajbj77rstjrN06VI899xzUCgUOHLkCNatW4eKigqEhobi1ltvxQsvvAC1Wg3qPDeEeOLFqQPQw08LxW/zfbr7uAIALpbXiP97x+t7Eenvhs0Lb5SsViIioivxZagt4MtQr9+2owVY8NEhDA7zxpZHbsSD637B9ycbH2p56oWJ0Lg0vwuPiIioM/BlqCSZ7j5aAEBeRS3Kq43YderyE73X/ZyNYl2dVKURERGJGICoUzUNgZVUGfDd8UKYr+hfXL7tFMb/Z7c4PEZERCQVBiDqVN5aFyh/mw+0aPPRZturDA145rMjEAQBxVV1OF9abesSiYiIpJ8ETV2LTCaD6XfTysJ8XZF7qVZc/vlcGf7yQTpSThVDBmDrX8eId48RERHZAnuAqNM9dksUXF0U8HJ1QWykL6YN7S5ui41sfGfbjhNFMJkFNJgFfH+yqLVDERERWQXvAmsB7wLruCtfhfFW6jm8vL3x3W7fJ45F/Ku7m7UfGu6NjX+Jg1LBTE5ERNeHd4GR5K58D9iEfo3PdOob7IGoQHcM6Nb4jzKup5/Y5lBOBU4VVgEAmMmJiMja2APUAvYAdb5fS/Tw91DDU+OC/IpafHU4H7PjemDCq3uQV9E4P+jJ+D44mleB1NMleOjmnnhmYl+JqyYiIkfSnu9vBqAWMADZTu6lGrzwzQnsONF8HpC7Won35gxH7BU9RURERK3hEBg5jDBfLf4c10NclssuT5TWGxqQuPEwyvQG6OrqUVFjFNsJggBDg8nm9RIRUdfA2+BJcsN7+KJvsAfKa4x4fHwf/Ck2HGeLqjDptR+RV1GLYS9+DwDwUCvx9uxh0LgosODDdBRXGfDSXQMxY0S4eKwfThfD1UWBUew1IiKiq+AQWAs4BGYfdp0qwvNfn0B2WetPjo4KdMfOJ2+GTCbDhbJqjPt3KpRyGX585g8I9tLYsFoiIpIah8CoS/hD3yD88PQ4vDN7OP5x2w2Y2D9YfMq0xqXxn25WsR5HLlYCALYfK4QgAPUmAevTsqE3NOCt1HMoruL7x4iIyBJ7gFrAHiD7VaY3YPvxQsRG+mHl92fwzZECdPN2xYcPxuLxDRliGPJydcH4voHYnJEHoPEVHW/+aSjCfLUI89VKeQpERGQlvAusgxiAHEN+RS3ue3c/fr3ifWIuChn83NQovMpb5+8bFQ4/NzV6BrhhyuBubf59giBAJpNduyEREUmCAaiDGIAcR3FVHe5682dcLK+FxkWOf98zCJeqjVjy5fE27R/qpcGdQ7uhm7cWtw8KgafGBQBQUWPEXW/9jJ7+bpg2tDsultfi5e2n8PqsIbilbyA0LoprHvtkgQ6legPG9A7o0DkSEVHbMAB1EAOQYynTG3AsX4eB3bzg66ZCXb0JU974CaeLGp8s3SvADedK2vbWeReFDHKZDIYG81XbRfhp8fqsoRjY3avF7eXVRtz8yg+oqmvA5oWjMTTcp30nRURE7cYA1EEMQI5PV1ePD/ddwK39ghAV6IEfThdj18liJE7og6c3HcapwirkV9aiI//6tSoF5t0YgR/PliLMR4sld/SDj1aFRZuPYPOhPIu2f0uIxs29A+ChUSL552yUVRuxaFJfrEk9hxMFOrw/bwQ8NS4QBAF7s0oR4qVBqLcrinQGRPq7dfBqEBE5BwagDmIAcg75FbXwdVOhSFeHnEs12HTwIu6NDYe3VoV/fXsSx/Iqcana2OK+N0b54aesMot1Hmolege541BORZt+/8gIXxzIvgSgsZfKXa1EVrEe1UbLBzy+/edhiAp0R63RhAHdWu5xIiIiBqAOYwCiJvt/LUMPPzf4uatw63/34HxpNSbHhGDVzCF498df8e8dp1FvEiCTQexN0rjI8WR8HwwO88bJAh1e35WFslaCVGuuPF7vQHcUVNZBb2gA0Bi+7hkWBr2hAcVVBlTWGDFxQAjyK2oxMtIX3X1csf1YISID3NA32BN7zpRg7U/n8c/J/RAV6N6Zl4eIyK4wAHUQAxC1JKtYj03puXjklihxsnR5tREqpRxniqrw98+PwN9djadujcawHpfn/AiCgB/PluIfW44i91Jti8eWywCzcPnnA/+IR2ZOBR5cf7BdNV4ZnBRyGUb38sOPZ0sBAD5aF0QFuqOkyoAbQjwRG+kLX3c1bgj2QEmVASMifeGikKPeZIZZEKBWtjzRe/m3J7Hhl1yM7ROAFXfHWEwI19XVw1PjgvQL5Thw/hLmj4mEUtH8cWPGBjOq6urh565u1/kREV0NA1AHMQCRNRRU1uL5r0/gvlE9sOGXXHx9OB9/Hd8bUwaHwlBvRoS/Fiu/P4ubovxxc5/GO8fmvn8AqadLAABxPf3QO8gdekMDNh/KQzdvV0QFumP3mZJOq1GrUqDGaILGRY5hPXzQYBKgq2uAr5sL/jyqB45crMSbqecs9okKdEdPfzdUGxvwU1YZHvtDFF7flQUA+NedAzBlcDesT8tGiJcGfxzUDduPFeKZzw6j2mjCuvtHYmyftt8lt+N4IVwUcnxzpACTY4Lxh75BV23fYDK3GMCIqGtiAOogBiCytqq6epwp0mNouPdVny1UazThyMUK+Huo0Svg8vDVhbJqBHtpoFYqcDD7EvacKcGDN/fEuWI9kjYfRVSgO2aOCMfmjIvYdrQQM0eGIfV0CS6UVWNM7wAczL7UbK6RLaiV8mZ32N02MBh+bmok9A/GwG5eWLXrLCYNCMbwCF+Ldpm5FZi6+ieLdc9MjMacuAi4qZUwmwVU1NZDEASolHL8bdMRfHeiEH8cFIqxfQJwe0wolHIZ6hpM0KqUMDSYIJfJoJTL+Hwnoi6CAaiDGICoKzGbBcjlMpjNAgwNZriqFDCZBXyWnosIPzeU6o3QG+qxJSMfOZdqoFbKcffw7hAE4OdzpfB1U2P/r2UorjKIx3xmYjT2ni1FeU09/hQbjowL5fDWqvDV4XyU6g1XqaZRgIcaJVVXb+epUUKpkKNvsAcMDWakXyhvsd2onr4wNJiR8dvkczeVAjHdvZH2q+Uk9UkDgnE8X4caYwNWzhiChR+lo+a3EPjX8b3x1/G9r1l3k6aHYgqCgJ0nitDNxxX9QzlBnUhqDEAdxABEZOnXEj3e+CELN0X5I/dSLf4ytifUSnmznpP8ilp8+ksubu7jj32/XsKhC+V46tZoRAd74Hh+JV7cehKDunvhsfG9MWftAWTkVGBMb3+4uiiw40RRm+vxc1O1aWJ5oIfaIrhdS/wNQegX6gkZgBK9AQHuavTw08LYYMZXh/Nxe0woDl64hAPnL2HVrCHYdDAXnxzIBQD4u6vwzMS+8NWqsOyb4xAE4PHxvVFRU4/eQe7wd1ejT5AHVMrLQ3I5ZTXILqvGmN7+MDSYoVbKUW004fP0i7i5T0Crj0A4lFOOnv5u0LgokJFTgdhIX8jl7MUiYgDqIAYgIusrrKzDiYJKjOsTCJkM+PxQHo5erECEvxv2ni3FmN7+6OajxcKP0lFvavzP1MJxvfCXsb3g6qKAi0KG4S9+j7JqI9RKOR69JQpGkxmHL1Ziz5kS9A/1xNeP3oT8ylokbjyMA+cvIaa7l/i+OI2LHMnzRmLN7nPiPCtrC/fVYtbIcJTpDSjQ1WHrkQKL7TdG+UEpl2P3mRJ4qJVYcEsvDO/hixtCPPDBvguoqzfjUrUBH+7LwchIX/QL8UTyz9l49ra+cFMrkVNWg/k398SvJdWIDvKAl9alxTqaerDK9AZkl9XATa1AdJAHhwLJ4TEAdRADEJH9+PFsCU7k6/DATc3vKNtzpgTv/Pgr/jm5H6KDPcT1v5bo4eeuhpdrYwCoNjTgyMVKjIz0xZs/ZCHnUg1mx0VgYHcv1NWbsO1YAbxcXfDRvhxk5FYg0t8NhZV1yKtofteeu1opPpIAAP5x2w0wCwKWbzvVYv3+7ip4a1XIKtZ3xuVoM6VchjBfLaKDPBDm64owXy2yS2uw52wJjA1mTBwQjPd/Oi+Gy7uHdceICB98uC8HrioFgjw18NW6INzPDSfydRgS7o3BYd5QKeUwC0KzwHShrBqbDl7EhH5BSD1dgp/PleKlaTGQAaisrYevmwonCnQYEuaNQE8NgMbh2XqzucU7DpuGbonagwGogxiAiAgASvUGuKmUyC2vQaS/G2QAlAo5DA0mbDx4ERAE3DeqB2QyGbKK9Vj61TFU1TVg0aS++NM7+wEAS27vh/tvikRJlQGrf8hCid6AIA8NzhRVYW9Wqfi7rpwX9d8Zg1BXb8Z3xwuRmVuBipp6eLm6wM9dhTqjCfmVrb/st7081EpUXRHo2mp0Lz/cNbQ7ThbocLG8Bj+cKoHRdPVXyACN5zl1cCh+yS7H6cIqyGXAP2/vhz/0DcSJAh0yLpTjXEk19pwpQXdfLUZE+GDK4FDIZDLsOF4EN5UCEwcE42yxHiMifBHgcflRCqV6A6rqGhDuq0VmbgV8tC749mgBhvXwxaievjhZUIXaepPFYyoultcg2FPTLFw3TZJ34V2EDoUBqIMYgIiooz5Pv4iM3HL8c3K/q74894uMi8grr8Wc0RFY8uVxDA7zxpzREeJ2Y4MZlbX18HdXiT0ueRW1+PO7+/FraTWCPTXw91Bh3uhIJP+cDb2hAZ8+NArH8itRazQju6wxTBzKKceY3gHwdVPhx7MlkEGG+0aF45FbovDpL7lY/OUx1JsETOwfDJmsMUxEBbrjXHE1dHX1KNUbAQjQGxpQV3/toHMlhVwGuQxib1Nn0qoU8HJ1QbivFukXytFgFiyeq9WSW6IDEOzlitOFOhzKqcANIZ74y8094aFRoqquAWG+rvjrJ5koqTIgwEONCf2C0D/UE6+lnEX8DUF4Ir435HIZ3FVKyOUy6A0NOHKxAsYGM97bex5leiNmjQzD3cPC4KpSoOlrttpogtZFgWpjA9zVSjSYBbzwzQmcLqzC238eBm+tCgWVtThZoEOkv7vFHLBDOeWoNZpwY5R/q+elNzTAUG9y6udrMQB1EAMQEdm7unoTjlysxNBwb7H3QhAECAJaHDoyNpgtJmD/XmVNPXLLa9A/1POac4HOl1YjcWMmci/V4pboAAR6qjEkzAfjbwhEdlkNwnxccaZIj/QLl3BjlL/4Ra6rbcD/fjyHrGI9xvQOQGykL9b+lI3vTxahVG+Au0qJG0I9kZlTgQAPNfoEuaOqrgFH8yohkwE3RfmjvKYeGTnlVw04tuKhVsLT1aXV9wqqlXK4qhSoMZggQGj21PgrxXT3Qkx3L3y8P0c8twg/LUb19ENBZZ34vK97hnVHnyAPeGtdUKSrgyAAxVUGCBDwVWY+autNGNsnAOOiAzF9eBjOlehRXGXAnjMlmDEiDFEB7jALgvhvpriqDhsO5MLYYMbwCB9kFeuhVSmhcZFj6uBuVx2GvFRtxLkSvVj/74cyN/6Si2+PFaB/qCceH98H9SYzXF0UVh3aZADqIAYgIiLbqqyth1oph8ZF0ewBliazAOGKL21jgxm1RhO+OpyHfqGeKNMbcb60GjdG+aNXgDvKqg3QuCiwJSMPY/sEIDO3ApsOXsTj8b3xVuo5nC+txh8HhyLCT4swHy2+yMjD6aIqZJdWAwB0dQ2IDvLAPcO7I+VkMdJ+LYNMBvQP9YSutgE5l2paPY+Y7l4Y1ycAmzPycLG85Se/X0sPPy3yK2qt0mMmlwECAH93NUK9NDhXUm0xp+33lHIZPF1dMDTcByqlDOkXyiFD4/O0KmrqLdr2DfaAUiFDeXU9uvm44sD5S+I2D40S1YYGmIXGnyf0C8LCcb0QFejx+1/ZIQxAHcQARETkvH7fW3amqAq+bir4u6thaDAh91INQrxccb60GjVGE3oFuMFH2zjJu+lRB4Ig4Hi+DrraenT30UKpkMFb64JL1UYIAnA8vxKR/u5wUciw61Qxdp8pgb+7GlOHdMPYPgHQGxrwU1Ypjl6shJu6MTCcK9HjwPlLKKkyoFRvQJCnBgq5DIEeapgEAQO7ecHL1QV7z5big30XUGM0iYHnat/00UEe0BsaxEn/PloXlP8u3LREJgO6ebsiv6K21R45d7USRpMZxobmw6ZTBofitZlDrvl72oMBqIMYgIiIyJHVGk0orzEiyFMDsyDARSFHVV09aowmyGRAUaUBJwt16ObtiriefjA0mJGZW4HhET5wUchRUmVAfkUtAjzUKNLVYc+ZUigVMgzv4QM3tRIKuQwRfm5wVSlwqlCHxz7OQO8gdyT0D4ahwYxfzl+CQi5D0m03oMbYgBP5OhgazPgg7QJ83VSoN5mReGsf9A3u3O9YBqAOYgAiIiJyPO35/ub9fUREROR0GICIiIjI6TAAERERkdOxiwC0evVqREREQKPRIDY2FgcOHLhq+02bNqFv377QaDQYOHAgvv32W4vtgiBgyZIlCAkJgaurK+Lj43H27FlrngIRERE5EMkD0KefforExEQsXboUhw4dwqBBg5CQkIDi4uIW2//888+YNWsWHnjgAWRkZGDq1KmYOnUqjh07JrZZsWIFVq1ahTVr1mD//v1wc3NDQkIC6uo67/HxRERE5LgkvwssNjYWI0aMwBtvvAEAMJvNCAsLw2OPPYZFixY1az9jxgxUV1fjm2++EdeNGjUKgwcPxpo1ayAIAkJDQ/HUU0/h6aefBgBUVlYiKCgIycnJmDlz5jVr4l1gREREjsdh7gIzGo1IT09HfHy8uE4ulyM+Ph5paWkt7pOWlmbRHgASEhLE9ufPn0dhYaFFGy8vL8TGxrZ6TCIiInIuSil/eWlpKUwmE4KCgizWBwUF4dSpUy3uU1hY2GL7wsJCcXvTutba/J7BYIDBYBCXdTpd+06EiIiIHIrkc4DswfLly+Hl5SV+wsLCpC6JiIiIrEjSAOTv7w+FQoGioiKL9UVFRQgODm5xn+Dg4Ku2b/rf9hwzKSkJlZWV4ic3N/e6zoeIiIgcg6QBSKVSYdiwYUhJSRHXmc1mpKSkIC4ursV94uLiLNoDwM6dO8X2kZGRCA4Otmij0+mwf//+Vo+pVqvh6elp8SEiIqKuS9I5QACQmJiIOXPmYPjw4Rg5ciRWrlyJ6upqzJs3DwAwe/ZsdOvWDcuXLwcAPP744xg7diz+85//YPLkydiwYQMOHjyI//3vfwAAmUyGJ554Ai+++CJ69+6NyMhILF68GKGhoZg6dapUp0lERER2RPIANGPGDJSUlGDJkiUoLCzE4MGDsX37dnESc05ODuTyyx1Vo0ePxscff4x//vOfePbZZ9G7d29s2bIFAwYMENs888wzqK6uxkMPPYSKigrcdNNN2L59OzQajc3Pj4iIiOyP5M8Bskd8DhAREZHjac/3t+Q9QPaoKRPydngiIiLH0fS93Za+HQagFlRVVQEAb4cnIiJyQFVVVfDy8rpqGw6BtcBsNiM/Px8eHh6QyWSdemydToewsDDk5uZyeM2KeJ1tg9fZNnidbYPX2TaseZ0FQUBVVRVCQ0Mt5g+3hD1ALZDL5ejevbtVfwdvt7cNXmfb4HW2DV5n2+B1tg1rXedr9fw04ZOgiYiIyOkwABEREZHTYQCyMbVajaVLl0KtVktdSpfG62wbvM62wetsG7zOtmEv15mToImIiMjpsAeIiIiInA4DEBERETkdBiAiIiJyOgxARERE5HQYgGxo9erViIiIgEajQWxsLA4cOCB1SQ5lz549uOOOOxAaGgqZTIYtW7ZYbBcEAUuWLEFISAhcXV0RHx+Ps2fPWrS5dOkS7r33Xnh6esLb2xsPPPAA9Hq9Dc/C/i1fvhwjRoyAh4cHAgMDMXXqVJw+fdqiTV1dHR555BH4+fnB3d0d06ZNQ1FRkUWbnJwcTJ48GVqtFoGBgfjb3/6GhoYGW56KXXvrrbcQExMjPgwuLi4O27ZtE7fzGlvHSy+9BJlMhieeeEJcx2vdcc899xxkMpnFp2/fvuJ2u7zGAtnEhg0bBJVKJaxdu1Y4fvy4MH/+fMHb21soKiqSujSH8e233wr/+Mc/hM2bNwsAhC+++MJi+0svvSR4eXkJW7ZsEQ4fPiz88Y9/FCIjI4Xa2lqxzcSJE4VBgwYJ+/btE3788UchKipKmDVrlo3PxL4lJCQI77//vnDs2DEhMzNTuO2224Tw8HBBr9eLbR5++GEhLCxMSElJEQ4ePCiMGjVKGD16tLi9oaFBGDBggBAfHy9kZGQI3377reDv7y8kJSVJcUp26auvvhK2bt0qnDlzRjh9+rTw7LPPCi4uLsKxY8cEQeA1toYDBw4IERERQkxMjPD444+L63mtO27p0qVC//79hYKCAvFTUlIibrfHa8wAZCMjR44UHnnkEXHZZDIJoaGhwvLlyyWsynH9PgCZzWYhODhYeOWVV8R1FRUVglqtFj755BNBEAThxIkTAgDhl19+Edts27ZNkMlkQl5ens1qdzTFxcUCAGH37t2CIDReVxcXF2HTpk1im5MnTwoAhLS0NEEQGsOqXC4XCgsLxTZvvfWW4OnpKRgMBtuegAPx8fER3n33XV5jK6iqqhJ69+4t7Ny5Uxg7dqwYgHitO8fSpUuFQYMGtbjNXq8xh8BswGg0Ij09HfHx8eI6uVyO+Ph4pKWlSVhZ13H+/HkUFhZaXGMvLy/ExsaK1zgtLQ3e3t4YPny42CY+Ph5yuRz79++3ec2OorKyEgDg6+sLAEhPT0d9fb3Fte7bty/Cw8MtrvXAgQMRFBQktklISIBOp8Px48dtWL1jMJlM2LBhA6qrqxEXF8drbAWPPPIIJk+ebHFNAf577kxnz55FaGgoevbsiXvvvRc5OTkA7Pca82WoNlBaWgqTyWTxhwWAoKAgnDp1SqKqupbCwkIAaPEaN20rLCxEYGCgxXalUglfX1+xDVkym8144okncOONN2LAgAEAGq+jSqWCt7e3RdvfX+uW/hZN26jR0aNHERcXh7q6Ori7u+OLL75Av379kJmZyWvciTZs2IBDhw7hl19+abaN/547R2xsLJKTkxEdHY2CggIsW7YMY8aMwbFjx+z2GjMAEVGrHnnkERw7dgx79+6VupQuKTo6GpmZmaisrMRnn32GOXPmYPfu3VKX1aXk5ubi8ccfx86dO6HRaKQup8uaNGmS+HNMTAxiY2PRo0cPbNy4Ea6urhJW1joOgdmAv78/FApFsxnvRUVFCA4OlqiqrqXpOl7tGgcHB6O4uNhie0NDAy5dusS/QwseffRRfPPNN/jhhx/QvXt3cX1wcDCMRiMqKios2v/+Wrf0t2jaRo1UKhWioqIwbNgwLF++HIMGDcJrr73Ga9yJ0tPTUVxcjKFDh0KpVEKpVGL37t1YtWoVlEolgoKCeK2twNvbG3369EFWVpbd/ntmALIBlUqFYcOGISUlRVxnNpuRkpKCuLg4CSvrOiIjIxEcHGxxjXU6Hfbv3y9e47i4OFRUVCA9PV1ss2vXLpjNZsTGxtq8ZnslCAIeffRRfPHFF9i1axciIyMttg8bNgwuLi4W1/r06dPIycmxuNZHjx61CJw7d+6Ep6cn+vXrZ5sTcUBmsxkGg4HXuBONHz8eR48eRWZmpvgZPnw47r33XvFnXuvOp9frce7cOYSEhNjvv2erTK2mZjZs2CCo1WohOTlZOHHihPDQQw8J3t7eFjPe6eqqqqqEjIwMISMjQwAgvPrqq0JGRoZw4cIFQRAab4P39vYWvvzyS+HIkSPClClTWrwNfsiQIcL+/fuFvXv3Cr179+Zt8L+zYMECwcvLS0hNTbW4pbWmpkZs8/DDDwvh4eHCrl27hIMHDwpxcXFCXFycuL3pltZbb71VyMzMFLZv3y4EBATwtuErLFq0SNi9e7dw/vx54ciRI8KiRYsEmUwm7NixQxAEXmNruvIuMEHgte4MTz31lJCamiqcP39e+Omnn4T4+HjB399fKC4uFgTBPq8xA5ANvf7660J4eLigUqmEkSNHCvv27ZO6JIfyww8/CACafebMmSMIQuOt8IsXLxaCgoIEtVotjB8/Xjh9+rTFMcrKyoRZs2YJ7u7ugqenpzBv3jyhqqpKgrOxXy1dYwDC+++/L7apra0VFi5cKPj4+AharVa48847hYKCAovjZGdnC5MmTRJcXV0Ff39/4amnnhLq6+ttfDb26/777xd69OghqFQqISAgQBg/frwYfgSB19iafh+AeK07bsaMGUJISIigUqmEbt26CTNmzBCysrLE7fZ4jWWCIAjW6VsiIiIisk+cA0REREROhwGIiIiInA4DEBERETkdBiAiIiJyOgxARERE5HQYgIiIiMjpMAARERGR02EAIiIiIqfDAEREDqukpAQLFixAeHg41Go1goODkZCQgJ9++gkAIJPJsGXLFmmLJCK7pJS6ACKi6zVt2jQYjUasW7cOPXv2RFFREVJSUlBWViZ1aURk5/gqDCJySBUVFfDx8UFqairGjh3bbHtERAQuXLggLvfo0QPZ2dkAgC+//BLLli3DiRMnEBoaijlz5uAf//gHlMrG/08ok8nw5ptv4quvvkJqaipCQkKwYsUK3H333TY5NyKyPg6BEZFDcnd3h7u7O7Zs2QKDwdBs+y+//AIAeP/991FQUCAu//jjj5g9ezYef/xxnDhxAm+//TaSk5Pxr3/9y2L/xYsXY9q0aTh8+DDuvfdezJw5EydPnrT+iRGRTbAHiIgc1ueff4758+ejtrYWQ4cOxdixYzFz5kzExMQAaOzJ+eKLLzB16lRxn/j4eIwfPx5JSUniug8//BDPPPMM8vPzxf0efvhhvPXWW2KbUaNGYejQoXjzzTdtc3JEZFXsASIihzVt2jTk5+fjq6++wsSJE5GamoqhQ4ciOTm51X0OHz6M559/XuxBcnd3x/z581FQUICamhqxXVxcnMV+cXFx7AEi6kI4CZqIHJpGo8GECRMwYcIELF68GA8++CCWLl2KuXPntther9dj2bJluOuuu1o8FhE5B/YAEVGX0q9fP1RXVwMAXFxcYDKZLLYPHToUp0+fRlRUVLOPXH75P4n79u2z2G/fvn244YYbrH8CRGQT7AEiIodUVlaGe+65B/fffz9iYmLg4eGBgwcPYsWKFZgyZQqAxjvBUlJScOONN0KtVsPHxwdLlizB7bffjvDwcNx9992Qy+U4fPgwjh07hhdffFE8/qZNmzB8+HDcdNNN+Oijj3DgwAG89957Up0uEXUyToImIodkMBjw3HPPYceOHTh37hzq6+sRFhaGe+65B88++yxcXV3x9ddfIzExEdnZ2ejWrZt4G/x3332H559/HhkZGXBxcUHfvn3x4IMPYv78+QAaJ0GvXr0aW7ZswZ49exASEoKXX34Z06dPl/CMiagzMQAREf1OS3ePEVHXwjlARERE5HQYgIiIiMjpcBI0EdHvcGYAUdfHHiAiIiJyOgxARERE5HQYgIiIiMjpMAARERGR02EAIiIiIqfDAEREREROhwGIiIiInA4DEBERETkdBiAiIiJyOv8Pl2pmqdjteb8AAAAASUVORK5CYII=\n"
},
"metadata": {}
}
],
"source": [
"# --- Plotting Results ---\n",
"plt.figure()\n",
"plt.title(\"Training Loss\")\n",
"plt.plot(losses)\n",
"plt.xlabel(\"Step\")\n",
"plt.ylabel(\"MSE Loss\")"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "f780e782",
"metadata": {
"id": "f780e782",
"outputId": "3f32dc47-64c8-404f-fd2d-26825e6ea7a4",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 312
}
},
"outputs": [
{
"output_type": "display_data",
"data": {
"text/plain": [
""
],
"image/png": "iVBORw0KGgoAAAANSUhEUgAAA+cAAAEnCAYAAADLiTIhAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjAsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvlHJYcgAAAAlwSFlzAAAPYQAAD2EBqD+naQABAABJREFUeJzs3XV4VFf6wPHvHcvE3T0hCRLc3aFQqFP7VajuVql3u1Xabl23u3XdulCBtkBxiruTEHd3m2Tk/v64SSAkocjcSQLn8zw8JDN35pyZ3Jl7zz3veV9JlmUZQRAEQRAEQRAEQRC6jKarOyAIgiAIgiAIgiAI5zoxOBcEQRAEQRAEQRCELiYG54IgCIIgCIIgCILQxcTgXBAEQRAEQRAEQRC6mBicC4IgCIIgCIIgCEIXE4NzQRAEQRAEQRAEQehiYnAuCIIgCIIgCIIgCF1MDM4FQRAEQRAEQRAEoYuJwbkgCIIgCIIgCIIgdDExOBcEQRCEv7B27VokSWLt2rVd3RWhB3jqqaeQJKnNbVFRUcyfP99ubcyfP5+oqCi7PZ8gCILQ9cTgXBAEQTgjn376KZIkdfpvy5YtXd3FbqmkpIQFCxbQu3dvnJ2dCQgIYMSIETz88MPU1tZ2dfd6tGP3P41GQ0hICDNmzOhxF1fy8/N56qmn2LNnT1d3RRAEQXAAXVd3QBAEQTg7PP3000RHR7e7vVevXl3Qm+6tvLycYcOGUV1dzY033kjv3r0pKytj3759vPPOO9x22224ubl1dTd7tOnTp3PdddchyzIZGRm8/fbbTJkyhd9++41Zs2Y5vD/JycloNKc2J5Kfn8/ChQuJiopi0KBBbe774IMPsNlsduyhIAiC0NXE4FwQBEGwi1mzZjFs2LCu7kaP8NFHH5Gdnc3GjRsZM2ZMm/uqq6sxGAxd1LOzR3x8PNdcc03r7xdffDEDBgzgjTfe6HRwbjKZMBgMpzyIPhlOTk52fT69Xm/X5xMEQRC6nghrFwRBEBziySefRKPRsGrVqja333rrrRgMBvbu3QtAU1MTTzzxBEOHDsXT0xNXV1fGjx/PmjVr2jwuMzMTSZJ45ZVX+O9//0tMTAwuLi7MmDGDnJwcZFnmmWeeISwsDGdnZy688ELKy8vbPEdUVBRz5szhjz/+YNCgQRiNRvr27cuPP/54Uq9p69atnHfeeXh6euLi4sLEiRPZuHHjXz4uLS0NrVbLqFGj2t3n4eGB0Wg8rXY2bNjA8OHDMRqNxMbG8t5777Vb/9zyvn366aftHi9JEk899VSb2/Ly8rjxxhsJDAzEycmJfv368fHHH7fZpmVN/nfffce//vUvwsLCMBqNTJ06ldTU1HbtbN26ldmzZ+Pt7Y2rqysDBgzgzTffbLNNUlISl112GT4+PhiNRoYNG8bixYvbPdfJ6t+/P35+fmRkZLTp8zfffMNjjz1GaGgoLi4uVFdXt/bxdN/zjnS05ryyspJ7772XqKgonJycCAsL47rrrqO0tJS1a9cyfPhwAG644YbWMP2Wv1tHa87r6uq4//77CQ8Px8nJiYSEBF555RVkWW6znSRJ3Hnnnfz8888kJia2/l2XLVt2qm+rIAiCYEdi5lwQBEGwi6qqKkpLS9vcJkkSvr6+ADz22GMsWbKEm266if379+Pu7s7y5cv54IMPeOaZZxg4cCCgzBx/+OGHXHXVVdxyyy3U1NTw0UcfMXPmTLZt29YuvPfLL7+kqamJu+66i/Lycl566SUuv/xypkyZwtq1a3n44YdJTU3lrbfe4oEHHmg3sExJSeGKK67g73//O9dffz2ffPIJ8+bNY9myZUyfPr3T17t69WpmzZrF0KFDWy88fPLJJ0yZMoU///yTESNGdPrYyMhIrFYrn3/+Oddff/0J39eTbWf//v3MmDEDf39/nnrqKSwWC08++SSBgYEnfP4TKSoqYtSoUa2DOX9/f5YuXcpNN91EdXU199xzT5vtX3jhBTQaDQ888ABVVVW89NJL/N///R9bt25t3WbFihXMmTOH4OBgFixYQFBQEIcPH+bXX39lwYIFABw8eJCxY8cSGhrKP/7xD1xdXfnuu++46KKLWLRoERdffPEpv5aKigoqKiraLbN45plnMBgMPPDAAzQ2NmIwGBzyntfW1jJ+/HgOHz7MjTfeyJAhQygtLWXx4sXk5ubSp08fnn76aZ544gluvfVWxo8fD9Au0qKFLMtccMEFrFmzhptuuolBgwaxfPlyHnzwQfLy8nj99dfbbL9hwwZ+/PFHbr/9dtzd3fn3v//NpZdeSnZ2dutnVhAEQXAwWRAEQRDOwCeffCIDHf5zcnJqs+3+/ftlg8Eg33zzzXJFRYUcGhoqDxs2TDabza3bWCwWubGxsc3jKioq5MDAQPnGG29svS0jI0MGZH9/f7mysrL19kceeUQG5IEDB7Z53quuuko2GAyyyWRqvS0yMlIG5EWLFrXeVlVVJQcHB8uDBw9uvW3NmjUyIK9Zs0aWZVm22WxyXFycPHPmTNlms7VuV19fL0dHR8vTp08/4XtWWFgo+/v7y4Dcu3dv+e9//7v81VdftXkdp9rORRddJBuNRjkrK6v1tkOHDslarVY+9nDf8r598skn7foFyE8++WTr7zfddJMcHBwsl5aWttnuyiuvlD09PeX6+vo270+fPn3a/O3efPNNGZD3798vy7Lyt42OjpYjIyPlioqKdq+1xdSpU+X+/fu3+VvZbDZ5zJgxclxcXLt+d/Q6brrpJrmkpEQuLi6Wt27dKk+dOlUG5FdffbVNn2NiYlpfR0s79n7PZVnZ166//vrW35944gkZkH/88cd2/W9pd/v27Z3+ra6//no5MjKy9feff/5ZBuRnn322zXaXXXaZLEmSnJqa2ub9MRgMbW7bu3evDMhvvfVWu7YEQRAExxBh7YIgCIJd/Pe//2XFihVt/i1durTNNomJiSxcuJAPP/yQmTNnUlpaymeffYZOdzSQS6vVtq65ttlslJeXY7FYGDZsGLt27WrX7rx58/D09Gz9feTIkQBcc801bZ535MiRNDU1kZeX1+bxISEhbWZiPTw8uO6669i9ezeFhYUdvtY9e/aQkpLC1VdfTVlZGaWlpZSWllJXV8fUqVNZv379CZN1BQYGsnfvXv7+979TUVHBu+++y9VXX01AQADPPPNMaxjyybZjtVpZvnw5F110EREREa3t9OnTh5kzZ3bajxORZZlFixYxd+5cZFlubbu0tJSZM2dSVVXV7u9xww03tFkv3zLbm56eDsDu3bvJyMjgnnvuwcvLq81jW0Lvy8vLWb16NZdffjk1NTWtbZaVlTFz5kxSUlLa/Q078tFHH+Hv709AQAAjR45k48aN3Hfffe1m+6+//nqcnZ1bf3fUe75o0SIGDhzYYRTA8WXYTsbvv/+OVqvl7rvvbnP7/fffjyzL7T6L06ZNIzY2tvX3AQMG4OHh0fq3EgRBEBxPhLULgiAIdjFixIiTSgj34IMP8s0337Bt2zaee+45+vbt226bzz77jFdffZWkpCTMZnPr7R1lgz92YAS0DtTDw8M7vL2ioqLN7b169Wo3GIqPjweU9dlBQUHt2kxJSQE4YUh6VVUV3t7end4fHBzMO++8w9tvv01KSgrLly/nxRdf5IknniA4OJibb775pNtpbGykoaGBuLi4dvcnJCTw+++/d/r4zpSUlFBZWcn777/P+++/3+E2xcXFbX4//m/R8vpb3vO0tDRAuUjTmdTUVGRZ5vHHH+fxxx/vtN3Q0NAT9v/CCy/kzjvvRJIk3N3d6devH66uru22O36fctR7npaWxqWXXnrCbU5FVlYWISEhuLu7t7m9T58+rfcf6/i/FSh/r+M/H4IgCILjiMG5IAiC4FDp6emtA6D9+/e3u/+LL75g/vz5XHTRRTz44IMEBASg1Wp5/vnnWwd3x9JqtR2209nt8nHJsU5Hy6z4yy+/3G4NfIuTLYUmSRLx8fHEx8dz/vnnExcXx5dffsnNN9980u00NjaedN87m5W1Wq1tfm9p+5prrul0oDpgwIA2v9vjPW9p94EHHuh0BvpkyvOFhYUxbdq0v9zu2FnzY9u353veHan5+RAEQRBOjxicC4IgCA5js9mYP38+Hh4e3HPPPTz33HNcdtllXHLJJa3b/PDDD8TExPDjjz+2GUg++eSTqvSpZab22LaOHDkC0C4bdouWcGAPD4+TGgCerJiYGLy9vSkoKDildvz9/XF2dm696HGs5OTkNr+3zGZXVla2uf34mVV/f3/c3d2xWq12e40tr+fAgQOdPmdMTAyglAqz53t7stR4zztr58CBAyfc5lTC2yMjI1m5ciU1NTVtZs+TkpJa7xcEQRC6N7HmXBAEQXCY1157jU2bNvH+++/zzDPPMGbMGG677bY2Wd5bZvSOncHbunUrmzdvVqVP+fn5/PTTT62/V1dX87///Y9BgwZ1GNIOMHToUGJjY3nllVeora1td39JSckJ29y6dSt1dXXtbt+2bRtlZWUkJCScUjtarZaZM2fy888/k52d3Xr/4cOHWb58eZvHeHh44Ofnx/r169vc/vbbb7f5XavVcumll7Jo0aIOB5F/9Ro7MmTIEKKjo3njjTfaXRxo+XsHBAQwadIk3nvvvdaLFGfa7qlQ4z3vyKWXXsrevXvb7HstWt6LljD849+rjsyePRur1cp//vOfNre//vrrSJLUaW13QRAEofsQM+eCIAiCXSxdurR1lu5YY8aMISYmhsOHD/P4448zf/585s6dC8Cnn37KoEGDuP322/nuu+8AmDNnDj/++CMXX3wx559/PhkZGbz77rv07du3w8HSmYqPj+emm25i+/btBAYG8vHHH1NUVMQnn3zS6WM0Gg0ffvghs2bNol+/ftxwww2EhoaSl5fHmjVr8PDwYMmSJZ0+/vPPP+fLL7/k4osvZujQoRgMBg4fPszHH3+M0Wjkn//85ym3s3DhQpYtW8b48eO5/fbbsVgsvPXWW/Tr1499+/a1af/mm2/mhRde4Oabb2bYsGGsX7++NVrgWC+88AJr1qxh5MiR3HLLLfTt25fy8nJ27drFypUr29WN/ysajYZ33nmHuXPnMmjQIG644QaCg4NJSkri4MGDrYPa//73v4wbN47+/ftzyy23EBMTQ1FREZs3byY3N5e9e/eeUrun2kc13vPjPfjgg/zwww/MmzePG2+8kaFDh1JeXs7ixYt59913GThwILGxsXh5efHuu+/i7u6Oq6srI0eO7DD3wty5c5k8eTKPPvoomZmZDBw4kD/++INffvmFe+65p03yN0EQBKGb6pok8YIgCMLZ4kSl1GguA2WxWOThw4fLYWFh7cqFtZTb+vbbb2VZVspIPffcc3JkZKTs5OQkDx48WP7111/blY5qKQn28ssvt3m+lhJZ33//fYf93L59e+ttkZGR8vnnny8vX75cHjBggOzk5CT37t273WOPL6XWYvfu3fIll1wi+/r6yk5OTnJkZKR8+eWXy6tWrTrhe7Zv3z75wQcflIcMGSL7+PjIOp1ODg4OlufNmyfv2rWr3fYn2866devkoUOHygaDQY6JiZHfffdd+cknn2xX1qu+vl6+6aabZE9PT9nd3V2+/PLL5eLi4nal1GRZlouKiuQ77rhDDg8Pl/V6vRwUFCRPnTpVfv/99//yPe+sbNuGDRvk6dOny+7u7rKrq6s8YMCAdiW80tLS5Ouuu04OCgqS9Xq9HBoaKs+ZM0f+4YcfTvjeyrJSKuyOO+444Tad9bmFvd/z40upybIsl5WVyXfeeaccGhoqGwwGOSwsTL7++uvblK775Zdf5L59+8o6na7Ne3n850GWZbmmpka+99575ZCQEFmv18txcXHyyy+/3KYk3Inen476KAiCIDiOJMsi84cgCIJwboqKiiIxMZFff/21q7uimqeeeoqFCxeKRF+CIAiC0M2JNeeCIAiCIAiCIAiC0MXE4FwQBEEQBEEQBEEQupgYnAuCIAiCIAiCIAhCFxNrzgVBEARBEARBEAShi/WYmfN33nmHAQMG4OHhgYeHB6NHj2bp0qVd3S1BEARBEARBEARBOGM9ZuZ8yZIlaLVa4uLikGWZzz77jJdffpndu3fTr1+/ru6eIAiCIAiCIAiCIJy2HjM474iPjw8vv/wyN91000ltb7PZyM/Px93dHUmSVO6dIAiCIAiCIAiCcK6TZZmamhpCQkLQaDoPXtc5sE92Y7Va+f7776mrq2P06NGdbtfY2EhjY2Pr73l5efTt29cRXRQEQRAEQRAEQRCEVjk5OYSFhXV6f48anO/fv5/Ro0djMplwc3Pjp59+OuFg+/nnn2fhwoXtbt+1axdubm5qdvWM2Gw2qqur8fDwOOGVFeHcIfYJ4XhinxCOJ/YJoSNivxCOJ/YJ4Xhin1BfbW0tQ4YMwd3d/YTb9aiw9qamJrKzs6mqquKHH37gww8/ZN26dZ0O0I+fOa+uriY8PJyKigo8PDwc1e1TZrPZKCkpwd/fX3xABEDsE0J7Yp8Qjif2CaEjYr8Qjif2CeF4Yp9QX3V1Nd7e3lRVVZ1wHNqjZs4NBgO9evUCYOjQoWzfvp0333yT9957r8PtnZyccHJyane7RqPp9jueJEk9op+C44h9Qjie2CeE44l9QuiI2C+E44l9Qjie2CfUdbLva49+9202W5uZcUEQBEEQBEEQBEHoiXrMzPkjjzzCrFmziIiIoKamhq+++oq1a9eyfPnyru6aIAiCIAiCIAiCIJyRHjM4Ly4u5rrrrqOgoABPT08GDBjA8uXLmT59eld3TRAEQRAEQRAEQRDOSI8ZnH/00Udd3QVBEARBEARBEARBUEWPGZwLgiAIgiD0dE0WG59szECS4NpRUTgbtF3dJUEQBKGbEINz4Zxhs8nYZBmdtkfnQRQEQRB6qLpGC8/+dogDedUA7M2p4p/n9yHUy7mLeyYIgiB0B2JwLpxVmiw2Pt6YQXJhDY0WKyazjUaLlUazjUaLDUmCYZE+XD8mkkhf167uriAIgnCOqKxv4snFB0kvqcNZr8VJryG7vJ57v93D/dPjGRnj29VdFARBELqYGJwLZw2bTebVFclsSi3rdBtZhu2Z5ezMKmdK70CuHhmBv7uTA3spCIIgnGuKq008/ssB8itNeDrreeqCfvi4GnhxaRKHCqp59rfDXD48nP8bEYFGI3V1dwVBEIQuIgbnwllBlmXe/zOdTallaDUSd0zuRbCnESedBiedMkPhpNNQ3WDhy61ZbEorY+XhItYdKWbuwBAuGxqGu1Hf1S9DEARBOMtkl9XzxOIDlNU24e/uxDMXJbaGsf/r4kQ+3pjBkr0FfLc9h9SiGh6YmSCOR4IgCOcoMTgXzgrf78zlt30FANw3PZ4J8f4dbuflYuCR2X1IKqzms02ZHMir5sddeSw/WMgVw8O5cGComLUQBEEQ7CK5sIanFh+kttFChI8LCy/sh5/b0WgtnVbDrRNiiQt05z+rU9mVXcm93+7hsfP7EuUnll4JgiCca0RmLKHHW3moiM83ZwFw8/joTgfmx+od5MFzF/fnibl9ifB1oa7RyscbMvlpd57a3RUEQRDOAftyK3ns5/3UNlqID3Tn+Uv7txmYH2tyQgCvzBtIoIeRoupGnv3tMCaz1cE9FgRBELqaGJwLPdqOzHLeWp0CwCVDQrlwUOhJP1aSJIZH+fDWlYO5fkwUAJ9vySK1uEaNrgqCIAjniJKaRp7/PQmT2cagcC+evSgRj78IVY/2c+X1Kwbi62agqNrEZ5syT64xqwXWvQwb3gBLU7u76831yLJ86i9CEARBcDgxOBd6rOTCGl5YmoRNhsm9A5jfPMA+VRqNxKVDQhkT64vVJvPK8iNixkIQBEE4LRarjZeWJVHbaKFXgBuPz+l70rXM3Y167p4aB8Cv+wrYn1v11w/a9y0k/QoHf4LVz4DNyr6SfXyw7wPuXn03N/1xE5+lfobVJo5rgiAI3Z0YnAs9Ul5lAwuXHKTRYmNIhBd3T+mFJJ3+WnFJkrhzSi983QzkVTbw0YYMO/ZWEARBOFd8sSWLpMIanA1aHj6vNwbdqZ1qDYnwZma/QADeXHWEhqYTDKorc2DnpxyRLDRKQMZ6WPci+4r3sjJ7JUX1RQBsK93Gu/vexSbbTvdlCYIgCA4gBudCj2Ozyby4NIkak4W4ADf+MasPOu2Z78ruRj33TotHkmDZgUK2pHdekq1Tsgz15VCcBKWpyu+CIAjCOWFnVjmLdim5S+6ZGkeQp/G0nufGcdH4uztRVN3IZ5szO95IluHPV6m0mljoKpE08iaQNHBkOcMLk5kdPZuHhj/EnYPuRIOGDXkbeHevGKALgiB0ZyJbu9DjrEkuJqO0DheD9pTCBU/GwHAvLh4cyo+78vj3qhTiAtzw7SSBD2aTEkpYkQE1RVBbCLXFYGk8uk3oUBh1G/jF2a2PgiAIQvdTWtvIayuOAHD+gGDG9PI77edyMei4e2ocj/98gN/2FTAm1pcBYV5tN0peCvm72aIHi1sASxvzGTj5UVjzLAmpf5LgFgH9hmKz2aipruF/Gf9jXe46xoeOp79/f2iqg4ZK8Dz5XC2CIAiCusTMudCjmMxWPt+iZGa/fFg43q4Gu7fxfyMjifF3pcZk4Y2VKdhsHcx+yzJ7l9/PndufY3vST5C7XQkvtDSCJIGrH2j1kLcTfrwFVv8Lagrt3ldBEASh6yn5SpKpbrAQ4+/KjWOjz/g5B4V7cV5iEAD/XpXSNry9vhy2vA3AWu8ISuptNNaFQNw0GHefss2eL2HX5wAM8R3CnYPu5Ia+19O/vgZWPgX/uwi+uVoZ5AuCIAjdgpg5F3qUX/bkUVbbRIC7E3MHhqjShkGn4YEZCdzz7R725FSyZF9+uyzwZQe+46WSjYShIzrxcvCJB/dAcAsCV3/QGaC6ALZ/CKkrIeUPSF8LiZfC4P8DJ3dV+i4IgiA43ldbsziYX42z/vTWmXfmxrHR7MqqoKi6kU82ZXD7pF7KHZv+TUNdJbtsAawsr0SWYMtBX4qHmgjoewGYG5TB+/YPQWdEpwtiTNkONOlrwKQkmWtAxghI618Bj1AIHmCXPguCIAinT8ycCz1GRV0TP+zMBeD6MVF2O/npSLiPCzePU2Y+Pt2USXpJbet9toos3trxGhZA8u2F58g7oPdsJYTdM1QZmAN4BMPUx+Hi9yBkEFibYO/X8PVVsO/7DkveCIIgCD3L7uwKvm8+Nt05pRchXs52e25ng7Y1e/vS/YXsyankyLZl5O78nZzyRl7XJCJL4EwoOtmTLRnlygMHXgFD5wMgbf4PnmseRjr0szIwd/ampu8FLIxJ5EP/YFJkE1V//BO5Kt9u/RYEQRBOjxicCz3GV9uyMZltxAW6MT7u9NfynazzEoMYEe2DxSrz0rJkakxmsJr5afndHKYRo8GdBVNeRa/VY7FZKKzrJGw9oDfMeQPOewG8o6CxBjb/B767DlJXgU0k5xEEQeiJssvqeW3FEWRZOWZMiPe3exsDw72Y3T8YgOd+2Un1ipdpaLKyzjgZAmqJ8HFhevR4gLaJTIfOhwFXACBrDBA7FWa9BNcs4nCv8WQ2lrNSb+MxZyu32nK5dvEl3Lf6bp7f+jyHyg7Z/XUIgiAIf00MzoUeIbusnj8OKoPfG8dGn1HZtJMlSRJ3T4lrLa/23O9JHFz/Aj80ZIGk5aYRDxHsHkpBbQH/+PMfPLf1OZqsncyGSxJEjobLPoaJD4GLL9QUwKqn4efbIH+P6q9HEARBsA+bTeaXPXnc8+1uKuvNRPm5cvP4M19n3pn5Y6II9HBiVv0SvOUq9N6hTL72DnTO+Rh0Gi7vNxmAg3lVVJvMyoMkCUbdhnzJh5TP+QR5ymMQMRI0WkYEj2DBkAX09u2Lj38/JI0Os8VEXsEu9hTv6fxYJgg9TF2jhaX7C9iQUqpMsghCNyfWnAs9wscbM7DJMDrWl8RQT4e16+mi58m5/Xj4h33UZG3ktdJF2PQwPmIKE+LmAuBl9KLWXEuFqYKfU3/m8oTLO39CjRZ6nw+xU2Dfd7D3GyhJgiULIHIMjLgVfNQ7wRMEQRDOTElNI2+uOsLeHGXt9tBIbxZMjcNJZ7/KIcdzNmh5cZwG3a/bcfVwQTfnSUo8XJgcPpnKxkr6BIQR7VdCRmkd2zPKmdpHqZOOJIFvLBQXt3vO0SGjGR0yGgBzwT7KfruH0rpGSgKjifYUxyGh59uRWc5/1qRSVqtcbNJIEBfozpAIb4ZEehEf4I5Go/5kjyCcCjFzLnR7e3Iq2ZlVgUYjcf2YKHUaOfIH/PE4pKxstxY82s+VR6eFMlD+gjJsOGv8uGnC0633O+ucmd9vPgC/pP1Cfu2J1+2VNpRShw2GXg9Xfgn9LlJq02Ztgh9uVPoiCIIgdDtrk4u586td7M2pwqDTcNukWJ6c21eVyiHH8z34GZ5GHbresyFsKP4u/vxt4N94eMTDAIyK8QVgc1rZiZ6mQ/rgAQRNfIREWcfktM14Zm1FlmX2l+yntKHUrq9DENRWYzLzxsojLFxyiLLaJgI9nAj3ccYmQ3JhDV9vy+bB7/fxfx9u5Y2VR9pWQhCELiZmzoVuzWaT+XhDBgDn9w8i1I6JdloVJ8G6F8BmhYz1Sib1uBnQZw74xIAsMzDjQ6K1MvpqXxYZb2BdUhXnJR7ty8igkQzyH8Sekj18tP8jHhv1WLvQ+zpzHV8nfc3KrJX4O/vz/PjncXPxgXH3Klnct7yjDNA3vwURo8DoYf/XKgh2VFnfxK/7Cugd5M7QSG+HLDcRhK5QYzLzzto0/kxRBqpxgW7cPyNBnWNSR+pKoXCf8vPQGzrcZFSMD19vy2Z3TiUmsxWj/hRn8uOmQ0Um7P4C1r/E5xV7+K1kJ9MipnHLgFvOrP+C4CDbMsr575pUyuuakCS4YGAI14yKxKjXUlxjYnd2JbuyK9ibU0lto4VVh4vxctYz3w7lDwXBHsTMudCtrUkuJqO0DheDliuGR9i/AbMJ1jyrDMz9e4NbgJKw7cAi+P4G+Pl22PgGpK/Dw8UJv0FPgBzJO2tT2ZlV3vo0kiRxY+KN6DV6DpQdYGP+xtb7ZFlmQ94G7l1zLyuyViAjU9xQzA9HfjjaD68ImPGskjDOVA27/mf/1yoIdlRUbeLhRfv4dnsOC5cc4q6vd7MmuRirTe7qrgmCXdlsMv/4cT9/ppSikeDqkRG8fNlAxw3MATLWgSxDYD9wDySpPIkjFUeQ5aOft2g/VwI9nGiy2NidXXl67Qy7CaLGgdXMiOR1YLOyJmcNxfXtw+JPhizLfHn4S3Kqc06vP4JwkmpMZl77I5lnfj1EeV0TIV5GXrx0ADePj2m9UBXgbmRmvyAemdWHL28exZ1TlNKEyw4WitlzodsQg3Oh2zKZrXy+JQuAy4eF4+mst38jW9+FyhwlQdvsl+Cqb5VsttETQKPFXHSA95K+pgwbDLuJ86dOYkrvAGwyvLA0idTioyXWAl0DuTTuUgD+d/B/1DbVUlBbwL+2/ou3dr9FVVMVoW6h3JB4A5PCJrVfm67Rwug7lZ8P/giV2fZ/vYJgB9ll9Tz0wz7yK014uxpw1mvJKqvntT+O8LfPd/DrvnxMZnGiI5wdMsvqyC6rx6jX8Mq8gVw1IgKto9eppq9V/o9REr99k/QNj298nBVZK1o3kSTpaGh7+qmHtgOg0cDkR8ErnN4NtfQ327DKVn5K+em0nm5d7joWpy3m8U2PU2+ub3MxQRDspbjGxD3f7GFNcgkaCS4eHMq/rxpMn+DOIxC1GonpfQIJ8TJS12hlxeEiB/ZYEDonBudCt1RZ38TCJQcpq20iwN2JuQND7N9I9lY42HzCMekRMHoqJyYRI2HGM/B/P7AsfjyrnSSe83bDNuAKJEnizim9GBjuiclsY+GSgxTXmFqfck7MHELdQgl1D8VkNZFTk8P+0v3oNXquTLiSFye8yHlR53HboNtw0bu071P4cCUxnM0Km9+2/2sWhDN0uKCahxfto7yuiQgfF167fCAfzR/GtaMi8XTWU1TdyHvr0rnps+18tz2HJosoFSj0bIcKqgHoE+xBXKC74ztQVwqF+5WfYyZSbionqTwJgCGBQ9ps2jI4355RfvpRLAYXmPgPkCTmlRVBUx3rcted8ux5WUMZnx38DIBB/oN4bedrvLT9pdPrkyB0orK+icd/PkBxTSNBnkZevGwAN46LPqkEjRqNxIWDQgFYvCcPm4j8EroBMTgXup3U4lru/XYPB/KqcdZrWTAtDoPOzruqqUpZZw6QeIkyKD5Orc7AT00F4B3FnFEPodEqKRr0Wg2PzOpDpK8LlfVm3l2b3voYvVbPE6Oe4IlRT+Dn7MfwoOFcHn85r0x8hYvjLkavaTv7L8syWwu2YpOPGcCMuk2ZRc/eDDnb7Pu6BeEM7Mwq5/GfD1DbaCEhyJ0XLu2Pn5sT7kY9lw8P56P5w/j7xFgCPZyobrDw+ZYs/vnTfkprG7u664Jw2g7lK4PzfiFdlAekNaQ9EdwC2FawDRmZeO94/Jz92mzaJ9gDD2cdtY0WDuRVnX6bQYmQeCkJso4BtVVYbWZ+TPnxpB8uyzLv73ufeks9vbx6cWn8pewv3c++0n00WBpOv1+CcIy6RgtPLj5IfqUJf3cnnru4P72DTu1zOqV3AG5OOoqqG9lyuhEngmBHPWZw/vzzzzN8+HDc3d0JCAjgoosuIjk5uau7JdjZuiMlPLxoH6W1ynqhVy8fyIAwL/s2Isuw/hWoL1fWeo/8e4ebLUpZRJ25jkj3SCaGT2xzn6uTjkdm90EjwfbMco4U1bTe52X0ak2MJUkSl8ZfSpBrUIdt/Hv3v3lt52v8mv7r0Ru9IqDfJcrPm/8LNiuN1kaqm6rP4EULwplZd6SEp389TKPFxtBIb569KBF3Y9uLTU46LecPCOa9a4dx3/R4XJ20JBfWNF9sO4OBgiB0EVmWOdg6OHdcGc820tYo/8dMAmBLwRYARgWParepViMxIkqZPT/jgcbwm8E9mMtMNqgtYV3OOorqTi70d23OWvaU7EGv0XPbwNsIcwsjwCUAi83CgdIDZ9YvQQAaLVae/e0Q6SV1eDrreeaiRPzdnU75eYx6LbP7K+doP+3Os3c3BeGU9ZjB+bp167jjjjvYsmULK1aswGw2M2PGDOrq6rq6a4Id2Gwyn2zM4JXlyTQ1n/y/evkgwn06CP0+U0eWK1nZNVqY8jjo2n+ZF9YV8kemUtLsmr7XoJHaf1RCvZyZ3DsAgC+b18afqgF+AwD4NulbMqoyjt4x5DowemCqyGDxnwu5Y9UdPL77cQ6XHT6tdgThVJmtNvIqG9iZVcHnW7J49Y9kbDaZ8XF+PHp+nxNmgtZqJCb3DuD1Kwa1Rpg8+vMBluzNF2tOhR6lqLqR8romtBqJuEA3x3egtgSKmgezx4W0jwwe2eFDRsX4AMrg/Iw+b3pnmPggCbKOgfW1BGmNVDZW/uXDShtK+eyQEs5+ecLlhLmHIUkSgwMGA7CneM/p90kQAIvVxotLk5UIS4OWhRf2O6MEjXMGhKDTSiQV1nC4QEyECF2rx5RSW7ZsWZvfP/30UwICAti5cycTJkzool4J9lBjMvPqH0fYmVUBwGVDw7h2VCQaNRLuVBfAxjeVn4feAP7xHW72ddLXWGQLg/wHMcB/QKdPd+XwCNYkl7Aru5JD+dX0PcWwx0nhk9hVvItthdt4a/dbvDD+BQxag1JGbdiNfLH5eVZk/AY+0ZhtNv6z5z+8PPFl3AxdcJIonNXSSmpZur+A/CoTRVUmSmsbOX753fkDgrl1fMxJfzaDPZ15Zd5A3lqdwvojpby/Pp2Uohpun9zr1Ms8CUIXOJivRHzEBbid1BpWuzs+pD1jWach7S0GRXhh1GsorW0iraSWGD/X028/dCj0mcsdh3/BvaIBjftfV01ZmrGUBksDcV5xzImZ03r7kIAhLM9czq7iXciyLEovCqfFZpN5c1UK2zPL0WslnpjTl1j/Mzsn8nY1MCk+gJWHi/h5d94JE8kJgtp6zOD8eFVVygHTx8en020aGxtpbDy61rG6WrkaZrPZsNm6b5Iim82GLMvduo/2Yrba+MeifWSV1+Ok1XD31F6Mj/MHZPsn5pBtSGueA3M9BCYiD7wKOniPj1QcYUv+FiRJ4qqEq074dwhwNzCttz/LDxXxxZZMnr0o8ZS7dVPiTSSXJ5NXk8enBz7lioQrcDe4Q8Iczt//HQfqk5njFMEPtnrKTGW8t/c97hlyjzixOcfZ83siubCGJxYfpOG4DOtOWg2BHkaCPI0Mi/RmZr9ATvWzadBK3Dctjl7+bnyyKZPVzeUR758RT7i3s9iP7ehcOnY4ysG8KmRk+gS7d8n7KjVnaZejJ4DNxt6SvSDDyKCRnfZHr5EYHO7FpvQyNqWWEuXjfGb7xYi/4ZG9GWoKsG37EEbfccLNr0q4Cg+9B0MDh4JMa06V3t69MWgMlDeUk1mVSaRH5On1RzhjPfW7QpZl3v8zgzXJxWgliYfPS6CvnT6bFwwMYsXhQjanl5FfUU+Qp7HD7SpMFfyc9jMjg0bS17fvST232Wbmi8Nf4KZ3Y178vDPuqxp66j7Rk5zse9sjB+c2m4177rmHsWPHkpjY+WDo+eefZ+HChe1uLykpwWQydfCI7sFms1FVVYUsy2g0PWblwWnZl19LWlE1rgYtD08OJcJTprj49Oqp/hWnzFW45e5E1jlTmXgrtpLSDrczWo1MC5xGvbUeo8lIsenE/ZkS5cyy/VZ2ZZaxfn8GvQNPfZbiyogr+c/h/7AsfRmZZZnc3fduAAx95vPShqcgdTvagX/n7dKf2Zi7kShDFGMDx55yO8LZw17fE9kVJl5YlUV9k42EABcmxnrh76YnwM2Ah1HbZvBcUlJy2u2MDtHhNT6YtzfmkVJYxd//tx1nvYYIbyMR3kbCvZyI9DYS4mlArz27v/fUci4dOxxlV2YJFrOFEGerasemzmgayvDO3QVAhUcituJirg2/ljFeYwjUB56wP719tKxPtrDucAHTopzOeL/QJ96Ex8ZnMe/5mh8tdTh5xhLkEoRO0qGVtOg0OnRo8XbyQq91YqT7SKinXYb3GJcY9lfsZ13aOs4LPe+0+iKcuZ72XWG1yewvqGV1SiX78muRJLh5dAiRLha7fS6dgd5+ThwoqOPrTUf4v6HtcwVZbVZeP/Q66TXp/JH+B3f3uZtYj9gTPq9NtvFZ6mdsL90OQKw+ljDXMLv02Z562j7RE9XU1Pz1RvTQwfkdd9zBgQMH2LBhwwm3e+SRR7jvvvtaf6+uriY8PBx/f388PLpvyIrNZkOSJPz9/c/6D8ih/VXo9DqmJQYzLOGvw+XOhLRlI+j0yCNuxC+m/wm3vSn4ppN+3gDg/IEmfj9QyNKUWsYnRp3ybGBAQABZliyWZSyjwlqBu487zjpnCJiOlL8WsjcyonALlQOu5tsj36Jz0REQEHBKbQhnF3t8T+SU1/PmxkyaZA2J4Z4snNsPZ4N6obsBAdA3KoT/rEllf14VZptMWkUTaRVNrdvoNRpumxTDtD6BqvXjbHUuHTscobK+idIGGzq9jtF9ItolQFTdgT+RdHoI7IdfZJ/WUPCgwI4TjB5rqoc3n+0soajeisXgjpfXGe4XAechle/mvYyf+TPrR3APAqsZrE3N/5Sfn8aPuAs/BM+OBx8TGyfiZHSid3BvcQzrQj3lu6KwysSKw0WsTiqmrE45Tuj1ev42IZrZ/YPt3t5Vo/U8ueQQm7PruXmyd7vP/OeHPienIQe9To+HwYMAvwACvE68H395+Ev2VO5Br5UAid11uxkSPeSEj+kKPWWf6MmMxo6jMY7X4wbnd955J7/++ivr168nLOzEV56cnJxwcmqf7Euj0XT7HU+SpB7RzzNhttrYklGOhMT4OJW/DCpzoOggSBqkhFlKPfPjWG1WNJLmtMJsLx8ewcrDxRwqqGF/fg2Dwr1O+Tmu73c940LHEekRqaw7bzH6duScrRiKdjK3fixDJrwowgEF4My+JwqqGnhi8SGqGyz08ndj4QWJuDqpf0gI9HTmmYv6Y7bayCmvJ7OsjvSSOkoKsojMWUwf024afveBykloggdCUH9w6Xz5UmeOVBzBx+jT6brcs9W5cOxwlKTCWiQkInxd8HQ59SzQZyxjLTIy+4LiWbLtOQb4D+CC2AtO6qGeLk70D/Nkb04V2zIrGRemP/P9YsxdXJKziVJzEfUVeZiRsUDzPxmLBE7mejTJvyklQTswJXIKUyKnnH4fBLvprt8VNpvMhtRSlh8sZF/u0Sofns56JicEMKNvEBG+KiQLBoZE+hDl60pWWT0rDpdw2dCj44ytBVv5PfN3kODuwXfTy6sXga4nvohc1VjFuuxVUFfM1LoGVmmb2ND0E9ckXImzk7sqr+FMdNd94mxxsu9rjxmcy7LMXXfdxU8//cTatWuJjo7u6i4JZ2hfbiV1jVa8XPT0VTv5Rspy5f+w4Z2e6C/LXMam/E1c1/c6EnwSTunp/dycmJUYzOK9+XyxJYuBYZ6nPMjXSBrivOPa3+EVjjz8Jtj0X7Rb3yHS6A7Ng3ObbOswk7wgnEhJTSOP/XSA8romInxcWHihYwbmx9JrNcT4uxEjFTIl7yuoXIPNzUamqQ43Uw31O7/FzWmRsrFnGAQNUAbqIYPBo+MZE6vNytaCrfyW8RuplanMiprF/MT5jntRwlnlUEHX1Te3VBeyqXgXv+qbyCr6E7Q6CuoKmBMz56S/80fF+LI3p4otGWWMC/vr2fa/ZPQgZPLjPLXiCdC7KZ9Lr3DwbP5XVwwb3oCUFTDibx1eBBeEE8kpr+et1SkcLlDCfyUJBod7Mb1vECOifTDo7LxP2axQUwgeISBJSJLERYNCeXNVCkv25nPhoBD0Wg2FdYW8s/cdAOZEzmSs5ArWo+uH06vSCXAOaJus19yA58FfeKYgjwNWE1NtBg5JTdRVF5D/883ETngUgjtPOCycu3rM4PyOO+7gq6++4pdffsHd3Z3CwkIAPD09cXY+/fIJQtfZkKLUYB3by0+dzOwtbDblZAEgfmaHm9Q21fJjyo/UmmvJrck95cE5KFnmlx0sJLmwhp1ZFQyLOvXZvk4NuJKG0jzc03+D9S+DzkhOYDxv7X6Lq3tfzaCAQfZrSzirVdY38djP+ymuaSTY08izFyXi6ezgcF1ZhoK9sOcryNnaerMmfARJ4WPZcjibMU75nOdbDOXpUJWr/Ev+XdnQPVgZpDf/q9IbWJe7jmUZyygzKd8rOo0OGSVxXb25ns8Pfc5l8Zfh6+zr2Ncq9FiHmuubq37x+BhVjVWsz13P7/s+plzXAHpnjAY3pkRMYVb0rFO6GDsqxpf31qWTXFhLVYMFuwSRR4yCG5cro6bjWc2w/SOoL4O8nRA+vNOnKW0opbCukES/U0+iKpx9LFYbP+7K4+vt2VisMs56LRcMCmFG30ACPE4uFPiU2Wzwx2OQtQlc/SBiNESMZkLMYD7brKe8rokNKaVM7h3AnrzNNNQWkWDTcNW2r8GilArEPZj9vuG8UpdMpG9vHhv3LAY0mA//gn73F1BfTjAQ7JcII//Ow2VJ+O35Gn1lISy+CxJmwci/gbO3Oq9R6JF6zOD8nXeUK1aTJk1qc/snn3zC/PnzHd8h4YxYrDa2pCsn0eN6qRx2WrhPuTJqcIWocW3ukmWZIxVHWgfmYW5hTAqfdFrNeLsaOL9/MD/tzuPLrdkMjfS2XyZqSaI+8VrcnDRIh5fAmn+xus9EsqqzeHvP27w88WU8nTzt05Zw1qpttPDozwfIrzTh7+7Esxcn4u1q+OsH2lN5Bmx4DQr2Kb9LGoiZBIOuBr84hlWbeDd9B7ubhtBvyhDCXa1QdJD6vB3szt1IeXUWc2sKILkAkn/nNV09W/WSUpNZ64Sn0Yfp0TOZEXcxnkYvAN7b9x5bCraQW5vLE6OfQK9x8MUIocdpaLKSVlILQL8QFb5bCw+ApRFCh7QZ6H5/5HtWZK2AukI8ZYlZoVOYPvaR0yqf6efmRFyAG0eKa9iVV0OcvVZDdXZc0+qh11Q4+DOk/NHp4DytMo1/bvgn7np33p/xvoj+OselFNXw79WpZJbWATA00pvbJ8cS4K7SoLzFrs+UgTlAXSkcXgKHl2DQOfG4Lp4fGsPJXLcNOTWX8/J340cj0bIWHRolAtNUBTUFeNXmotHXkVyVzZs525mn8eFFUwZ/sxgZ5BEJw2+GmMmg0RAcNhQS5sC29+Hwr5C8FDI3wIhbofccEW0iAD1ocC7Ldi6rJXSpvbmV1DZaHBPSfqQ5pD1mMuiUdYN15jpWZK1gbc5aCuoKAJCQuLbvtWg1p58Q69IhYSw9UEBqcS1bM8oZFWPHWTpJgrH3gMUEKSu4KulP9odFktNUxQf7PuCB4Q/Yry3hrPTZpkyyy+rxdjXw7EWJ6p/8HMtqgb1fKydEVjNoDZBwHgy4EjxDWzcL8DAyPMqHbRnlLD1QwK0TYikPiOfJlC8pdraBMZSp/e7Epfgw5O/Co2IvWBuJtFiZbW1ibIUJfcGnsHMR+MSAby+u6jWVfSX7OFJxhK8Of8X1/a533OsWeqTkohpsMgS4O+Hvbuf15vXl2H5dwEGbiQ1efkwbeR9xkRMBGB86nvTSQ0wtyGaCzR398HvgNAbmLUbF+nKkuIZFe0sYlRBGtL/K61zjZiqD84z10HQvGNqvDY7yiMJF50KNuYbUylTivePV7ZPQLZnMVr7cms3iPXnYZHA36rhlQgyT4v3VL7GZvVU5FgFMeBDcApSBetYmqC0i1ryPK0xbsDXI1DUZcTPoGOaTANHjIWoC+MaCuQEK9xOev5sHc/7kudpD7DBXsIcKLFotvwTGM3Dm+0i64y6AGz2xjb+fvLAhhO/6CspS4c9Xleiw0ber+7qFHqHHDM6Fs0tLSPuYWJVD2s0maK4Te2xIu1W28n3y91hkC0atkVHBo5gaOfWMTxI8XfTMHRjC9zty+WprNiOifOz7+iQNTHoEzA0YMjewID+Lh3zc2F60nYLaAoLd7J+9VDg7pBbXsPygshzooZkJhHg5cDlQaSqsfV45CQElNHb8/coJUQdm9w9mW0Y5Kw8Xc/EQX17Y8S+KG4rxMfqQ6JeIOXQQxCiDmStrCri2JBmn8gyoyGgOg8+DxholdL5gL0Hpa7l91I28kvw5v2f8Tpx3HGNCxjjoxQs90cF8JRGVGuvNrelreVqqIklvgbo69CsfJq7f9TDkehJ8EnjObwwc2QlBieDmf0ZtzRkQzKbUUpLyK3nsl4M8f/EA1ZJpARDQR1mLXpWrDNAT2pdL02q0DPQfyOaCzewu2i0G5+cgs9XGw4v2kV6izJZPjPfnlvExeLo4IKqpugBWP6Msr+p7AfSZo9wePgLGLoDydLRZm8jf+Rufm/MYpJnC3y+/GY13eNvnMbhAxEiIGEnfUX/n7ux1vL7jFSw2M6E+Cdw/7l/tB+ZAuamcJzc+SXVTNe/M/S8uh5fA1nfhwCJIvESphCCc08TgXHA4h4a0Z/4J5nrwCEEOTKRlmOxh8OCiuIvwM/oxKmSUUrbMTi4eHMqvewvIKK1jU1oZ4+Ls/Bo1Wpj6JCx/hPDcHQyqLGaXVwB/ZP0hZgSFDtlsMu+uS0eWYVKCP4mhDloCYWlSZif2fq0k3nFyhzF3Q9z0zkNjURIABXsayauq5oE1CzFJ+XgbvVk4ZiEBLm0H9G7uwcoa9JhJbdutzFYG6nu/hvJ0hm/5iAv6TmFxwQbe2/sekR6RhLqFIggdOdiy3lyFwfn+lCUkaSwYXPyYoPNmYlk+7P1GyY0y6jZIW6NsGDP5jNtyMehYeEFfHvx2F/m1Zh79eT/PXdyfcB+VBuiSpFwI3/6REtreweAcYHDAYGVwXrKbK3pfoU5fhG5r2YFC0kvqcHPScd+MeIbbM0fPiViaYOWTysVb/94w+q6290sSDZ4hrPPx58dIL3bn1XLIXEe/EiMT/2JZ+IiIidytM7CjaAdX9b6q06Uo3k7e6LV6TFYTGwo2MWPQVZC7DfJ2we7PlZn8DjRZm9pW8hHOWmJxg+Bwx4a0q54Ftzmk3dZrOo9veoLPD31ObZOyjnBe/DwmR0y268AcwN2o56LBykn/l1uzsNlUWJKhM8CMZyEokRlNQFUu67NX0WRt+suHCuee1UnFJBfW4KzXMn9MlGMaLToEP94Cu79QBuYxE+Hy/0H8DJAksqqzyKnO6fChGo3EzERfyo3fc6QiFTe9G4+OfLTdwLxTOgP49VLamvO6EoJYX86VB1bS1zUck9XEaztew2Qx2fEFC2cLs9VGcqGSLbpvsJ0vZNWXs778IABTe13ALZd+T9x5ryqzzfVlsPpZKDqgbBs90S5Nuhv1PDQlgmhfVyrrzTz68wHyKhvs8twd6jVd+T9/F9SWdLhJSxLTjKoMKkwV6vVF6HZqGy18vS0bgOvHRDpuYA6w6d9QkgxGD5j+tHKsaFZUV8RnBz/jtpW38cmBT6hqqiDcIxCPxul8tTUL60mcy40OGc1dg+86YQlPSZKYGjEVgJXZK5Vlu8NuVO5MXgrV+UD75bwL1izgnjX38J/d/2FZxjJSK1Kx2Cyn+g4IPYAYnAsO57CQ9toSJWMssN8/kpTKFFZlrzqjNeUn66LBIbg56citaGBNcrE6jeid4bwXGegRQ4DVRm15GlvyN6vTltBj1TVa+GxzJgBXjgjH103les1mE2x+G365AyoylSy00xcqJ0LNZQxlWebD/R/y0PqHeHfvu5Sbyts9TXhQNWZtLmazjnlRdxHuHt5um5Pi7AXnvwa+vdCaKlmQnYy3xok6Sx0lDR0PHIRzW3pJHU0WG+5GHeE+9r1425C2mu0aM+iMjIuZrdwYMQou+0RJHNWcF4Wg/mcc0n4sNyctz1zYj0hfFyrqmvjnj/vVG6B7BEPwQCVsOHVFh5t4OnkS6xkLwJ7iPer0Q+iWvt+RQ43JQriPM9P7OjCEO3mpkvRNkmDKE+B+tEb5Zwc/Y8GaBfye8TsNlgZCXEO4MfFGPpr1Jt7OnuRXmlidZL9zuYlhE9Fr9GRVZ5Famap83sNHKBeyd/2PwrpCHt3wKLk1uQBUmCooN5VTUFfAn3l/8snBT3h046M8sfEJkZPrLCQG54JDOTSkPXUlyDYI6s/yEmWQPilskt1nyjviYtBx2dAwAL7elo35mHqYduXkhmb6Qq6W3bivXmZMWb467Qg91tfbsqmsNxPq5czcgSHqNpa/BxbdBPu+VT57cTPg8s/ahpwDJqsJb6M3NmysyVnDPWvu4bvk72iwHB0sjAgZyPSgm/AxzWNfxhkmrnP2gjnKAN3LVM1DJSW8mHhb64D/QOkBPtjzDpt2fUDl6mfgqytgzfNn1qbQY7WsN+8b7GH3xFTbUxfThEyweyixXrFH79AZYMi1cPnnMOIWmPQPu7YL4OGs518X9SfCx4XyuiYe/Wk/BVUqDdBbcrwcWa4M0jswOHAwALuLd6vTB6HbKa42sWSvcp4yf0w0WjUnaI5Vmgp/vqb8PPSGdpUEglyDkJEZ5D+IR0Y8wquTXmVm1Ey8XdzanMs1WexzLudmcGN0yGgAVmatPNovoOLIUv614XHSqtL45MAnAHgbvflwxoc8MuIRLou/jMEBg9FJOtKq0siqzrJLn4TuQwzOBYdyWEi7LMORZQAUR41hV9EuAGZEzVCvzeOcPyAYLxc9RdWN/HGwSL2GfGMZPfp+Rtr06LZ/AMWH1WtL6FGyyupaT4RunRiDXqvSV35TPWx4A5YsUBJBufrDeS/AlEfBeDQseFPeJnYW7cSoNXLf0Pt4eszTxHvH02htZFHKIhasXsDitMWtMwE3D5+Gky2CTWllVNSd4ZINo6cS4u4XR4ypHs8/nlAuJiT9zo71z7Byzwe8ufe//C1rEfeZUlieuhjK0s6sTaFHUm29uakKa1kqPrKGcdHndTzwdw+EwdcoYe4q8HTR86+LEwn3caasVplBr6o327+h6IlKRYaKTCg90uEm40LGsWDIAm4dcKv92xe6pc+3ZGG2yvQP82R4lINqezfWwIrHwdqkRKkMvpYKUwWZVZmtm0wMm8hrk17jkZGPMChgUJvyfrP7B+PjaqCkppE/DhXarVvTIqYBsCl/E3XmOgjsS13YcJ7X1VJclkyASwB3DT66Jt7d4M6ggEHMi5/HP0b8g8EBysWtHUU77NYnoXsQg3PBoVpC2kfH+qob0l56RDkp0BpYoTEhI9Pfrz8hbirPHB7DqNdyxXBlZu7bHTmYzFb1GutzgbKm12ZFXvEUNNaq15bQI8iykgTOJsOYWF+GRKh0IpS7A364AQ7+pPzeZw7M+xQiR7fZrMHSwKcHP+Wl7S+xrXAbAAk+CTw95mnuG3ofQS5BVDVV8Xv6763h5rH+bvQOcsdqk1szzZ8Ro4cS4u6fAA2VysWEdS8yvDSX2RYdkVpXJGdv8gxGPtY1sGnnO2feptCj2GwyhwuUwbnd65tnbmCyVc9/3QcxN/E6+z73KfByMfCvi/oT5GmktLaJtUdUWHrl5AZR45SfU/7ocJNgt2DGhIw5rRruQs+TWlzD2mTlu/3GsVHql0trse19ZR23ezBMfpSc2jwe2/gYz219juJ6Zd836oydJgh10h1zLrfdfudy8d7xRLhH0GRrYnvhdhqtjbxktJAlWfFqrOWx3vPxMnp1+vjxYeOZETmD/n797dIfofsQg3PBYRwa0t6cCK4pcjSr8zcCcF5Ux1lj1TSzXxAB7k5U1DXx+/4C9RqSJMzj7uUHVyfub0yhfu3znYYSCueGDamlHMirQq+VuHFctDqNZG+F3+6HmkLlxOf815RMs07tT7aXZy6nqqmKQJdAhgYObb1dkiRGBo/klUmvML/ffDydPEmtSG29f/YApTzgsoOFJ5WQ5y8ZPWD2KxDQV/ndP4F+Q2/h+ou+4qVrN/DhJUuYFa2sBX43fw1ZZcln3qbQY+RWNFBjsmDQaYj1d7Xvk6evA0ATOxknrcq5H/6Ct6uBOc2fre2Z7XM+2EVcc6Ra6kqwisRV5zJZlvloQyYAkxP86RXg7piGi5OUdeYAkx5mf00Wj296nNKGUlz0LtjkkwtTn943kEAPJyrrzfy2zz7ncpIkcV3f63h6zNOMCx3HGzvfIKmhABcnL/5pdiHw0K8nfPzI4JHc1P8mEnwS7NIfofsQg3PBYfbmVrWGtCfae0biWFaLcjIAbPQNpdZci7+zP0MCh6jXZif0Wg1XjogA4IedudQ3qXeCojN6sdk/kjxJZn32qqMHpOMU1Kp4kUDoFhqarHy0IQOAecPCCfQ4wzXbnWmZLY+ZCJd9DGFDO9ys3lzPkjRlf7ws/jJ0mvZVPPUaPbOiZ/HihBcZE3q0BvnYWD88nfWU1Taxtfni3hkzesCF/4Hrl8Al78PQ+Up2d0nCzeDGdaP+QX+dJ5JsoySt41k/4ex0qEBZb54Q5I7OnstATNUczt+MFbldDoauMqw5S/b+vGp1jk1hw5WEkA2VkLu9w02arE0sTlvMk5uexGxTIbxe6Ba2Z1a0Xiy+ZnSkYxq12WDD68pERdx01lgqeX7b8zRYGujj04dnxj5DkOvJJaTTazVcOdz+53L9/fuT4JPAjyk/sqt4F3qNnodHPkqkrIX0NWJp1TlKDM4Fh9mQUgo4IKQ9ZyuYqsDFhz5xc5kdPZs5sXParCFypCm9Awj1cqbGZOGXPeolbJMkienxl4KrHyu0ZuRN/273xb4uZx33rb2PLw9/yab8TSIRz1nq+505lNU2EejhxCVDVKrl3VChfNYAht0Ehs7rJv+W8Ru15lpC3UIZFzrulJox6DTM7Kdk1f3NntEnGq0ySO/wLh0L+s7nWbMrw3IP2K9NodtrWW9u75woOclLeEpbw50uVszuDsxQfQKhXs6EeBmx2WR2Z1favwGtDnop62pJWd7xJpKW39N/J6k8qTU3jHB2sdpkPtmoXCy+YGAIAe4qXSw+XtKvUJKE1eDCN37BvLvvXayylbEhY3l05KO4G05t9n5y87lcbaOFn3fb91zu/Jjz6evbl/uG3kfv2OnKBW9Zhp2fnvBxVpuVw2WHWZW9yq79EbqWGJwLDuHYkHYlERy9phPkHsL1/a7vkpD2FlqNxP+NUq64/rQrj2qTerMDE8Im4OQWRK6TkSRbA6x8CsxKNt70ynQ+2P8BNmxsyNvAm7vebJ3NFM4eW9PLWLQrD4Cbx8fgpFOpdGDaGiUju39v8O58JqSmqYbf0n8DYF78vNO6SDYzMQiNBPtyqzjUPHhSm3vfiwjXGKEkCUqOiJro54hD+eqsN9+YqnzXRnvHodfq7frcZ6KlxvS2DJVD2zM3Kom5jqPVaJkYrtRzX529Wp0+CF1qxaFCcisacDfqmDfsNEtinqqGSmWtObAmdgw/ZSsRUJf0uoS7Bt91Wp9BrUbi6pHKudzPu+17Lueqd+WJUU8cjfAceoNS8i1jvZJpvhP5dfk8tfkpPjnwSZtqJ0LPJgbngkM4LKTdVA3ZzbW+W0q5dANjY/2I9nOlwWxl0c5c1dpx0bswNnQcuAezwqiDymzY8jZVjVW8suMVzDYzQwKG8NDwhwBIr0o/6TVXQve3J6eSF5clYbPJTE7wZ2S0j3qNpTTXL46bfsLNlqQtocHSQKR7JCODR55WUwHuRibEKzWf//X7IfXqMx/L2RuiJwCQvOdT7ll7D9sLOw7NFc4OJTWNFNc0opEgIdB+a2Jtpmo2VKcAMD7+Irs9rz2MaP6O2JlVgc0eOR2O5xcH3lFKpuzmNffHmxw+GYC9JXspbSi1fx+ELtPQZOXLrdkAXDUiAlen9kua7M1is1C86U3lYpBvLONH30+YWxi3D7ydK3pfcUaJ6Mb1Onou9+hPB/huRw5ZZXV2qTXepl8+0RA7Rfl5x8edPibMLYwAlwDMNjP7S/afcR+E7kEMzgWH2JiqHHBHxagc0p6+FqxmqnwieT1zMQfLDtrlS/NMaTQS14xSZhd/3VdA+ZmWhTqB6ZHTQaNlq7sXVdiwHvqFN/58jDJTGcGuwdw1+C7C3cPRa/Q0WBoorLNfaRCh6xzKr+bZXw9htsqMjvVlwbR49bLhVuVC8SGQNEdPIDoR7x1PuHs4lydcfkZLS26f1IteAW5UN1h48pcDVNar9xlq1ecCALbkrqeioYz/7P4PebV56rcrdImW+uax/m44G+wXcZJ06AdKsOKsc2Zo7Gy7Pa899A32wNmgparBzJHi9jPbZ0ySjl4o3/89lKe32yTINYg+Pn2QkVmX0/EAXuiZFu3KpbLeTIiXkfMS1V3OYbFZWJ29mnuX3cyLWYuxIcO4e3HSu/DKxFdaIzTOhEYjcdO4aPRaiczSOj7fnMWdX+3mlv/t4P31aezJqcRstdOEx5DrlWNs1kYo7HjgLUkSwwKHAbCzeKd92hW6nBicC6prstjYlKYMzsfHqRzSnqrM5q3yCWZLwRa+Pvy148p1/IXhUd4kBLnTZLHx3Y4c1dqJ8Yoh1jMWi97ImvBEvtCaOJS/BaPGwP3D7sdF74JOoyPaU8ngnVYpEo70dKnFtTy15CCNFhtDIrx4YEYCWjUvgrXMmocNo1BuUmq0dmJY0DBemvBSmwztp8PZoOXJuX0J8jRSVN3IU4sP0tCkYnlCgOCB4BXB/zVp6KN1w2Q18eqOV6k316vbruBwNSYzyw8WAfavb74hYykAI337Y9Aa7PrcZ0qn1TA0UimzuF2t0PZe00HvopQ3/eFGZblVeUabTaZEKBf51uasFdFcZ4nS2kZ+2q1czLx+dBR6eyZYPI5NtvH05qd5b+97FJclUY2NotiJEKSUGbPneeDAcC8+uG4Yd0yOZWikN3qtRFF1I0v2FvD4zwe45X87yLdHdJd3JCTMUn5e+0LrEsXjtRxbdxXtEp+ds4QYnAuq251dQV2jFW9Xg7oh7TWFULAPiwQrzMrFgJlR3Se0XZIkrm2ePV9xqEjVuuezY2YzOXwyzvGz+d0gg9XM7bpgwt2PrveK8YwBlNB2oefKLq/niV8O0NBkpV+IB4/M7oNBp+JXuyy3VkMoCB/Gg+se5MblN3LXqrt4bcdr/JjyIzuLdlLWUNYataKRNHY5OfJyMbDwgn54OutJK6nj+aWHsdhrlqIjkgR9LkCHxL11NnyMPuTV5rE4bbF6bQoOtzOrgju/2s2BvCo0Eq1LKOzB3FDJ5mrlAuiE3pfa7XntaUTzuvPtmRXqNODmDxe9fTTJVdoa+OEGWLlQGbCjlIVy0blQ3FDMwdKD6vRDcKgvt2TTZLHRJ9id0bG+qraVUpFCckUyhsYarjHBW5pggsfcq1p7vm5OnJcYzFMX9OOrW0bxz9l9mNYnEHejjrLaJvsl/x35d3D1V6LVmtfQH6+3T29cdC5UN1WTUpFin3aFLiUG54Lq1h0pAWBCnJ+6Ie3NA4YdfpGUW2rxNHgyKniUeu2dhgFhnvi7O9FksbEnp1K1dsaFjuPvA//OjNg53NDvBi6zOjEyYyvkH83OHusVC0BqZefJRoTurbimiSd+OUiNyUJcgBtPzO2LUa9SArjWRg8rJwo6I8EJc1kwZIFyc0MxWwu38m3yt7y0/SVuX3U7Xyd9TZPVvuHnIV7OPDG3L046DbuzK/n36lR1l67EzwStAc/yTK4KUjLN7yvZp157gsOYzFbeWZvGU4sPUl7XRKiXM6/MG0i8HdebHzj8HfXY8NG50Cdqmt2e156GRHgruadK6yitbVSnEZ9omP60UnIxekLzIH01fD8fVj2DU2Mdk8InMTZkLB5O9o1cEBwvo7SOVUlKJMqN46JVj2DcUbQDbFaG1VYx1+aEcfgt4KJizpVjGPXa5qVkcTx0Xm8A1h0ppslihwvHRg+YqOQI4sCPkNc+dF2n0TE4YDDQ/D4IPZ4YnAuqMpmtrVlg7Tkb0Y4st4baLjMqWTinRkztVllxQZk9HxWjHDC22Ktm81+0d97Q25kXP0+5Yd1LraFRLYPzzKpMrDaVw4MFuyupaeTF1dmU1zcR6evCwgv74WJQP9kOKX8oa/mix4PBhWFBw/hoxkc8MeoJru17LeNDxxPmFoYGDb+l/0ZGVcZfP+cpig905x+zeqORYE1SMZ9vybJ7G62MHq11qfsWKbMSGVUZIjNuD5dUWM2Cb3bze3N5vjkDgnnjykHE2XFgDjCoJJsXzG7cHD4DjUblC2enydNF35oAb0emSqHtLXxjYcYzcOlHEDXuaCTO6me5vu913D3kbiI9HFQHW1DNJxszkGUYF+dH7yD1L7bsKNwBdSUMN8vgFw99LlS9zY4MCFUmYOoarfY7xwsfAX2V/CesfRGa2i8jawltFzPnZwcHnMkJ57KtGeU0WmwEeRqJC3BTr6GyNKjIJFkrcdhSjUajY1pk95ylGBXjy5K9BWzLKMdqk9VdG9za6G1KTerqfNj2AYy9m2DXYO4dei8xnjFdVgNeOH3vrU+nrM5MhJ87z16UiLvRAReirBay05bzur6Wu4ITiWm+2c3gRj+/fvTz69e6aZO1iSZrE24GdT73w6J8uHNKHP9elcL3O3LxdXXi/AHBqrRF3wsh5Q/8MjfhFxFNaWMl6VXp9PPt99ePFboVWZb5cms23+/IwSaDr5uBBVPjGBzhbf/GmuqRcrYSLWuJTrzG/s9vR8OjfEgqrGFbRgXnJar0OTqWXy+Y+S8oOgRL7lZmBLM2QdRY9dsWVLUzq4Ld2ZVoNRLXj45Svb282jzyq7PRmaoZZHOHcfeCpmvOaTQaial9AvhmWw4rDhXZb1Jq5G2Qsx1qCmDzf4/OpjcbHDCYf439FzFeMZ08gdCTiDNyQVXrkptD2uP91Q1rSvkDGZkvPFxBo2FC+AR8ndVd43S6+oV44uako8Zk4XCBY2o2Y3CFCS2hUYsgfw8aScOo4FEEuAR0m6R5wsmpqjezI0tZH/rP2b3xcnFMkqmy9FU8by0iX6vhu+pDJ9zWoDWoNjBvMb1vIP/XXHf2ow3p1Nix7mwbgf2UsFxLI3d7DuQ/U/4jBuY91J8ppXy7XRmYT0rw562rBqszMAfk7M1KCTHPMGXGuBsb3lxSbU9Ohar5UNoJ7Av9myO7trwNVjM5NTn8kvpLt6i0Ipwam03mk41KtNScAcEEeRpVbzPAJYBH/cdwrcUJl+CByj7Vhab1CQRgb24lxdUm+zypwQUm/UPJg5L0G2RtbnO3i96FXt69xETLWUL8FQXV1JjM7MpWBhAT41QMabfZIG0VMjA15nyCXYO5PP5y9do7Q1qN1Hoi5IjQ9lbhw6H3HOXndS+B2U4HDcHhNqaVYpNlIn2MRPi4OKTNenM9L+5+k3LJRqhbCHcOvtsh7f6VK4aHE+Xnitkqs6b5YqDdNSeGA0jI3Iq/s8pVJwTVrG/OgXLhoBDun5GgWsSJLMs8vfsN3tbVUxQ2VNmHurEoXxf83AyYrTL786oc2/jga8DZG6pyadj/PY/8+QhfJX0lkpX2QKuSiskqq8fVScsVw8P/+gF2oNfoGVBwmPNsTtCr6yMmAz2MDAjzRJaV98NuQgYdvZC1/iUwdfw5FRe1ej4xOBdUszG1DKtNJsrPlQhfFQcQ+buhrhSNkweTBt/Ca5Ne67az5i2OXXfu0C/SUbcpmT+r82D7h1SaKvkp5Se+OPSF4/ognLGWAcaoSMckTjLbzLy27UWy6grwkiX+Mfwfqs+KnyxJkpjZT5mpWH6gUL3PU9wM0BmV7NK529VpQ1BVQ5O19YLx1ObZLbXsK9zBobo8NmssGGPOvL6y2iTp6EXjbWqVVOuMwRWG3wyA856vGOE3EIA1OWsc2w/hjJjMVr5ozv9xxfBwxyy1AqjMhtIU0Gghunt81qb1Vb5fVh0uwmaz4zFp+C1KibX6ctjwxtHbrRbM+Xt4d+lt3P71ZGo/mwuHf7Vfu4JDicG5oJr1KUeztKsqdSUyspK0SavvEWE9QyKO1sbMKO28RrTdObnBhAeVnw/8QFNZCt8kf8PSjKWYrSqFBAt2VVLTyMH8aiQkRjpgcC7LMh/s+4D9BdswAg87xxIQPlr1dk/F5IQADDoN2eX1JBXWqNOIkxv0mgrAymULeOm7uaQlLVYSWgk9wvbMcsxWmRAvI1FqXjAGft73Ecg2pul88Qweompb9tJSUm1HZrnjZ98SZoNvL2isYUp1JQAb8jbQaFUpe7xgd7/syaO8rolADyfO7x/ikDa3Fmzlf1teIl2yQugwcPZySLt/ZXSML84GLUXVjRzIt2Mkis4Ak/4JkkapdvDna/D7Q/DZXPRLFpBSsI3yxkr2NJUqa9PrHXyhTbCL7j+KEXqkstpGDjSHxqmapd3SSH36av6hr2Odlx82WcWax3Zk1Gtb1zluSXfwl2fEyNZ6s/5Jy3HXu2ORLWTXZDu2H8JpaZk17xfigY+L+jMTm/M3sy53HRpTNfeanYlJuKDbhei6OumY0Lx0ZtmBQvUaGvk3iB7PXo2FnXU5HPjzOfjhRkheChb7lowT7G9jaikAY3v5qZpn40jFEQ6VHUIHnB89u9t9XjrTP8wTg05DaW0TmWX1jm1co4HRdwDQN30jATo3GiwNbC3Y6th+CKelsr6JRTvzALhudBQGnWOGF2tz1vBb8Tb2aizdIqS9hVGvZWLzue/KQ0X2ffKA3spSEIBDvyjJfs314OTOMO/e4BbITlcP5badn9i3bcEhxOBcUMWG1FJkGXoHuRPooWJCkKyN/GyrJFOn4ZeyfT1qrc2oGCX0fmuGA9edtxh4NQBS+mpiXJXMvGmVaY7vh3DKHBaR0qyfXz/G+g/mUpOVQbK+W50AHWtmohJG+GdKiXqJ4YyeMONZeo9cAM7eJOmA8nRY+wJ8dTns/UbJgSF0OyaztTWJ4phYdT87Px9ZBE21jLMa8IufpWpb9uSk0zIwzAuA7Y4ObQcIHQJR49DIMlPqlIsDq7NXO74fwin7cms2DWYrcYFujHfQsanB0sD+gu1gbWIYzkppvm5kenNo+4bUUuoaLfZ98iHXKdEmkWNh9J1KacLrFjN00pPg7MVuV3fMyEpoe7n9y5kK6hKDc0EVLVnaJyaoOGsOlCb9yu/aJnDy4Oo+V6PtpnVkOzIiygeNBOkldfbL6HmyAnpDyGCwWYmpUWaT0qrE4Ly7yymvJ72kDo1GYkwvx+RV8HTy5G5jNJdaDRCYCB6OCVc8VQmB7kT6umC2yqw7olJiuGa9w0aDWwDJQfHYRvxNyePQUAFb3oEksc6vO9qZVUGTxUaghxOx/q6qtZNTncPO3A1Iso0LjSHg31u1ttQwIlqJ6Nqudr3zzoy6DTQ6JpTmommq53D5YXYW7Wy9u7aplnqzg2f1hRPKq2zgj4NKxNKNY6MdVv1lX8k+zA0VBMoawiLGKxnNu5G4ADcifJRj0p8pdj4mafUw6WE47zkYME8pTajR0MurF54GTxq0WpJCB4BsU45LQo/Sowbn69evZ+7cuYSEhCBJEj///HNXd0noQH5lAynFtWgkGNdLxSuopiq+KdqIGZk+AYMYGjhUvbZU4Omip2+IsmZ4S1fMUgy8CoDYgmSw2UivFJlxu7uWWfMhEV54qJxsp8JUcTQSJXUFEhLETVe1zTMhSRLnJQYBSmi7mlE0UR5RGLVG6qyN5MSOhau+gaHXK3dufU+s8+uGNjgopP3XjF+hsYYRNj0hMdN6TEh7i2HN686Ti2qoqu+CPCSeYdD/MnzRMKHBBLJMhHtE693LM5dzw/IbWLB6Ab+miwth3cEfBwuxyTA00pvEUE+Htbu9YBs0VjPMpkfqhscmSZKY1jcAgBWH7Ji1/QQ0kobBgYMB2BIQBRqdEvaeLZaH9CQ9anBeV1fHwIED+e9//9vVXRFOoOUK4YAwL1XrL2cc/J4NUiPojFw7+PYeWau7JbTdoSXVWoSPAJ9oYs1mMFWSW5Mrku90Y7Ist643VzWPA8rs1D/+/Aev73yd2uTfmzPh6iB2sqrtnqlJCQHotRJZZfUkF6mUGA7QarTEe8cDcLj8MGh1MGQ++CdAUy1seku1toVTZzJb2dE8E6zqBWPg2vgrmNcoc7HVSUlS2sP4uTkR7eeKLMPO7C66yDT4WnD24u+1jfw3bA5+x5QuLG1QLrIU1hfy9eGvabA0dE0fBUCpa94SqTSjr7oVEI5ltVnZnfsn2CwM03pA+EiHtX0qJicEoNFIHCmqIdtBeRzGh44HYF3pHqr6zFZu3PI22KwOaV84cz1qcD5r1iyeffZZLr744q7uitAJWT76Ra3mAEKWZb448h0yMNZ/ELFesaq1paaR0crg/GBeFdVqrZPtjCTBwKvwQYN3QzVaSUNBbYFj+yCctNTiWvIrTRh0GkZFqxvS/r9D/6OysZLcynSctryt3DjoamXNdTfm5qRjfHNiuOUH7JyE5zh9fPsAkFSWpNyg0cD4B45m0c3Zpmr7wsnblV2ByWzD392JXgHqlgB0K07isiYN0S5BENBX1bbU0lJSbXtmRdd0wMkNht2EhITf3u+QGo72428D/8YHMz4gwCUAi2zhQOmBrumjAMD+vCrKaptwddK2Rl04QlJFErV1xbjLEglRU5Qs5t2Ql4uBEVHKUpEVh9U9JrXo59uPQf6DuLDXhegH/h84uSslQJN+c0j7wpnTdXUH1NTY2Ehj49GZwOrqagBsNhu2bpy0x2azIctyt+5jZ9JL68gur8eg1TAq2lu115CWt4UDpmJ0SFw+5O4e+V4BBLgbiPR1IbOsjm3pZUzpHdDhdqrtE9GTkLa9z8K6YryjL0fnHtFj38uz3drkYmRkRkR546STVNsn9hTvYV3OOiTgbw0yOlMNsm8s8qBrekSysxl9A1iVVMT6I8XcMDYSNyd1DnMJXgnoNXps8jHHE99e0O8SpAM/wJ+vIl/2iVIb3UF68rFDTRtTSpGRGR3jgyzLqix5sNgsaCUtmjSlNrccpcxedYfPzKnuF8MivPh2ezY7MsupaWjCVaXP0AnFz0I6+JOScHHpQ8hz3gC9sqbYTefGIP9B/JH5B7uLdjM0oGctaesO7PVdsSapCBmZsbG+6DQ47Lunqr4Mr8Y6Btr0SL2mdevvvKm9A9icXsaapCKuHRmOTqv+vOjDwx9u/dk2dD7Sprdg+0fIMZPB0HHODXH8UN/Jvrdn9eD8+eefZ+HChe1uLykpwWRycAKuU2Cz2aiqqkKWZTSaHhXcwO97irGYLQwMcqeuqhy1KngHpO3icZMTmV7hYPOhuNgx63nU0M9PT2qhhTUHc0ns5MKzmvuEMWIGPvs/w7rjS4q9hyszf0K3YpNlVh3Mx2K20N9fR3FxsSr7RIOlgf/u/S9mi5kZxkhi0rdilnRU9f8b1rIumkU7RT4amUAXLXlVjSzensq0eHVmc7xkL54f9Dx6jb7t90/EHLyT/kBTkUPD+neoT/w/VdrvSE8+dqjFbLWxMaUIi9lGb29JtWPFT1k/kVaVwvWZu+htMVPlNQBLNzkunep+4Skd/Qx9s+kIc/s5Jvv28TSD78ZzzT/RFB6iafFD1Ix5REmEBUTpojBbzGzN3crcgLk9cllbV7LHd0WjxcbapEIsZhsDmo9LjpJQWs2/63Q0OHlSrAuFbvJZ60iYs4yLVqa0uoGVezMYEubu2A74jsLL+A3a2nwaNrxHfeI1HW4mjh/qq6k5ueV2Z/Xg/JFHHuG+++5r/b26uprw8HD8/f3x8PDowp6dmM1mQ5Ik/P39e9QHRJZl9hRmo9PrmDkwgoAAlQ7osoy0djP9NEb6DroBAjqebe4ppg904bfkSpJKGvH09sVJ3z7jvKr7hNfVSGm/oGsoIsCUppTmELqV/XlV1FrAy9XIlAHRGHQaVfaJj/Z/RK2tljBXf+bnJaHT6ZGH34xv3HC7PL+jXDDEygcbMtiSY+Kqsf6OP3Gf/BDSisdwT/8Nt0EXgU+0Q5rtqccONW3LKMeChkAvZ0b3iUSjsf++UGeuY8vuLZjqyzDRhM4jCJ8+47vNhc7T2S+uHavhlRVHWJ1Ww9VjE3A2dEEllIAAcH8V6dd70JUfxCXpM+RJj4Ak4eXrxScZn1BrraXJpYlw93DH968Hs8d3xZ8pJVjQEOLjzNi+6ny2OiMd3A06A/res/AIDHJYu6frvAEN/Lg7jx0FTZw3xDHnrLIss7tkN6tzV3P3uNvRrVyIe+Yy3IZfBe7B7bYXxw/1GY0nF0l3Vg/OnZyccHJyane7RqPp9jueJEk9op/HOlxQTUlNEy56HSNjfNXre+F+qMoFvTNS7GRlrWcPFhvgToC7kZKaRvblVTMypuP1xKrtE0Z3rH3m8v6BT8jY/CRPhi3BVa9eqSHh1P2ZUoqExJhefhgNR7+27blPHCw7yMqclSDB3xpsGJvqIaAv0qCre9xnbEqfQD7bnEVWeT2pJfUkBKk7U2G2mtFrj8meHzNeqbmbuQFp42sw9y2HvYc98dihpk1pZUhIjOvlh06nzgBzZfZKTFYT4TYYKuuQoicgabvX6dWp7hcT4gP4ensO+ZUmlh4s4rKhYSr3sBOBfWH6M7DsH0rVCDd/GPk3jBoj8/vNJ9AlkBC3ELG/n4Yz/a5Ye0Q5Lk1OCFDts9WRspp8vLM2oAGkuGk94vg0vW8QP+3OZ0dWBUmFta2VetRksVn49OCnlDSUsD5gIDNCBkP+bqTtH8K0Jzt8jDh+qOtk31fx7gt2s7y5zuWoWF+cVPyiXrbzHd7TNpAcNqjb1bU8HZIkMSpGCb3dkt412XG1/edxUGslq7GcjPSVXdIHoWNmq42NqUo2/4kqJlmsMlUR7BrMdGMY/QqPgNYAkx8BTRfMmJ0hd6Oecc2J4ZYdKFStnZyaHB5c9yAPrn+w/Z1jF4DeGQoPQLJIxNMVmiw2tjaXqRzTS50kio3WRn7L+A1kmYvqGtAgQcxEVdpyJI1G4orhymz0T7tzMZm7MNNzxEiY+JDy856v4MAiAKZFTqO/f/+2F8YEh6iqN7MrS1nqNCnBsdGLL//5T/5GMUluXj0m6WK4jwtT+wQgy/DGyiMO+TzpNDrmxM4BYEnar1hH/V1JBJy2Gjb9B5ockz1eOHU9anBeW1vLnj172LNnDwAZGRns2bOH7Ozsru2YQI3J3FrmaVaiiiFGTfVsKd7Jam0TuYHx6rXjYC0l1bZllmGzqVefuVOufsR49QIg7fAix7cvdGp3diW1jRa8XQ30V7GG7JjQMbw+5CGuz27OfjziVvCKOPGDurHz+infQ3+mlFDXaFGlDR+jDzk1ORTUFVBpqmx7p1sADLtJ+VnUPu8S+3IrqW+y4u1qoE+QOjNV2wu3U9NUQ4DGidGNZnD2hqCBqrTlaBPjAwj0MFLdYFH1ItdJSZgFw29Wft70FjQn3hO6xvqUEmwyxAW4Ee7juEmS0oZSMipSqZVkgmOmKYPNHuKW8TH4uhkoqDLx2aZMh7Q5OXwyHgYPihuK2dhYDAOuVO7Y/z18d63yOVIhQaZwZnrU4HzHjh0MHjyYwYMHA3DfffcxePBgnnjiiS7umbDqcDFmq0y0nyu9VQwhbUpdSQqNoDXQN+Y81dpxtH4hnrg56ahusHCooLpL+tArdiYAaWWHoTKnS/ogtLfuiJLoZkKcn7pr+mw2pHUvoDebIHggJF6qXlsO0CfYnQgfFxotNtYkq5MsyFXvSoSHcgHjcPnh9hskXgJ+cdBYowwomk+CKk2VbM7fzKcHPuXFbS+SVZ2lSv/OdS0RJ2NifVX77LT87QZZNWiRIHp8jwizPRnaY2bPF+3KpdHSxXWSB18D/S5SPkdr/gX5e0guT+Z/B//H/pL9Xdu3c0zLd+qkTirMqGVHzp/QVEe8TYdnwvkObftMuTrpuHtqHAC/7itgb06l6m06aZ2YHa3UOv8l9RdsI2+FWS+BRwjUlcLKp2DpQ8pSUaHb6FFHkEmTJrWWQTn236efftrVXTun2WwySw8o9bFn9w9SNflSyuFFWABvt2CC3NontOiptBqJ4c21MDeklnZJH2JCRoDBjXTJCnu+7JI+CG2ZzFa2Ni91mKBSSHuDpYH1uetpOvADFOxVQrEn/aPHDzAkSeK85iien3fnYbGqUx6mt09voJPBuUbbtvZ50q+8sO0F/rbyb7yx6w2WZi5lV/Eufkz5UZW+ncssVhtb0pXB+dhY9bKN59bkggxhFc0nt9GTVGurK0xO8CfA3YnKejPLDzqmTnOnJAnGLFAugFjNsOIJtmSv4beM39iYv7Fr+3YOya2oJ6WoFo2kXDR2FIvNwh9J3wIyw1yCwSfGYW3by5AI79bj0r9XpVDfpE5U17FmRM3AqDWSW5vLrqJdyjKReZ/C0OuV6gc52+D7G2Dnp2BtUr0/wl/r2WdfQrewN7eS/EoTznotE+NVvIpamc2hiiRAom/omLOudErLFejVh4sd8oV9vBjPGHDxoUSyUZX8G+z4RIQ7dbF1R0potNgI8jQSF+CmShsb8zby3z3/ZeHe/yg3jLhFuap+FpjeNxAvFz1F1Y2sTlJn9rxlcJ5UntTh/WkGvfKeAmz8N742GQmJSI9IxoYolRH2FO/BbDWr0r9z1d7cKmobLXi56OmnYvKl0SGjmebdh/jGRjB6Qsgg1drqCjqthnnDlGRwi3bm0mTp4hrIGg1MeVypgGCqYmBBMgB7SvaoUr9eaG9tsrKEcXCEN14uBsc02ljL0uX3kFeWjIcsMTnuIse0q4Ibx0YT6OFEcU0jH2/IUL09V70rM6JmAPBz6s/K50TnBMNuhMs+gbDhYG1C2vUZXivvU5IuC11KDM6FM7a0eS3alD4B6pZbSV7KQckKBlf6Bg1Vr50uMjjcizBvZxrMVlYddnzNThe9C8FeMeDqT4ZkVa6i7vhIDNC7SKPFytfblHwa5/cPVu1i1MrslWBpYrSpSZnpjT97losY9VouHaIMLL7bkaPK7Hkfnz4AZFdnU2eua71dlmW+S/6Of274J394+iolCq1NXJa+i48mvcFLE17izsF34u3kjclq4lD5Ibv37Vy2qTkCaVSMeiHtABPCJnCL7E60rG0Oae95CRT/ypTegfi6GSiva2Ll4S6ePQdlYDHhIZAk+mXvxGBposJUIZaHOIAsy6xtDmmf4oiQdlmGlBWUfXMlPxRuBGSu9h+B26COa3X3BM4GLfdMU3ImLT9YxM4s9fORzImZQy+vXsyKntX2Dq9wmP0yTHsKXHzR1uYj/boANr4J5gbV+yV0TAzOhTNSWtvI1ubQwdmJKoaZ26yYk5eSqrGC0ZO+vj0jQ+epkCSJOQOUGctf9+V3SWK4Xl69CPbvR1O/i5Qbdn0O2z8UA/QusGRvAWW1Tfi7OzG7vzqfrbTKNDKqMtBZTEyw6SFoABjOrjJ65yUGqTp77m30JsglCBmZIxVHAKW02lu732JRipJcsaKxUlkq4B6Md00xrhuV9ecaScPUyKnMjp6Nn7PjwkPPdlabzOaWkPZeKr+vNhtk/Kn8HD1J3ba6iEGnaS2l9v2OHMwqLRE5JYF9od/F6JFIrCkH2caekj1d3auz3uGCGoqqG3HWaxkR7aNuY+UZ8Os9sPpZDjSV0aTVEx86holz3lEu0PRgiaGeXDBQOd/796pUakzqRk55Onnyr3H/Ymzo2PYX+iUJYicjX/YJpqipyvnegR+VUPe8nar2S+iYGJwLZ2TZgUJsMiSGehDhq2LGzpytlDWU4q8x4OUeQrDr2bPe/FhTegfgYtCSX2liV3aFw9u/fdDtvDH5DUaMfQjG3KXcuPsLJdu0GKA7TI3JzPc7lKR8146KxKBT56t6ZZZSNm+kzYAHGogYpUo7Xcmo17YOLNSaPR8dMprxoeNx17tT3VTNs1ufZWP+RrSSlr8P+DtX9L4CjB4wfaGyxi9zA+z7FoB58fO4vt/1hLqF2r1f56r9eVXUmCy4G3WqVjgoqisiPW0pTQ3l4OQOIYNVa6urzegbhLergdLapi6J7OrQ8FvALYBBpiaoK2NP8Z6u7tFZryUR3Jhevhj1KkWJ2Gyw9X1YdBPk7wGdExOH3s7zc77k1tGPoJHOjqHLtaMjCfEyUl7XxAfr0x3admZVZvsbndypG3oH8qyXwS0Qagrg1/tg/SvQVNd+e0E1Z8ceLnQJi9XWWttcrZm9Vsm/E4SW1+Ov440p/z7r1pu3cDZomd43EIAle/Md3v6xBz1b4iVKrWaAvV/DlrfFAN1BvtuRS32TlSg/V9Vqm9eb69mUvwlkG9OqK5Ubz8LBOcDMfkdnz1epMHt+Ze8ruXPwnbjqXXl8w+MklSfhonPhkRGPMDli8tEN/ROOXvTa+p6SgE+wu43NIe2jY3zRqhjSvjJ7JY/seIkvtCaIngBanWptdTWDTsOlQ5QLSD/sVOci1ykzuMC4exls00FDBcnFe9ssLRHsq8liY0OK8tlStbZ56kolKa3NClHjYN5nMORaonziCHcPV69dBzPqtdw7PR6NBGuSS1oTWKptQ94GHv7zYb48/CU2uYPPcdgwJWFcSwTl4SXw3fVQeMAh/RPE4Fw4A1vSy6msN+Plom+t062K+nLI2qT8nDALZ52zem11A3MGhCBJsCu7kpzy+i7pQ725nqc3P80mnyAYd69y477vYPN/xABdZcXVJn7dp1yYmT8mUrX1shvzN2KymgjVONPHKoN7MHhFqtJWVzt29lytsNzaploe3/Q4hfWF+Dv78/TYp+nv37/9hn0ugLjpINtg5UKoL8dsM7O/ZL+Y+bMDm01uPckdo3JIe05VJjTWECZrIW6Gqm11B8de5GpJCtblIscQEDuVUFnCs7aEwpq8ru7RWWtHVjm1jRZ83QwMUDEihZQ/lP8H/R9bB1xAjuT4BLmO0jvIg4sHKxe9Pt+c5ZCkhiX1ymd3cdpiXt3xKg2WDtaWN1/4Yu4bzWXXSpSSayVHVO+fIAbnwhn4vbl82ox+Qei1Ku5KqSux2SxY/Hv3yNIZpyrI08jwKGUt12/7C7qkDyuyVnC4/DBv7XqL7b6hMP5+5Y79P8CBRV3Sp3PFl1uzsVhl+od5MiTCW7V2cmqUsPmpkhsSkjJrfpZGpEDbgYUaa8/dDG5cEHsBvbx68a9x/+p8hkeSYNx94B0F9WWw+hk25vzJs1uf5dvkb+3er3PNwfxqKuvNuDnpGBim4gACyC3eD7KNMJcAJV/DWc6o13LRIGUg0RI11y2MuZsnNYG8U6chNmdXV/fmrLWm+XtzYry/ekkW68tb1zmXR4/h7T1v8/D6h0mrTFOnvW7gsmHhGPUassvr2ZtbpXp7F8ddzF2D70Kv0bOjaAdPbnqSsoZOZu1DBsNlH0PwQCW0/fcHoEIkXlSbGJwLpyWnvJ79uVVoJDivX5B6DckyJP1GkmTlJjmPt3a/pV5b3UhLopBVh4uoa3T8VeO5sXMZHzoeGzbe2PkGu3zDYNTtyp17vgSLqIWphozSutY1fTeMiVJ1+caNiTfyxsTXmVTefJJ9loa0t3DE7PncmLk8NfopPJ3+YlBocFHWn+udIW8Xg7d+gtRQRXplaucnScJJ2Zh2NEu7TsWLxg2WBkqaL3CFx85USnydAyYl+CNJkFRYQ3GNqau7o3DxwXPUncpFxh0fQ7Xjl4SdzWw2mU82ZrAlXckqPlnNkPaMdUpUkX9vvshdjclqIsYzhmjPaPXa7GJuTjqm9lGWMy7e45h9d1zoOB4f9TieBk+yqrN4dMOjnV8A0TvDec8ry7JMVfDb/VDdNRNH54pz42gi2N3S5lnz4VE++LurmDWzJAkqMjmsBZPeGavNql5b3ciAME8ifFwwmW1dUrpGI2m4beBtjA4ejUW28NrO19gb2AvcApQr28m/ObxP54LPNmUiyzAuzo+4QHfV2wtuasC1rgy0BggepHp7XU3tzO2SJKHX6k9uY+8omPQI6Ix4VmQTV10CZWnsWve0kqVYOGU2m9y63nxsLxWXWgF5xQehqR5PWcK9zwWqttWd+Lo5tdaNb1l/3C0kzIaQQdgsJhrXvySWX9lJk8XGS8uT+XGXslzg2lGRRPmpWNEjbTUAB0P6sDF/Ixo03Nj/xrMmCVxn5jZPyOzIKiev0jElzBJ8Enh23LOEu4dT0VjB01uepqKxk0TEBleY9RJ4Ryoh7r8/oJwLCqo4rb3dYrGwcuVK3nvvPWpqagDIz8+ntrbWrp0TuieT2crK5myts9ROBJekDAIPeQaARnNWllDriCRJzB2ovLdL9hZ0SVk1rUbLnYPvZHjgcMw2My/vep2DvSYqd+79Bqxn7zqwrrA/t4qdWRVoNBLXjlJv7XeDpYEKU/MBOGer8n/oENAbVWuzu3DSHZO5fXs3KAkVMxH+73sYcxfDjAEg29iRtxG+nw9LFkDGejHIOAWHC5WQdheDlgFhXqq2lZO6FJAJd/YHzzBV2+puxscpSSq71eBckvg9ehi3Gur4vXALpK7q6h71eFUNZh79aT8bU0vRaiTumx7P5cNVTMhWWwwF+7BI8HFtKgDTIqcR43n2L2cM9XJmaKQ3sgy/OjAZcIBLAE+PeZrBAYOZHT0bb6cTLKVz9oLZryr5aapylRl0U7XD+nouOeXBeVZWFv379+fCCy/kjjvuoKRESSzw4osv8sADD9i9g0L3s+5ICQ1NVoI8jQwO91KvIbMJ0lZjRuaITgnv7ePbR732uplJCQG4OekoqjaxI8vxZdUAdBodC4YsYHDAYMw2M+/WHMJs9IKaQkhd0SV9OhvJshI2CDArMYgQL/WSHq7PXc8dq+7gy8NfQvYW5cbwkaq11920zJ4X1zR2j5JQRg/ofxlD574PnuEccHahQZKUEkJ/PA4rnlBCCYW/tClVWRIwMtpHtfKDLXLzNgMQFjBQ1Xa6ozGxvmgkSCmupaDKMbN8J8PgHkyNqze7JTPs/EQpySWclrzKBh78fi9JhTW4Oml55sJEJvdWMZwdIG0NAGt8gsk1leBucOeKhCvUbbMbuXBQy3LGYocuZ3TRu/DQ8IeYFz+v9baaphrM1g5qr7v5w/mvgosPlKfD0oehqWsSF5/NTvnotWDBAoYNG0ZFRQXOzkdPIC+++GJWrRJXKs92sizze3OSstn9g9RLCgLKrFFTHWluPjRp9XgYPAhzO3dmKIx6LTP6NZdV29d163v0Wj33D72fcaHjeGjkI+gHXqncsfsLcfJjJxtTy0gprsVZr+VKFWcmZFlmVdYqrLIVb40RCvcrd0SMVq3N7ubY2XO11p6fjlD3MIK8YrB4BLNv2iMw6P9Ao1O+B7+/AXK2d3UXuzWbTW5dbz5W5SztlKYypqaa/7O5MqLPvL/e/izj5WKgf3OyvT+70ez5oIBB4OxNihZqq3IgfU1Xd6lHOpRfzYPf76WgykSghxMvXzaw9e+tqrRVmJH5WacMTC+NuxQ3g5v67XYTg8K9iPBxocFsdfhyRo2kaV06YLaaeXHbizy95WmqGju4MOwZqgzQndyh+BD88ZiIpLSzUx6c//nnnzz22GMYDIY2t0dFRZGXJ0pYnO3SSupIL6lDr5VaE1ioJvl3AA4HxoEEfX37nrX1zTtzfv9gNBLsza0kr6qxy/qh1+q5a/BdSgbqvhcqX8pVuZCxtsv6dLaw2WQ+35IJwEWDQ/FyMZz4AWfgSMURsmqy0Gv0TMBZSbzjHQkeKi9P6WaOnT3/YWduV3cHUJayDA0cCsDh+gIYeStc9A54RShZ3X9/ADb+Gyxd9z3QnSUX1VBW24SzXstgFascAHBkGbGylgsiptIvZIS6bXVT3TG03c/ZjzD3CGzO3uzTWJTkpWJZyCnZk1PJYz/vp8ZkIS7QjVfmDSTcx0X9hitzoCQZJA0zEi4h0j2SqRFT1W+3G2m7nDG/S5YzAuTV5ZFfl8+RiiM8tuExcqpz2m/kEwOzXwa9i5Jdv6X8nWAXpzw4t9lsWK3tk3Ll5ubi7q5+AiOha7VczRsV44uH8SQTH52OqjzI3w2SxEEnZbByLoW0twjwMLbWkF+R3E2SbxhcMPe9SPl5tzj5OVOHCqrJrzThYtC21jtVg0228cXhLwAYGzoWt/y9yh3hZ3eW9o446bTcMl5Zx/jN9hxSi7tHvpSZUTN5cfyLXN/veuUG/3i45APod7Hy+4FF8OOtUJradZ3sploSwY1QO6TdZoXUlcrP8eep1043NybWF41GIqO0jtyK7hPWOiRwCDh7sVZng7I0yNrU1V3qUZRoIpkR0T48d3F/VS8Wt9GcCE4fNpwL+1zNixNexKB1UNvdyNHljI1szeiac74ojyieHfssQS5BFDcU89jGx9hTvKf9hgF9YMh1ys8HfhDngnZ0ykewGTNm8MYbb7T+LkkStbW1PPnkk8yePduefRO6mSaLjXXJSo4B1WfNjyxV/g8bzuDQMQzwG0Cib6K6bXZTLVk8N2ZUUWPqYA2QA1WaKnltx2vcV7UDq94ZylIhe3OX9qmnW9tcOm1sLz+cDVrV2tmQt4EjFUcwao1c3uuyo8ngzvISap0ZH+fH2F5+2Gwyr684QpOl68PbA10DifI8roSe3gjj7oFZL4KzN1Rkws9/h+RlXdXNbkeWZTalKevNx6icpZ3c7ZQ2lLHJaKDAW8XkWN2cu1HfmnOmO4W2T4uYhkajZ6+LC8mSRVl+JQYNJ6W+ycKBfCXB103jojHq1TsetSHLkNa8LDZWmS0/16IkWxj1Ws5LVMoTL3ZgYrjjhbiF8Oy4Z+nj0weT1cSL215kU14HF7p6nw86o3IhrGCPw/t5tjrlwfmrr77Kxo0b6du3LyaTiauvvro1pP3FF19Uo49CN7Eto5zaRgu+bgZ1E8HZbEdPPBNmcX7M+Tw66lHC3M+d9ebH6hfiQYS3C2arzO7syi7ti6velUPlhyhurGB3VHM4pzj5OW1NFhsbm5NYTYz3V62denM9XxxSZs0vibsE37oyaKhQQtKC+qvWbncmSRK3TYrFy0VPdnk9X2/L7uounVjEKLjsY4gcC1YzbPq38r9AanEtJTWNGPUahkaqHdK+nL0aC286Wfjo0GfqttXNjY9T1vZ3p9D2QNdAJoRPAGcfZe1y8SHI39XV3eoR9mRXYrPJhHgZVU1K2k55OtaKTF7TN7Ld2QWb3PUXSrvS+QOU5YwH8qpIL+m6qC53gzuPjnqUSWGTsGHjwwMftl+DbvSA+BnKz/t/cHwnz1KnPDgPCwtj7969/POf/+Tee+9l8ODBvPDCC+zevZuAAJUzOQpdqiWkfWrvAHUTweXtUOooOrlD5Dj12ukhJEliSKQXAHtzuzZrs16rZ1LYJABWGbVKfeyig+Lk5zTtyq6gttGCj6uB/qHqJdzJqcnBJtsIdg1mdvTso9EOYcPgZOtyn4U8nfXcPqkXAD/uyiWpsOvLwpQ1lPGf3f/h8Y2Pt7/TxQdmPKv831SnLP0R2NAc0j4sygcnnYqzfY01kLmBXMkKTp5KDo5z2KgYX3RaiezyerLK6rq6O60u6XUJs2LmcEvsRcoNu7/o0v70FNszlaoww6N8HNtw2mo2acxsNep47/D/aLSe23k1/NycWpNaduXsOYBeo+fWAbcS5RGFk9aJ4voOKpwkXqr8n7URqru2v2eL01qYpdPpuOaaa3jppZd4++23ufnmm9tkbhfOPmW1jezOVr64pzgoERxx0zlYlUKlqVLd9nqAgc01e/d18eAcaE3Ssrv8MCW9Jis3ipOf07LuiLJMZHycn6oXvBJ8Enhj8hvcO/Re9Fr90RJq51CW9s6MjvVlcoI/NhleX3EEk7l9ThVHctY5szl/M0cqjlBQ20GVBo1GmT0HJZP7OU6W5db15uPUztKevhasTeQYXUHvdM5Gc7VwddIxpDn53vpuNns+P3E+PkNuBI0W8nYpF5GFTtlsMjuylDXOwxw5OJdlbCkr+UnbCE4enB9zPs46MZ64oLms2rojJVTWN3VpX7QaLfcOvZdXJ75KnHdc+w28oyB8hBJBeeBHh/fvbHTKg/P//e9/J/wnnJ3WJJdgk6FPsDuhaoY7maogcwMAlrjzeGnbS/xt5d/IrekeGZW7St9gDzQSFNWYKKwydWlfgt2C6e/XHxmZ1d7+4uTnNNU3WdiaroS0T0pQP+rIzeBGpEck1JdDSZJy4zlU3/xEbpkQg6+bgfxKE59vzurSvrjoXVqTX+4o2tHxRtETlP8zN5zz5QzTSuooqm7EoHNMSDtArosHwDlV2rMzR0PbS5C72/Im90CIm4kZWVxA/gtpJbVU1ptx1mvpF+LhuIaLD7GlPoc8Dbi6BDAzaqbj2u7Gegd5EBfohsUqs/RAYVd3hyDXIFz0J8jan3iZ8n/y76LuuR2cVp3zY//dfvvtzJ8/n1tvvZV77rlHhS4KXU2WZVYeUkLap6k9a566UllH6RdHul7CZDXhpncjxC1E3Xa7OWeDllg/5aLInpzKru0MR2fP1xTvxNJrunKjOPk5JVvSyzBbZUK9nIn1d1WljV1Fu9hasLXtSXPONuV/v3hwVTl5Vg/hbtRz1xQlvH3x3nz2d3GEyrCgYQDsLNrZ8QYhg8HgpuQNKD63L4ptaq5tPizSW90EVlV5ULifOgkqdDqAcz6sHWBktC96rUR+pYn00u4T2g5QUFvAC9pqXtY3KFnbRZWDTrWEtA+O8EKvVbHawXFsqatYpG0EgxuzY+eceAB4jrlwkFK95ff9Bd0iYSko44E12Wv4MeW4GfKw4eAZpiy3aknoLJy2U/4EVlRUtPlXW1tLcnIy48aN4+uvv1ajj0IXSyqsIa+yASedprW2qXqNNYe0J8xmc76yLrafbz80kuMOFt1VvyBlALcvt7JrO4IyePA0eFLRWMGusP4gaZSTn5ZwaeEvrW2ufDAxwV+VzLQmi4kP9n/AaztfY13uuqN35LSEtItZ82MNjfRpzZL75qojNDR1XXj70ACl3nlyeXL7BDyg5AmIbF6SkPGnA3vWvciy3JqMbKzaIe3NdXxzAxNAo8PH6CMGEigXjlvWKP/ZvEynu9BIGvZVZ7DX6Kxkbt/zZVd3qdvakdkFIe02G9vTfiNXsuLs4ses6FmOa7sHGBvri4+rgcp6M6uTirq6OwAkVyTz7r53+T75ezKrMo/eodFA/+bZ8wM/nvMRXWfKLiOeuLg4XnjhBRYsWGCPpxO6mdVJSgKIMSqXeqI0RSnNpTVQFzma1dlK3cspEVPUa7MH6RvYMjivwmbr2vBBvUbPJfGXcEO/G+gXNRn6XqjcsfpZqDq3lyCcjMr6JvY2R0ColaX959SfKTeVE+AcwJiQMcqNNivkbFd+FuvN27lxbDSBHk4UVTfy8caMLuuHv4s/vbx6YcPGkrQlHW8UNV75P/PPc7ZaQmZZPQVVJvRaSd0kVrLcOjjPCUwAxKz5sVou2m9ILe1Woe2BroFMCJsALj7K7Gz6GqjM6epudTuV9U2kFCtZwYepvTTkGLb8XSyylIKkZXbCPFz16kSQ9VQ6rYZLhiiz519uze7yfCgAvX16Myp4FDZsvL/v/baZ9eNmKhFdVblHS7UKp8Vu05E6nY78fJGl72xjMltbk1ZN66Pyutik35T/o8axomgrJquJcPdwBvoPVLfdHiLG1xmjTktVg5ms8q5f03Ne1HmcF32eckAdfQcEJirZjP94HMwNXd29bu3PlFJsMsQFuqlSsqagtoAl6cqg7rp+12HQGpQ7cndAU61S/sS/j93b7emcDVoWTI0H4I9DRVSbuq5U2bz4eQAsy1xGaUMHybbCRyjVEqrzoTzdwb3rHlqytA+J8Fb3wnFNofI+a3QMS7ya+4fez9yYueq118MMi/LGqNdQVN3YOsjrLi7udTFavQt7jUaSMcOer7q6S93OjuaQ9l4Bbni7GhzWrpS2mnkWJ/q4RzI7VnyeOjK7fzCBHkYq6838vDuvq7sDwPx+83HRuZBWlcayjGVH7zC4KHXPAfZ/3zWdO0uc8uB88eLFbf798ssvvPvuu1xzzTWMHTtWjT4KXWhzehkNTVYCPZxIDFGv1BOWJmW9OWCOn8nSDGXNygWxF6gS8tsT6bRSa6KWvd1g3XkbWj1MXwjO3spAYd1L5+xs3sloCWlXIxGc1Wbl4wMfY7FZGOQ/iGGByvplytJg9TPKz9ETlDA0oZ3+YZ7E+rtis8lsSu26DNQD/Qfy/+yddXRU59aHnzOWTNzdSQIJMUhwhwq0l7bQUi+lQm+F29tSod7yVahQNyqXugstLVLcXRICxBXi7snY+f44EYIGyGQmyTxrzcrMnDPn3TM5tt+992+P8BrBTYNuwlF1mnOvUi3V+UG/VG0XRZEtrRPHY8KMnNLeVtfvFoaTnTfDvYcT7R5t3DF7EdbKjtT2LWaW2t4RPXeVoucZ/0Dtabog9GP2tqu091zUnJrjCNmbGCYqeWHE09ip7Hpu7F6EUi5j9qhAAH4/UGBy5XYAZ2tnbom4BYCf0n7qPHk8eIZU5liwHypNl33W2znvu7Nrrrmm02PmzJm88MILxMTEsHTpUmPY2IkPP/yQoKAgrK2tGTFiBHv27DH6mP2Z9a29zScP8jRub/PcrVLU1c6TPDsXmnXNuFi7MMrHknp7IrF+0k26OYjCAWgNWjbmb+TVPa+iVTvCpf8nqbdnbbDMnJ6Bopom0kvqkAkwrpvrZJt1zSzet5hD5YdQCArmDJ4jTW5VH4MVj0jHmEckjHygW8fta0wYKKXpbjahoyEIAvMT5nNlyJVS+7vTEXxCans/I72knuKaZqwUMkYGG1nYsDRF+uthyTY5Eyemtpu67OpkZoTOQK6yJcnaijSxBQ5YOgu1odMbOJhfDUBCYA/VmzdVwcrHJfEw90GSwKWFMzI21I1QDzuatHp+3GseZRmTAyYz0Hkgzfpmlh5e2lHO4uANQWOl54d/M52BvZzzds4NBkOnh16vp7i4mO+//x5vb29j2NjOTz/9xPz583n++ec5cOAAsbGxXH755ZSWlhp13P5KaW1ze1/tKcZOaU9rVXccOJVQl3A+nPIh8+Pno5Sd4aa0nxLj7wTA0cJadHrTC24ICPyY9iMHSw9KytLeMTBqnrRw18dSizULndjcGjWP9Xfq9hTC43XHSS5PRilT8lD8Q3jbeUtRor8flm6IXENh2mtS+pmFMzIuzB1BgMMFtZTVtZjaHIDOtX1tBI6WohQVWVLadT9iU5p03R8Z4mrclHaAkqMANLqGsixjGfuKz9Dirh8THyiVFlTUa0gtrjO1OZ3oiJ67sVaugfTVUGXalonmwtGiOpo0ehzVSsI8eiB6rW2G1U+xvD6bZbbWVE1aYMniOgcymcCc0UEArDpcTGG16csGZYKMuTFzUQgKksuSO0fPo66V/maskdojWzhvetUR8dZbbzF37lzuuOMOIiMjWbJkCTY2Nj0Sse+PbEgtRRQhxs8RTwdr4w1UVwwFrTc74ZJap53KjjDnMOON2UsJcrHBQa2gSasnvcT0tX0KmYJJ/pMAWJcnlSUweAaEXQaiAda9APWWybM2RFHsUGk3ghBcqHMo/xnyH54d+SzDvIZBfRmsmA8NZeAcCFculurNLZwVNzsrBreW8ZhDmu7e4r08uvlRMqtOagVl7Qg+cdLzfqTartMb2Nqq0j5xoJE7iOg0UJEBQJ7ajh/TfuSLI18Yd8xeiEohY2SIlMGwJcP0x8zJzAybyd1D5/Fv30uka9M+y30jwL7WlPahgc7GzY4EScF7w4voSo+wXKnnRzsbcrUW560rxPo7ER/ojMEg8s0u85hY8rf3Z/bg2Tw49EHcbU44D3vHSoEAXQuk/G06A3sxiq6sNH/+/C5v8K233rpgY86GRqNh//79PPnkk+3vyWQyLrnkEnbu3Hnaz7S0tNDS0hH1qK2tBTqi/+aKwWBAFEWT2mgwiKxLKUFEZPIgd+PakrYKQRTBZwg5+iYC9XpLnflJtO0TIBLl48j2rHISj1UxyMv0dVqT/CbxR+YfJJclk1+Tj5+9H4ydj1CZLanvr3kGcfp7knhVPyertJ7j1Y2o5DJGBDtf1HHVtk+kVaShVqoJcAgAYJinVIdsaKhAWDFfiqjaeyNOWwxWjpYWJ11kfJgryQXVbEorZcYQH5PasrdoLwV1BXyX8h3PjHim8/kxcCxCwQHI2YJh8LUmv3b0BAfzq6hu0uBgrSTG18G437c8HUGvBWtHjhmaQQRfW99e9Rv31D3F+DBXNqSWsDWjjDtHB6LowX7Z58LN2o0p/lPANgQxfydkb0IsTQW3cFObZhLa9om9uVWIiMQHOBl3/xBF2PEeQu42DiqgzsEbBxs3olyietWxZEpuGxnA/rwqtmaUcU2sN2Ge9t26/Qs5T1wacGn7ZwFya3NxVDniHHUtwubXYP8XiHoNxN5kuQeELv+2XXLODx482KWNGdOhKi8vR6/X4+np2el9T09PUlNTT/uZRYsWsXDhwlPeLysro7m52Sh2dgcGg4GamhpEUURmonSf1NJGjlfUY62UEWpvMF7pgGjAKflP5DotiY4DWLTpUcIcwvhv5H8tvc1P4MR9IsgBNmt17M4oZnKglalNAyDCPoKkyiS+P/Q9c8LmACAb8iCO6x9DVnSY5nWv0zDkHtMaaQasOFCCTqtjiLc99dWVXEzug8FgYMexHfxc9DN2Sjsei3oMZytJ0EfQ1OOw5XkUNTno1W7UjngSQ4MBGixZDF0l3EFE1OvJKK7hYMYxfB1Nd6xNcJnAprxNJJUksTljM5FOke3LZHaDcNZpoSCR8vw0qltkJr129AQrDxZIx1GwPZUVxhXts87cja1Oi8YukJTiVLQ6LU6CU68qp+upewpvlYhaLlJR28Sm5FxifEw/eXwqtth6jURxbDOGLR9QN/YZUxtkEgwGA1mFFeSV1SITBPzUWqPu09bpf2Cb/AsgsNY3Gq22lFiHWCrKK4w2Zl/DFhjuZ8P2nBo+Wp/KE1MCutXvutjzRHlzOW8cfgOlTMkDYfcQ7hqNquQA7P4M/eHlNMTehdY7odvs7Y3U1XWt5KdLzvnGjRsvyhhT8eSTT3aK+tfW1uLv74+7uzsODuab2mkwGBAEAXd3d5PdYP2QnIFCqWByhCf+Pl7GG6giE0FTBdb2bLFqRKlQEugaiJenEcfshZy4T4yzduS7g+Xk1WhxcHbFWmnkessucIvVLRzddpTEmkQMtga8bL0AD5j6IsKqx7E7thHbkbeDY//tDWwwiBwszkOhVDAtLhAPj4sTsdpRsIMfCn9ArpAT7hZOoHcg1gprEA0If/0fNBwHew/k09/FrR//7hfDiAHV7Mmt5HCFgSFhRtbdOAseeHBF3RWsylnFP6X/MD5s/AmTlx4I3lFQloZHYzq4jjTptcPYNGv1JJdko1AquHJoMB4e3Rs9Ohnh8HFQKJEHJVDdkotSoWSQ1yA8PEy3P5wvPXlPMTmygRXJRSSX6bgkzvx+ox2FO/jFuorLrASuqEhGrS+WtFL6GQaDgfUZVSgUSqJ8HQn2M6JmVNYGhJQfQKGkbtidHClag1Kh5IpBV+DhYH77iDlzz2RHDn53gKwqDflNyvYuCd3BxZ4nxEYRJxsnihuKeTfzIx4e9xDRteUIuz5C0ViB1Z43IGAU4qh54GDabDRTYW3dtRLhLjnn5oCbmxtyuZySkpJO75eUlODldXpHzsrKCiurU6MdMpnM7G9cBEEwmZ3NWj07syoREJgS6WlcG4qSpD8e4ewtOwgCTB8w3ez/P6agbZ/wdbbBw96asroWUorriQ/swfYnZyDUOZQ4jzgSyxL5M/tP7ou9T1oQMAICRkH+ToTE72HSk2ffUB/mcGE1lQ1a7KwUJAS5XvQ+vip3FSIiE/0m8u/YfyOXtU7SpK+FkiOgsoN/vYXgHNgN1vdPJg70YG9uFVszypk9Ksik5TYzwmaw8dhGcmtz2VOyh9E+ozsWBo+HsjRkedsR3Eb1imvchbInt5wWnQFvRzUR3g7G/5+0KrULnoMpOLodBAh0DOx1v29P3VNMGuTByuRiduVUotGLZjF5fCJN+iaKNdWsd3LhiopaZPs+h6veh35YSpdU2AACDAtyMd5+UZwMm1+Vnkdfxx4XH3SFOgIdAglxCjHOmH0YT0c102N9+P1AAV/vymdYkGu3agVczHnC286bl8a+xJv73iSlMoXX9r3O/XH3M/aGb6UOCck/S/eCBfsh7mYYcqvUhrcf0dXf9YKOxn379vH4449z4403MnPmzE4PY6FSqYiPj2f9+vXt7xkMBtavX8+oUZZ2W93J7pxKmrRSb/NIbyNnGBRKJRN/W4GIyFCPofjbW6J8Z0MQBGL9nAA4dLzapLacyMywmUS4RDDOd1znBfG3S38z1kBNQc8bZga06DpaoIwZ4IZKcXE3QnqDnrw6SRTm6tCrOxxzvQ72tYpVDbkVXCw3PxfD8GAXrJUySmpbSCsxrQK1o5Uj0wdMB+Cn1J/QGXQdC4PHS38LDyJoTC8UaUxOFFQ0umPeWAl1RSAI1Dr6UqORxKt87Ppn1KcrDPS0x9PBimatgT05laY25xTG+o7FWm5NgdKKowqZ5Dwe638teZu1etJKGwG6Nfp6Cjs/Ar1WOkeNfIDNBVsAGOc37hwftHAmrov3w85KQX5FI+tTzau8xl5lz9MjnmaMzxj0op7PDn2GVq6EkffCdUvBNx70Gtj/Jez5zNTmmi3nfYf4448/Mnr0aFJSUli2bBlarZYjR46wYcMGHB0djWFjO/Pnz+ezzz7jq6++IiUlhfvuu4+GhgbuuOMOo47b39jYerBPHOhh3Jsfgx6KEqnBwOamIoD2m08LZyfWXzrWksyk3znAQJeBvDD6BaLcojov8IgA/xGSQu7Bb01jnAlp0uhZ+NdRko/XoFLIuDLm4tMHC+oL0Oq1WMut8bQ5QYcjbaXkTKidYfA1Fz1Of8daKWdUqwJ1Wws8U3JlyJU4qBwobiyWWhe24RQgqfEbdCiL9595A72cmkYtB/OrgB5QaYeO/uZOARzXSON6qD1QK9TGH7uXIghCeyeKzWbQ6eBk1Aq15BjKFazxkEQ02ftZvxPKPHS8Bq1exNPeGn8XI+3P5RlQehRkChj7MDoMeNp4Yi23ZqzvWOOM2Q+wt1YyK8EPgO9352EwiCa2qDNKuZJ5Q+bhZOVEs76Z1MpWXTDnILjyTRj3iPQ6ZTm0mFfbRXPhvJ3zV155hbfffpu//voLlUrFu+++S2pqKtdffz0BAQHGsLGdG264gcWLF/Pcc88RFxdHYmIiq1evPkUkzsKFU92oab/5mTTIyLVA5RmgaeAfKxlamZxQp1AiXCKMO2YfoS1ynl3eQG2z1rTGdIWhs6W/Gf9Ifbf7CfUtOp778zDJx2tQK+UsvGowIe4XL5KUU5MDgL+tf0ftsU4jpY6BFDVXWhyI7mBCqxO4LbMcvYlvgtQKNXdE3cGTw59kuNdwAEobS1metZxc7ygMiKgKdpvURmOyNbMMgwihHnb4OdsYf8BSqb85HoMJcw7jjfFvcF/cfcYft5czIVy6d9ifV0WdGV6fLg2UFKb30kyV0kq6F8ndYmKrepa9edJ9XkKQs/GCMEf/lP4GjwcbFxQyBfOGzOPzyz7H2dr05Xi9mX/F+GBrJae8XsPRolpTm3MKMkFGnEccAIfKD3UsEASImA4uwaBtsrRaOwPn7ZxnZWVx5ZVXAlKqeUNDA4Ig8PDDD/Ppp592u4EnM2/ePPLy8mhpaWH37t2MGDHC6GP2JzanSzc/YZ52+DoZ+ea+8AAGRLZaq9przS0t1LqGs62KABcbRBGSj5tXn9BaTS0/pP7Aj6k/drzpFQV+CVK2RGL/iJ7XNGl5ZlkyqcV12FrJeWlGFFG+3ZNdZKu0JdotmnCHE9oApSyX+pnbukPEVd0yjgVpIsxBraC6UUuSGZSRjPYZTZxHXPu58kDJAb5L+Y4F5du5T1nH/yq2UVHfNyfA2rIXeiRqDh2Rc48IlDIlAQ4BRLpGnv0zFghwtSHYzRa9QWR7pvmpcQc6BBLuHI5eENjo35rptfdz6frUDxBFkX25knNuNM0aTSNktpahRna+Hin7WZ2xMVApZAxvLUfYmWV+xxjAv0L+xYtjXuSmQTd1XiAIEH299PzI71I5noVOnLdz7uzs3C4F7+vry+HDhwGorq6msbGxe62z0OO03fxMNnbUHKDgADIE3hl8Dy+Neak9EmSha7SltieaUWo7QF5NHn9k/sHf2X9T3VzdsSB+jvQ3bRXUFZvCtB6jqkHDU78nk1XWgKNaySszognvxp6kCV4JPDXiKa70lyZK0TZ1lAzE3w4KSz/R7kIhlzE2tDVN1wxS20/G3cadoR5DsbZ2pEYuZ7ushRX73jW1Wd1OUU0TqcV1yAQYF9YDzrnBcIJzbnHIz5eO1Hbzqoltoy16vo4GDNb2UH0M0v8xsVXGx2AQWXawgIqGFpRygWhfI+kKZa4FbSM4+YN3HEX1ReTV5hlnrH7KmFA3ALZnlZtdajuAv70/4c7hp2+LHHqJVH5XXwo5m3veODOny855mxM+fvx41q5dC8CsWbP473//y9y5c7npppuYMmWKcay00CMcq2wko7QemUxgXKiRb370WkmIBZD7xhPmHGbpa36emKMoHECUWxRhTmFoDVr+yv6rY4FXNPgObY2ef2c6A41MWV0LT/x+iPzKRlxsVSyaGd0tqexn5fDv0FQltScJn2bcsfohbY7GzqwKWnTmFV2L94xnwfAFfH75/7jZawwA6bnrYc0zfaqEpG1iJMbPCRfbHph8qs6TnAuFNQbnQD5P/py/sv6iSddk/LH7AONbj5kjhbWU1bWY2JpTGeU9igl+E3hgyIMIsbdKb+7/AnTmZ2t3kVvewKO/JvHF9lwAxoU4YaUwgpq+KMLR5dLziKtBEPgj6w8e3/I4P6f93P3j9VOGBDijVsqpqNeQUdrLhEAVqg5dnEM/S/uMhXa67A3FxMQwYsQIoqOjmTVrFgBPP/008+fPp6SkhGuvvZb//e9/RjPUgvHZlCbNcMcHOONoY+S0o9IU0DWD2gmcg407Vh8lytcRmQCF1c1mdfMjCALXhV8HwNq8tdS0nJB2P7RVuT11pTRj2seobtTwxG+HKKxuxsPeilevjcbfpXtrY5t0TdRqTqgx09RD0g/S8/g7QN5rOmT2GgZ52eNhb0WTVt+eDmpuKGVKRoyYj8HKiVzBgDZnC/w8W1Lv7+UOhyiK7SrtPZ7S7j6QFbmrWZu3ll/Tf0UumFdrMHPF3d6KKF8HRBG2ZphfxolSruT+uPsZ7DYYIWoG2HlK16RDP5natG5HozPwzc5c/vtTIhkl9ahVcu6bMIBbE4yk11R6FCoyQa6C8Mtp0bewq3AXwKmCsRYuGJVCRkKQVJawI6vcxNacnuKGYj499CnvHXjv1IWRV0v7SFlqe7DOgkSXnfPNmzczePBgFi1aREREBLfffjvbt2/niSeeYPny5bz55ps4O1sEHnorBkMP3/wUHqAGA/+xauKz5M8xiP1LKbU7sLVSEOohpUqbk2o7QKx7LAMcB9Cib2FF9oqOBT5x4B0LBh0kfm8y+4zF8qRCSuta8HK0ZtG10Xg7dr9uw97ivcxdM5e3978tvZH8i6R46hwopYpZ6HZkMqE9EmiOCtRtuNv7YesYhOAygALPgR0ta36+HXK29NroRFZZPQXVTSjlAqMGuPbMoKVHAMhz9uXHNEk/Y3bkbFRyS8lIVzFn1fZOKKxgxD3S88TvocE8HZ0L4XBBDf/54QA/7zuOwSAyMsSFj24ZyrQoL2RGE4JrjZoPmAzWDuwr3kezvhkPtQeDXAYZZ8x+yugBrantmRWIZnp+X5+/nl1Fu2jUnlT6rHaGsMuk58m/9LxhZkyXnfNx48axdOlSioqKeP/998nNzWXChAmEh4fz2muvUVzct2tI+zpHi2oprWtBrZQzIsSIPS/bKDjAEZmeUplAelW6JaX9AolrrTs3t9R2QRCYETYDgH9y/6H+xN7LbbXnqX9DvZnftJ0HGp2BNUdKALhjdBAe9tZGGadNqd3F2gWhpRah7aKWcCfILMeRsWhzNPbmVlLfYp4CNoIg8MjgR1h6xXcEXf0pXPK8JBBYVwRrnoVVC0DTYGozz5u2ieMRIa7YqHooM6Q0BS0iH9SloDPoGOoxlMkBk3tm7D7C6FA3ZDKB7LIGjlWapyZRaWMpXx35imWGWvAcLOl37P3c1GZ1C9/uyuPJ35MprG7GyUbJk9MG8fSVkbjZWRlv0OZayNogPW8VgttyvKO3ueVer3uJD3RGpZBRUttMTrn5ndu9bL3wtfNFL+pJKks6dYVoKcuS3K1QU9Czxpkx532U2Nracscdd7B582bS09OZNWsWH374IQEBAVx1lUUhuLfSltI+JtTNODVIJ6JrgdKjJAk6UNoQ4x5j3PH6MLH+TgDszTW/ljUJngkE2gfSrG8mufyElCWfIVL9uV7bkY7dB9ieWU5NkxZXOxUjQowX3WtzzoMcg1Cn/yHdTLqGQtB4o41pAYLcbAlwtUGnF9mRab6RNQ+1h6SGLAhS5OqGb6TWenIlHNsNq58AbbOpzewyBoPIlgzp954Y3kMp7ZpGqMzhZ3kL+bo6HFQO3Bt7r6WbyHniYK0kPkDKqDTX6HlebR4rc1ayIncl2hH3Sm+mrYKyNNMadpGU17fw875jAEyN8uLjW+MZ3SogZlTS/5EydlxDwSOSquYqDpVJrbTG+1muUd2NWiVvV9zfbqbXpaEeQwE4UHrg1IUuweA/QsrqOvxbD1tmvlzUFFZoaChPPfUUzzzzDPb29qxYseLcH7Jgdmh0Bra23vxMGtQDNz/FhxH1Gg4pZaBQEe0Wbfwx+yiDfRwJcLGhvkXHT3uPmdqcTgiCwMzwmYQ5hTHSe+SJC6TaaICUv6DBPNuAnC8rkiXxrWlRXshlxrmJN4iGduc8ROWMdeZKacGwuy1R8x5gQqtKuLneBJ0WpRqGz4WrPgCVLRQdksTidBpTW9YljhTWUtWgwc5KwVBjtX06mfI0jqLhL6UBZAr+HfNvHK26pw1if2PCwI7UdnNMux3qMRQXaxfqNHXs0td0pNnueL/XloGAJKAoihDp7cADk0Kxs+qBjBNRhJTW3uaRV4EgsOnYJgwYCHcOx8vWy/g29EPaSn12mGlLtSGeQwA4WHrw9CWsMa1t1dJWSiV6Fi7cOd+yZQtz5szBy8uLxx57jJkzZ7J9+/butM1CD7Evt5JGjR5XOxVRPj1wA1J4gELBQKVShUKmIMI1wvhj9lHkMoE7xwYB8PehIgqrzUtJeITXCB5JeKQ94tSobWTR7kUctlKBZ5Q0w77hxV7jKJyJzNJ60orrkMsELh9svBuQkoYSmvXNqGQqfDI2IBg0UpungJHn/rCFi2Z0qHQTlHi8xmxT20VR5MsjX/L45scpbTxBdNFjEEx7DRTWcHwvrF/YK/rLtvWWTwhyRinvoQmokqOkyfSISmsm+08mwSuhZ8btg4wIdsFaKaO4ppn0EvNTlJbL5O3lCqtzVyMOmyvVoBcnQ/Ym0xp3EWxqzVTokYBLG0WJUks6pQ2EXoooiqRVSRkIk/wn9Zwd/YzhQS4o5ALHq5rIrzC/8pGBzgOxUdhQp6kjszrz1BV846UIurYJUv7ueQPNkPO60hUWFvLKK68QHh7OxIkTyczM5L333qOwsJDPPvuMkSMtN4i9kQ2p0g3cxHB3ZEaK+HWiMJFkQQcqGyJcIrCSG7H+qR8QH+hCfKAzeoPIlztyTW1OJwRBwNm6I9q1ImcFiWWJvLj7JV5yVJOlVELhQVj3Qq9wFM7EikNS1HxMqCtONsYTjGqLmgeqPVGkSlFzMeFOKRvBgtHxc7YhwMUGg0Fkb06lqc05LYIgkFGdQV5dHhlVGZ0XekXD5a9ICrm522DTK1I/bzPmSKHU7WFwT0wct1F6lBl6K54JmsHswbN7btw+iLVSzsjWMh9z7Xl+ScAlWMmtyKzOZHP1UYi9SVqw+5NeOXGcU95AbnkDCrnQ3gu7R2gTggudAiobBEHgsYTHuCf6Hib6T+w5O/oZtlYK4lpLHM1RtV0hUxDrHgvAgZLTpLYLAkS3Rs+P/N6r7wW7iy4759OmTSMwMJD333+fGTNmkJKSwrZt27jjjjuwtbU1po0WjEhts5Z9eVJroMmDjNRW40Q0jVK9uUyqN7ektHcPd44JRiZIfZgPF9Sc+wMm4rLAy5gWNA2FoCC54RhPOdmwWyFC3vZe4SicjtpmbftN55XRPkYdK7smG4DgujIwaNG6R0mzzhZ6jJGtKYQ7s80zhRAg3CkcgPSq9FMX+sXDpf8HMjlkroeti832uNPoDKQVS2mOUb4OPTOoKEqtoIDokEtRK7q/40J/o01McWtGORqd+e1rztbO7e0/vz36LXUR/+oQUuyFKtJtGkLDglywtzZyW9w2GiuljhCAGNGhPyWXyZkSOMUiBGdk2lXbzTS1fajnULxtvXFQneE8HnqJpN5eXwo5m3vWODOky0eLUqnk119/5fjx47z22msMHDjQmHZZ6CG2ZZSjN4gEt4odGZ3iQyAa8LdywdshgGh3i3PeHQS42nBZazr151uzMRjMs1bO0cqROVFzeHvS2wzzHAYqNT95h2CQySRHYdtbva7Ob93RErR66RiK8LY36lhRblFc6jmCuJIsABojbzbqeBZOZUyrc74/r4pmrd7E1pyeMOcwgFMj520EjoLJz4Igg9QVsNM862szSuvQ6kWcbJT4OhnfSa5srmTxzhcpayyXJi/cwo0+Zn8gzt8JVzsV1Y1as9VruCL4Cvzt/anT1vF77koY3tpa7eC3kuPZS+jxtrhtpK2SWqR6RPJ9+V6WHl6K1mBeIrV9mREhLsgEyC1vMLvyRoCxvmN5Z9I7XBFyxelXUKhg8DXS80M/m+X1qCfpsnO+fPlyrr76auRyIyt5W+hRNramtE8e5NEzAxZIKS03+1/KO5PeIcQxpGfG7QfcMiIAtUpOVlkDG9PMM32wDQ8bD+6Pux+1Qk2BoYmk+Jul1KaUv6RUwl5yYjYYRFYmS20kr4j2Nrqac5xHHHfXNRFvkIP/cHRulp6xPU2wmy2eDlZodAYOtGYdmRthTpJznlubS4u+5fQrDZgEExZIzw//Dge+7iHrus6RgloAIn0cekQp/YfUH9hbtIuPFa0dEBSWkqvuQCGXcUW0NwB/JhaYpTCcQqZgbvRcLg+6nFnhs6RInkcEaBt7VWu1QwU1VLYKKCYE9kBbXJAyb1L+AmCHzyCWZy3nn9x/OFpxtGfGt4CDtZIYPyfAPIXhupQ5EXGVVHJVliqVO/ZjLHkm/ZiimiZSi+uQCTC+p1rUtB1wvkN6Zrx+hJONihsS/AH4emee2Ub12rBR2nBJwCUAbBYbYPxj0oKkH6RoRS/gQH4VJbXN2KjkPROlqMyBzLUAiPF3Gn88C6cgCAKjWlMIzfEmCMBN7YaztTN6UU9WddaZVxw4Fcb8V3qe9IMkyGNGtNWb94RQqUavYU/RHtA2c4PeSnLMLHQbU6O8UMoFssoaOFpUa2pzTstAl4HcGXUnNkobqfvFqHnSgrSVUH6GLBQzoy3gMjbMDZWih27xszdAXRHHrKz5pGIfAFcNuKq9zthCzzCmVbDUnFt9avXadu2cU7BxgUGtkfX9X/SaII0xsDjn/Zit6dIBHOPnhIut8USs2mmuhYoMsgU9Wk9LOrsxmB7rg6eDFZUNGn4/UGBqc87JtOBpPBD3APOGzINBV3bcDO39vFf0vPy7VQju0khPrJXGzSoqbigmfefbaEQDBI8Hd0tpkakY3Zravie30ixraAVBaK87P2NqexuDZ4CDj+SY55pPxxW9QSSlqK3e3PjOeWJpIs36Ztz0esJFOXgMNvqY/QkHa2V7ht7yxEITW3NuRFHkmK0jDJgsOQn7vzS1SeekWatnZ+uE4aSBPZQN2VQFO96nAZHFDmqaDRqi3aK5ceCNPTO+hXZGhrgiCJBRWk9pbbOpzTmFssYy7l5zN8/veB6N/gxCi3G3StHzokPtmbb9EYtz3o/Z3qrqOC6sh9Q8ixKpFw08ba3l7m2PU68xv7YqvR2VQsac0cEA/HbgOOX1Z0hpNRNc1a6M9xuPQtbagzVmFsTPkZ7veB9KU01m27kormnmQL6U1jytNWXTmGw4+iPPlm7hK0UzJFii5qZkoKc9TjZKmjR6kguqTW3OaQlzDsPTxrPj2DoTggBhl0rPM9YY37Aukl1WT5NWj62VnEAX4+uh7CzaCaLIyBYtAoIlcm4Eror1BWBXdoVZOg9tNGobeXHXizy59UlKIv8lvZm3XWoTZsbszqmkSavH08HK6Pon7ex4H0NTFR/YKSlWqnBXu/Pg0AeRyywlsD2Nk42KwT6S4Jo5Cpa6qd2wUdrQom85bclDaWMp76X/wEuuzjQgwr6l/TZ6bnHO+ylFNU1klzUgE2BEa5sTo1N4kCMyHQaVDa5qV+xUdj0zbj9jTKgrEd72aHQGvtmZZ2pzuozeoKdJ1yQ5523Rit0fm+3JeWVyEaIIQwKcekSsKjtHSmcP9hwq9QS1YDJkMoFRA9pSCM3vJgjgypAreW/ye1wZcuW5Vw5tdc6P7zUb8asjhVLq82AfR6O3+NToNVKLH10LI3UCWNmDo59Rx+yPBLjaEOvviEHsyDoyR9QKNQICWoOWpcfWIAaMlq5Dh34ytWlnpS2lfeJAjx7RaCB3G2SuZ7/MwAEbO5RyFfMT5p9ZkduC0WlXbTfD1HZBEBjqMRSAA6Wdo+J/Zv7J/E3z2V64nWS5ni0KA5QchmN7TGGqybE45/2U7a03lNF+jjiqe6jVRsEBDgk6UKqJcYvpmTH7IYIgMHecJLS3IbWUzNI6E1t0bvYU7eG/G//Lr+m/SpG8Ef+WUpsKEyF/p6nNO4UWnZ61R0sAuLIHouZiUTK59YWAQHDMbUYfz8K5absJ2pVTYZbdEc6rdZGTP3hEgmiQuiaYAckFbf3NjX+jf7D0oJTSLigIFeXSb9ETzk0/5Oo4KXq+5mgxTRrz1EURBIG7ou9CIVOQWJbILr/WEof0f8xm8upkqhs1HGzN5JrUEwK/zbWw9S0AGoLH4mTnxaWBl1pEfk1M26RxSlEdFWaYOTnUs9U5LznQSRjSIBrQGrS4WLuATME2l9bWzv00em5xzvspbYIRY0N7KKW9sRKqcjnU1t/c0kLNqIR52jOpVaDsl33HTWzNuVHJVZQ1lbEubx2N2kaw94Koa6WFu5eAwbxu4rakl1PfosPD3ophQcZXxC3f+zF1gojc2pEA3+FGH8/CuYnyccDOSkFtk85sBa5Auulp0nVB6K0ttb1VcNCUGAwiR1sj5z1Rb64z6PBQuzNKJ1hS2o1MfIAzPk7WNLTo2ZBqvl1FfOx8uCb0GgC+Kt5Ko3s46DVw9A+T2nUmNqeXYRAhzNOuRzK52PUxNFaAkz8TJy7k40s+5oaBNxh/XAtnxc3OioFeUkmDOfY8j3KLQilTUtZUxqZjm9rf/1fIv3gs4TFeHfcqMmRkygWKFApJuT1vh8nsNRUW57wfUlLbTEZpPTJBEpDoEQoPUoyBUqUSuVxFpGtkz4zbj7kuXlJu35VdYfa157HusfjZ+dGsb2Z9fmvkbsgtUnppVZ6klmsmiKLIymQpJXNatLfRU24p2E9OSSIg4OcRg1LeQ5kuFs6KQi5jRIg0MWOOKYQAa/PWcuc/d/J9yvdnXa9WU4s2aKzU27ssDapye8bAM5Bf2Uh9iw5rpYwQN1ujjzfGdwzveV/G9RWlIFdKbeYsGAWZTGB6rA8AfyUVmmXWSRvXDLgGb1tvqlqqectOQRMiHFkGWvOrl9/c2tu8R4Tgju2RrsmCABOeAIUVMkGGtcLa+GNbOCdtOlLf7crjWGWjia3pjJXciii3KACWHFqCvjXwopQrSfBKwNHKkRj3GJDJ2ebX6if0w+i5xTnvh7TdSA72dcTJpgdU2gEKDpAs04HSlnDncNSKHpjZ7ecEuNoQ5euAQYTVh4tNbc5ZEQSBf4VIwjsrc1aiM+gkx3zo7dIK+5aCxjwuMkcKa8ksrUcpF7g00tO4g4ki7F1KtqAHtRMhbpZJLXNiVOvk5s5s80xtt1Pa0aRrIq0q7YzrpFWmcf+6+3nz6FLwHyG9mWHa6Pnh1hZqg7wcUMh74Dal+hjCzg9RIcCwu8E5yPhj9mOmDPJErZJTUN3EwWNVpjbnjCjlSu6LvQ9ruTXJLZV8ZiOX0rnTV5natE4cq2xsD7iMDzNyS09NA2x5Q3oedR0Vjt4YRPPrWNGfmRblTaS3A40aPf/391Fqm7WmNqkTU4OmYi23ZpT3KJr1p050TfCfwHCv4QwcfCMobaAiE3K3msBS02FxzvshbfXmYwb0UEp7UxVkrZecc5WtNCtmoUe4orUe+p8jxWj15n0BHes7FkeVI5XNlewsbK0zH3yN1OapsdJsxHh+OyCVCUyJ8DS+XsOxPVBymBwZYONCsKNFCM6cGBLgjLVSRkW9hswy8+s+Ee4stVM7VnvstKntWr2WTw59gtag5WDpQUr9h0kLMteBwXTniyPtKe3GrzfPrcpCu+FF0DWDzxCIvt7oY/Z31Co5l7VObJp7W7WBLgN5ZuQz+Dv4c+Pg1sniQ7+Y9Pg4mU1pUnnA0EBnHG2MfE3a/QnUl0rX5WF38dKul7h37b1kVWcZd1wLXUalkPHUFRF4OlhRXNPMopWpZnX/F+cRx1fTvuKh+IewVZ6aGTXaZzSPJDxCjN8YiJopvbnvC7M65ozNOXqsWOhrlNY1k15ShyB09Oo1Okk/gbaJGa6DCI6aQYLXsJ4Z1wKjQlxxslFS3ahlZ1YF48ONPKt+ESjlSqYFT+PHtB/5O/tvxvqORZArYfhcWLdQcs4jrwYb49d4n4n8ikb25VYhCHDNEF/jD3joRwCuDb6C6MB4i5CimaFSyEgIcmFbRjk7MssJ9+yh9kVdxFXtiqu1KxXNFWRXZzPYrXPv7uTyZArrO5yjXUqRq5Q2UFcMxYfAJ66HLZbKRg63i8EZt968Rd/Cc+vuR1FXymsqT9wnPQUyS8yiJ5ge68NfSYUcyK/mWGUj/j3QLu9CCXMO4/XxryPTtcChX6G2gJbsDViFXmJq0zAYRDb1VEp74UE4+qf0fPxjFLZUUdhQiEJQ4G3bNWFUvV6PVmtekdy+iJUMnrxsAG/8k0ZxZS1fbU3nlhGBZ1XxNxgMaLVampubkZnLeXDgDMjcCo310t+AEaa26KwolUrk8otvI2hxzvsZO1sFIgb7OOBs2wMp7Y2VUo0WEDzsPoIDRxt/TAvtKOQypkZ58eOeY6w6XGTWzjnAJYGXsCxzGbm1uWRVZxHqHAohk8DjFyg9KqW3j3/UZPb9flCKmo8KcTW+6E55JhQcAEFGeMK/Cbf3Mu54Fi6IUSGuknOeVcHto4N6poXReRDuHM7Oop2kV6Wf4pwP9RzKwtELWZ27mh2FO9hevIerQiZK9aSZa03inBfWNFPdqEUhF4w+2ZGY9gct9aU4IuA29hGw64F6XQsAeDpYMyLElZ1ZFSxPKuSBSaGmNumsyAQZKNUw+Br2HVzK57sW8rhrMCHOA0xq19GiWkrrWlAr5e0aGEbBYIAti6XnkVeB71D2Z/0lvXSNxEZ59skVURQpLi6murraeDZaOIV74x2oadKA2MTR9ExsVGd2+0RRxGAwUFdXZxbXMb1BT4u+BXXkfxA09VArg+xss++k4eTkhJeX10X9hhbnvJ+xLUOqNx9thJT2Rm0jq3JWUaOpQS7IkQtyZLnbkYvVyBy9GOcajMW96HkuH+zFz3uPcbigltzyBoJ6QGDpQrFX2XPH4Dvws/eTHHOQTsQj74XlD0LqCoi+ziQ1oeX1Le0RiplDe6AHclsaf8hESb3eglkyLMgFpVygqKaZ/MpGAl3N6/gKcw5rd85Px0CXgfjY+bC7aDe5tbkUDpqCT9pKyNoEo/8Lih7SJWnlSGvUfKCnPSqFEaM3mkZ27v8EEBnpEoXQplZvoce4KtaHnVkVbEgtZfaoQOytzV/sUoycwfLDn1KlbWThlgU8Ovp5otyiTObMtPWLHxPqhpXi4iN2Z6ToINQcB5UdjLgXgP0l+wGI94o/58fbHHMPDw9sbGzMwvnrL9Q0aahq0CII4G5vdUYHXRRFdDodCoXC5P8fURQprC9EJapwt3ZF3VAmtfq09QArO5PadiZEUaSxsZHSUqnMxNv7wtvsWpzzfkR5fQupxVLPa2OktH9z9Bs2HNvQ8YZBD5XZIDeASs+gpnK87IzfE9pCZ9zsrBgZ4sqOrApWHi7i/onmHaGYFHAapWTvWAgaC7nbYPenMPWVHrfrr6RC9AaRKF+H9lYlRqO+DLIk1fpE/zjqjm8l0jUSV3UPlaJY6DJqlZwhAc7syalke2aF2TnnbXXnGVUZiKKIIAjsKdqDv70/3q3nY3uVPeN8x2GtsEbhFQO27tBQBvk7IWRCj9p7uLXe3Nj9zVu2v8cBXRXIlIwc/ZhRx7Jwegb7OBDsZktOeQNrjpRwbXwPTHpeJIKtK08EX8MbWb9ztL6Yl3a/hL3SniDHIAIdAhnhPaL9mDM2Rwtr2Z5ZjiDA9Fgj31ulrZb+DpgEKltqNbWkVUpCkwmeCWf9qF6vb3fMXV0t17CexsrKCuQt1DZpqWoBWxvlaSdyzMk5B3DEkZqWGjRyHc4O7tBYBvpasHI12+i5Wi1lVJaWluLh4XHBKe5mUlRwbl5++WVGjx6NjY0NTk5OpjanV7KjNaU9wtseVzurbt/+LRG3EOMWw2WBl3FN6DVcpXDlCp2CqTYBXBp6jcWxMCFXxkgX7k2pZTRqdCa2put0ErEa8W8QZJC3HQoTe9SOhhYdq5IlxfsZQ3rgBvLI79LklncM/9Sk8kHiB+wt3mv8cS1cECeqtpsbQY5BxLnHcVnQZegMOkobS/kw8UMe2/IYuTW57evdF3cfd0TdgYedV0fP84w1PW7v0Val9sHG7G+eu42DmctpQcTDLYIQ92jjjWXhjAiC0H5t2pBaithL2iXZxN3KUzobxjW3INPrqNPWkVyezN/Zf5NTk9MjNhgMIp9vzQbg0ghPQtyNGE3UNELOFun5wGkAJJYmYsBAoEMgbuqzZ2K21Zjb2JivrkBfRhAE3O2tUKvkGAwiRdXN6M2wu8jJ2CmlfbpB14DB2hEEOeg1oDE/8dUTadvPL0Zbodc45xqNhlmzZnHfffeZ2pRey47WFmpjQo2j0m6nsuPpkU9zV/Rd3OR/KbcUZnO7Xs0do5/l7pi78bHzMcq4Fs5NtK8j/i5qmrR6NqSWmtqcc2IQDSw9vJR7195LcUNrGzinAIiYLj3f/g7oeq53++rDxTRp9QS42JAQ6GzcwTSNkCLV8hFzAzm10s2eRandfBke4oJMgNzyBrLNTLVdKVPy5IgnuX7g9ShkCj5P/pxmfTOhTqEEOASc/kNtznn+Lql1VA9RWtdMSW0LMgEivIwUOa8vg82vs1OmBbULI0MuN4soUX9lbKgbSrlAfmUjOeUNpjanazgFoAwcyzydDV87DWPR2EX8O+bfXB50OYNcBgFSFDKzKpOalhqjmLA5vYyM0nrUSjm3jQo0yhjtZG+Suhk4+YOH1M5zX/E+4NxR8xOxHGemQyYIeDlao5TL0OoN1JlZe7XTYSW3QilTIooiDfomUDtJCxorzbrveXfs573GOV+4cCEPP/ww0dGWGe4LobJBw9Ei6SarO+vND5Ye5J/cf05dkPidNMPlFQV+XT95WzAOgiC0t1VblVxs9hEKmSCjtLGUZn0zf2b+2bEgfg6onaEyB3a83yO2aHQGlidJitYzhvgikxn5BiNtJbTUgaMf1Z6RVDVXISAQ6GDkGzALF4yDtZKRraVCb6/LQKMzz5YvWwu2klSWhFKm5J6YeySRqxMwiAaOVhxlr6YCXEPBoIPsjT1mX1sLtQHudqhVRqifbamDVY/R0lzNAZUCbN0Y5T2q+8ex0GVsrRQMC5KEzNo0PXoFsTcCoMxYT4jSgckBk7kz6s728/SSQ0t4evvTbMjfcLatXBDNWj1f7sgF4Pph/jjZGFkXIr01pT18ans68fQB07lqwFWM9B5p3LEtdBsKmay9/Wt9i/lnUAqCgJ1Kip7Xa+rB2hmQga4JtKe2Bu1L9Oma85aWFlpaOqJrtbXShd9gMGAw4355BoOhXTWxu9ieUYZBFBnoaY+rrbJbtn2s7hjv7H+HZl0zNgobxviMkRY0lCEclSJ/4tA50gyXmTuD5k537BMTwtz4cnsueZUNHDpeTbQx00a7gWsGXMPBkoNsPr6ZmaEzpbIIayeY+BTC6sch5S9E7zgYMNmodmxKK6GioQVXWxXjwly7/dxhEA2szFnJ1KCpKAQZQvIvfClvYouylqb194MIPnY+qGSqTmMb4zxh4cL597hgDhfUkFNezzc7c7ljTFCP23C2feJ43XE+PPghADNCZ+Bl43XKenuK9/D2/rdxU7sxdMAUZBWZkL4GcdD0HrH/cEENIiKRPvbdv1/rWhBWPwWVOSjVrrw4+SmSGgsJtA/s88eQuZ8rxoe5sT2rnM3pZcweGWD8CdDuwGMwgmcUlByGXUsQJz3VaXGEcwSb8jexPn8900OmnzIRdjH8tv8YFQ0teNpb86/oU4/jrtDlfaK2EKEoCQQBMfTS9l7TAxwHMMBxQPu2ujJW28OC6bC1klNeD01aPTq9AflJx1rb/8dc/k92Sjuqmqto1DWiE0Bu7QDN1dBUKXVPMEPa9vPT+ZpdPVb7tHO+aNEiFi5ceMr7ZWVlNDc3m8CirmEwGKipqUEUxW7rNbj+8HF0Wh1R7sp2JcGLoVZTyxuH36CupY4whzCCZcHt27U9+CnWmka0boOpVfhBN4zX3+mufWKYr5qNmdX8ujsLz7HmLb7jhBPBNsGk16bz46EfmRU8S1qgCkAdMh2btN8QNyyiWnDDYGccNXODKPLTrhx0Wh0Tglyoqijv5u0b+DHnR7aVbGOw1WCcSw5hX3WMFmsFNYICtBoEBGIcYk45bo1xnrBwcdwa58q7W47z6748gu1FIr16VhzuTPtEraaWJ/Y/AYCrlSsj7Uae9jrgI/ogF+UU1RWxx8uFeJ0eoeAgVdnJGOw8jW7/gexSdFodvmpDt1yn2hEN2O96A1XhfkSFDTXDF2At92eEvT9lZb0oWnuBmPu5IsDGgEowUFLdwLYjuQzyNC9RxTMhD78Jp4IFkLqSGq+x6FwHtS8LUYSgFJUU1hayJWMLkU6R3TJmRYOWH3fnotOLXBPpSHXlhV2TurpPqI/+ho1Oi8YjjroGERrO/7jUarUYDAZ0Oh06nflHbNu46667qK6u5rfffuvRcb/++mseeeSRc56b9Ho9b775Jl9//TX5+fmo1WpCQ0O56667uPPOO0/7GQFQyQVadAZqGltwsO5wA0VRRK/XS+uZSQmCgIBKpkJr0NLY0ohaaY+8qRpa6tC3NIK8Z7uJdAWdTofBYKCiogKlsnMHirq6ui5tw6TO+RNPPMFrr7121nVSUlIYNGjQWdc5E08++STz589vf11bW4u/vz/u7u44OBhXCfZiMBgMkoCDu3u3XEirGzVkV2eiUCqYOiQYDwfri9qeVq/lg90fUKuvxc/Rj6dGP4W9qlW9ur4E4fhmUCiRj7kPa0/j39D1B7prn5g1ypateYkcKm5GbuNoFGHA7uRG4UYW7VnEnqo93Bp3K45WrdH+iQ8iNORAcTLuSR8gXvWBUU7Se3IqKWnUY29jxaxRYdhadd8p0yAa+DT5U3ZX7EalVCHaiTjvWwMKJddGzOTKqJnYKGywUdpgJT/1/9Td5wkLF8/lHh5k1sI/R4r56kAF793o16Ptoc60T3jgQVhuGMfrjvPYyMfwdjqzsvNIv5FsL9hOqljEyMDhULAft6r9EDLHqLZXN2ooazKgVCoZHRnQfb+bKMK2txBKD4CVDeK0N3D1ju2ebfcSesO5YuKgetaklHCoTM/46F7Sb97DA0qvQkhbiWvqt4jXLJFES1uZFDyJNblrOFh/kInhE7tlyG/XpiPK5MT6OnBF/IALdqK6tE+IBoTiHdL9XOwM1B4eiKLI96nfE+kaSbRbNArZua+Jzc3N1NXVoVAoUCh6T0xQJpMhk8l63Oa2/8e5xv2///s/Pv30U95//30SEhKora1l3759VFVVnfWz9moRTX0LTToRl9Osd7JDaWo8bT1RCCcoyFvZg6YOhabWLNvMKhQKZDIZrq6uWFt39rdOfn0mTHqWfuSRR0hJSTnrIyQk5IK3b2VlhYODQ6cHdBxw5vwQBKHbtrU7pwpRhHAPe7ydbC56e0uPLCWjOgMbpQ0Lhi/A0dqxY3nidwgGHYJPHDK/oSb/HfvSozv2iRB3e6J8HDGIsDalzOTf6VyPWI9YBjgNQGPQsDpvdccyhRJhyvMI1g4I5RnI9nxqlPH/TCpEQKrXt1erum27CPBp8qdsPr4ZmSBj3pB5hLY0I5QeRZArcY+7DX8Hf1xtXFEr1UbdJyyP7n3MHReCr5OaygYNn2zJ6fH/0ZnGe27Uc7w7+V3CXcLP+vmxvmNBgF3FuxAHTkUAZGkrkSEa1e7U4noEBILcbHG0seq+bR/8Glnq3wiCgDD5WVY0H+eDxA84UnHE5PuKOewX5vKYNMgTAYEd2RXoDL3jPk0mkyEbPhdBZSddh9JWdlp2aeClIEj9wOu0dRc9VkZpA5vTy5EJAnPHhyCXy427T5QkI9QVI6hskYWMRyaTkVefx985f/PewffOa58SBKH9AdCiM5jkAXSy5WyPNtpeT5o0if/+978sWLAAV1dXvL29WbhwYafPyGQylixZwhVXXIGNjQ0DBgzgt99+a1++efNmZDIZNTU17e8lJSVJv21eHps3b+bOO++kpqam/bc7eYy2x19//cX999/P9ddfT0hICHFxcdx999089thj7euIosirr75KSEgINjY2xMXFsWbFH4CkXaA3iKxatYqBAwdiY2PDZZddxpdfftnJxoULFzJkyJBOY7/77rsEBwd3eu9///sfkZGRqNVqIiIi+Pjjj9uX5eXlIZPJWLZsGZMnT8bW1pa4uDh27drVaRs7duxg0qRJ2Nra4uLiwtSpU2mobUAmk3V8l7gx2ATEETdqEr/98lOX/589/TjTsdAVTDqF5e7ujru7uylN6Bdsz+o+lfbcmlw2Hd+EDBnz4+fja+fbsbC2SBKzAoi/46LHsmAcroj25khhLauPFHN9gh8KuXlGUkC6KM4Im8HifYvZmL+R68KvQylrndW1c4eJT8HqJ+Dwb+AzBILHddvYqcW1HC6oRS4TmB7bfZ0G9AY9HyV9xLaCbciQ8Z8h/2G072hY86y0QuilYOPSbeNZ6FmslXIeuWwgj/2SxNaMcoYFuTBpkOkjgbZKW2yV504XjnaPxk5pR3VLNSkOHgy2duzoeR401mj2HW5rodad/c2P/gn7v5Sej32YVCdPvt+xBAMGot0s4rLmxGAfB1ztVFTUa9iXV9mtwrVGxcYFEu6QBEr3fgYhE8Fa2ocDHAIIcwojozqDTcc2cXXo1Rc8jCiKfNbaOm3yIA9CPey7wfhzcGJvc4WUvbW/ZD8Ase6xKOUXFmFt0RmYtWRnt5h4vvxy7yislRcuNvnVV18xf/58du/ezc6dO5kzZw5jxozh0ksvbV/n2Wef5dVXX+Xdd9/lm2++4cYbbyQ5OZmIiIhzbn/06NG88847PPfcc6SlSX3k7exO3ybPy8uLDRs2cP/995/Rl1q0aBHffvstS5YsISwsjC1btjBn9my++eVP4oaPJi07h5kzZ/LAAw8wd+5cdu/ezYIFC877d/nuu+947rnn+OCDDxgyZAgHDx5k7ty52Nracvvtt7ev9/TTT7N48WLCwsJ4+umnuemmm8jMzEShUJCYmMiUKVO48847effdd1EoFGzcuLE91f6VV17hu+++Y8mSTwjztGXL1q3cOnsO7p7eTJgw4bxtNmfM9678JPLz80lMTCQ/Px+9Xk9iYiKJiYnU15tX2xpzo7y+heTj0k3P6NCL7zOeVpWGgMAI7xFEn9wb9sDXUm9m33jwibvosSwYh1EDXHGyUVLVoGHN0RJTm3NO4j3juSXiFl4f/3qHY95G4CiIuUF6vvk1aYKom/hxzzEAJg50x62b0v/1Bj0fJH7AtoJtyAU5D8U/JDnmtYWQu01aKWZWt4xlwXSEe9pz03CpTdnHm7MoqTVfjZOTUcqUjPAeAcD2kj0w8AppwdHlRhtTFEWSCyTB1iifbhKqzNkC296RnsffTm3oJN498C4GDIz1HctE/4ndM46FbkEmExgfJjkYm3uTajtA5DXgHCS1Hdy3tNOiKQFTAEgsS7yoIbZklJNWXIe1UsZtI3ugc4emEXI2S8/Dp7W/3dZCLd4z3vg2mCExMTE8//zzhIWFMXv2bBISEli/fn2ndWbNmsXdd99NeHg4L774IgkJCbz/fte6y6hUKhwdHREEAS8vL7y8vM7onL/11luUlZXh5eVFTEwM9957L6tWrWpf3tLSwiuvvMLSpUu5/PLLCQkJYc6cOdx666389M0XACz5eAkDBgzgzTffZODAgdx8882dnOmu8vzzz/Pmm28yc+ZMgoODmTlzJg8//DCffPJJp/UeffRRrrzySsLDw1m4cCF5eXlkZmYC8Prrr5OQkMBHH31EbGwsgwcPZt68ebi5uVHXWMcri17hlfdf4bLLLiMkIo45N87g1uum88mSJedtr7nTa4o/nnvuOb766qv210OGDAFg48aNTJw40URWmT9rjpRgEKVZaW/Hi1c2vDzocuI949EZThL1qMrraLcx7K6LHseC8VDKZdw4LIAlm7P4bnceE8Ldu7WWuruRCTKuGnDVmVcYPheKD0FpCqz/P7jqfZBf3PfZn1fJ/rwqZDKBWQn+F7Wtk9GLehSCgofiH2KY1zDpzeRfQDSA/3BwufBSHgvmw6wEf/bnVZFaXMfba9N5ZUY0vUKFGhjtM5r1+evJrslGjJ6HkPQDHN8jTSI5dF8WSRsb00rJLW9AJhOI8u2GyHl9KWx4WTqmIqZjGHo7H+17g8rmSrxtvbk7+m6zETyy0MHEge4sO1jA3txKGlp0Zn1d6oRcAWMehL/nS9kaEdPBVVIyH+UzCkcrR+I84i548y06PV9uzwFgVrx/z2jF5GyR2lU5+oHnYADKm8rJrc1Fhuyivo+VQsYv95qmhaGV4uJikjExMZ1ee3t7nyJeOWrUqFNeJyYmXtS4pyMyMpLDhw+zf/9+tm/fzpYtW5g+fTpz5szh888/JzMzk8bGxk5RfQCNRkNcnORDpaWmMmz48LPafy4aGhrIysrirrvuYu7cue3v63Q6HB07T7ae+Pt5e0vaJ6WlpQwaNIjExERmzTp9cCI3O5emxiZuveZWBNrO3SIajZYhsX0vC6qXnPngyy+/5MsvvzS1Gb0KvUHknyPFAEyLPrMA0Pnipj5Nutm+pdKNUOCY9hO5BfNlapQXK5ILOVbZxM/7jnHHmGBTm9Rl6jR1HQKEAHIlTHkefrsbSo/Cnk9g1AMXvH2d3sDnW6Uboekx3vg6dV+7DrlMzoNDHiS7Jptw53DpzdoiSG0tB2nLArDQ65HLBB65bCAP/nCQI4W1/HbgeLdP9BiLSNdIXhzzImFOYZIT6zcMju+FlL9hxD3dOlZxTTNLNknpurcMD+iens07PwBdM3hFw9j5/J3zNwdLD6KUKXlo6EOoFebZgqe/E+xmS4CLDfmVjezIquDSyF4kKOsbDyETIHszbH8Xpr8LgoC1wpqhnkMvatM7Misor9fgZqfi6iHdPzl2WtJbI7An9DZvS2kPdwnvEGe9AARBuKjUclNysliaIAjn1cqureb4xFZlWq32gu2RyWQMGzaMYcOG8dBDD/Htt99y22238fTTT7dnFq9YsQJfX99On7OyskJUyhEBnf7sbdPa6r1P5ESb28b57LPPGDFiRKf15PLO/+cTf7+2CdK230+tPvN5ubGhURrjp88I9g/G3cYdWuqgvhQrtY3kf3Rju0JT03e+iYVT2J1TQWWDBke1klEhF5/SXtlcefoFZemQvUk6gVui5r0CuUxod8iXJxX2irTbyuZKXtr1Eo9teQyt/qSLmYM3TGytkzr0s3SDdIGsPFzM8aomHNQKbmxNTe5OFDJFh2MuirDlDcmR8I6RbvAs9Bm8HK25Z7yUCfHj3mNUN2pMbFHXkAkywp3DO6LLka2ZK2kr4eRj7yLQG0TeXJNGk1bPYB8HrovvhvaOx/dLx78gg7EPk1adwQ8pPwAwZ/AcghyDLn4MC0ZBEAQmhEup7ZvSemEL1pH3S7XZRUmQteGUxTqDDo3+/M8BG1t/i8sHe2Gl6AGntrYIChOle7qwy9rf3lu8F+i/Ke1dZdeuXae8bqs3b6sNLyrqKME7OaquUqna66zPl8hIqWVfQ0MDkZGRWFlZkZ+fT2hoaKeHv78/dlYKBoQNZN/ePWe1393dneLi4k4O+ok2e3p64uPjQ3Z29injBAd3PfATExNzSonAid/LysqKwmOFeAZ4EhQSRGhkrPRdvN2huWstynoLFue8D7MqWYqaXxrpieoiU3myq7O5f939vLXvrVNm0Nj7ufR3wJT2VC4L5k9CoDOx/o7o9CJf7sg1tTnnxF5lT0F9AVXNVfyc/jO5NbmdnfTg8R2R502vQvWx8x6jtlnLD7vzAbhtZCB23ZRWWdxQzKeHPm2/uWkn9W8o2C+1gRv/eHuEwkLfYUqEB2Gedmh0BpYdLDC1OeeN1qBF5zccbN2gqQpyt3bbtn/ae4zU4jrUKjnzLw2/+LR/vRa2vy09j5oJrgOwU9nha+/LaJ/R7fW/FsyXCQMl5yW5oIby+hYTW3Oe2HtB3M3S810fS2nhrazLW8cD6x/gn9x/zmuTlQ0ako5VAzBxYA8JS2a02ugzFOyl7AWDaGhv6ZngmdAzdvRSfvnlF5YuXUp6ejrPP/88e/bsYd68eQDtjvELL7xARkYGK1as4M033+z0+aCgIOrr61m/fj3l5eU0NjaedpzrrruOt99+m927d5OXl8emTZt44IEHCA8PZ9CgQdjb2/Poo4/y8MMP89VXX5GVlcWBAwd4//33+eqrr7CzUnDT7DvJzs7ikUcfJS0tjR9++KFTCTHAxIkTKSsr4/XXXycrK4sPP/ywU207wMKFC1m0aBHvvfce6enpJCcn88UXX/DWW291+Xd78skn2bt3L/fffz+HDh0iNTWVjz/+mPLy8vbv8srTr/DbD7+RlJrEgYOJvP/lL3z14x/QVCEFO/oIFufc3BBFKD2KdeaKi9pMQXUTiceqEQQphfliWZe/DhERhUzRuVavKAmO7ZaiFAkWhfbehCAI3DU2BEGAbRnlpBTVmtqks6KUKZkeMh2A5VnLWbB1AbNXzeahjQ/xcdLH0krD7wGvaJq0DYhrngXt+WUEfL87n/oWHUFutlwW2X39MxPLElmfv57VOas73qwvhZ0ftdo9F5x6R8qzhfNDEARubs3AWJlcRE1T90Wejc3PaT9z79p7+TXrD8RuFoZLKarlp73SRNj9Ewfg4dC1/q9nJflXaVJO7dzeMcTXzpdXxr7CPTH3WOrMewGeDtZEeNsjirA1o5cJwwHE3gT23lKHg3+egl1LIPEHhMKDVNcWsD7jD8T68i5vbmtGGQYRBnnZ4+XYDcfIuTAYOlTaw6e2vy0TZDyS8AgLhi3Ax66HUut7KQsXLuTHH38kJiaGr7/+mh9++KE9oq1UKvnhhx9ITU0lJiaG1157jZdeeqnT50ePHs29997LDTfcgLu7O6+//vppx7n88sv566+/mD59OuHh4dx+++0MGjSINWvWtPc5f/HFF3n22WdZtGgRERERTJ06lRUrVhAcHIxKISM4OIgPPv+GP/74k7i4OD777DNefvnlTuNERETw0Ucf8eGHHxIbG8uePXt49NFHO61z99138/nnn/PFF18QHR3NhAkT+PLLL88rch4eHs6aNWtISkpi+PDhjBo1ij///LPTd3niqSdY8vYSRsWNkr7Lmo0EBwaAXgOaviMQLoinhEH7LrW1tTg6OlJTU9Pe89zsqClA/PFmtDo9itm/IbO/sJqrpdtyWHawgPhAZ1646uJqwBu1jdy37j6a9c08P+p5Il2lkwyiCMv/A8XJkgDK+EfPviELF4zBYKC0tBQPD48u90nsKu+vz2DN0RLCPO1YfF2sWYtWafVafkr7iYzqDI7XHadeK52MBzoP5P/G/J+0UkM58369kgaDBg87XzyDJ+Fp60WkayRDPIaccdv5FY3854cDGER4eUYUMX5O3Wb363tfZ3/Jfm4edLPUTkcUYdUCaWLLM0oSsTvP/6sx9wkL3YsoijzycxIZpfVcF+/H7aODjDJOd+8TyzKW8WPajwBEOQzg36nb8BAFuP5rcL5wxehGjY4HfzhISW0LEwe688hlAy/aVurL4OfbpGjlpKeoCRx5UXWxfYnedq5YmVzEx5uyCHG35d0bz3zONltytnS0xmylCZF7VXU0I/K8zo7IYQ9A3E3n3NRDPx4kq6yB+yYO4Ipu1A464z5RmAh//ReUNnDb77TIZKhkqoua2GpubiYnJ4fg4GCsrXtggsGECILAsmXLuOaaa0xtSpeobNBQUd+CjUqBj5M1Op2Obdu2MXnyZKqqqnBycjK1iZ0wiAbya/PRi3q8bb2xUdpI5/6mClDZSQKGJuZs+3tX/VDzP0v3Nxx9wTsWAQOkXlj0XKMzsC5FapE1rRui5tsKttGsb8bXzpcIlxP6NB7bIznmchUMPf/WCxbMg1tHBmKtlJFRUs/WzK7P6JsCpVzJrZG3snD0Qj6/7HOWXLKEZ0Y8w6zwDoVPndqJCgcvGoHc+uPszlnL8qzlvLrnVb5P+f7Usgw6esgaRKnVXHc65lqDliPlRwCIcW9VKk1fLTnmchVMePy8HXMLvQtBELhhmJQZseJQEbXNvSN6fnXo1cyOnI1KpuJwbRaP2QmslrVguMjo+SebsympbcHD3op7J3RTKdSuDyXH3CsKbcgkHtzwIMsylmEQuy7WZME8GBPqhkwmkF3WwLHK06f0mjXB4+HyV6SMqOhZEHYZav8RjLH2BpmCdbIW2L1EcuLPQn5FI1llUheDMaE91Pf96J/S3wGT0MmVvL7ndT5M/PBUnRcLfYK20r0mrQ69wfxjtTJBhqvaFW9b7w5hT7Uz2HkZpZOIqbDcEZoh4qB/ASCkrZBSjM6T7Znl1DXrcLNTMSzI5eJsEUXW5a8DpH6d7bOnBgPs/Ux6PngG2Llf1DgWTIezrYpZ8ZLj8NWOXFp0FyZE0tMIgoCztTPR7tFEu3e00lDIFHx51c8sjribx7Q23F5bzwTnKAD+zPqTPzL/OGVbe3IqSTxWjUIucGc3K9dnVGXQrG/GQeVAoEMgNJTDzg+lhQl3XFQE0kLvYXiwCyHutjRp9fzZS2rPZYKMK0Ou5I0JbxDhEkGztT1fKJr5v4zvKa7Ju6Btbs0oY0NqKTIB5l8W3j3tso7vh6yNUnnVmIfJqMmkWd/MqpxVJ7TdsdBbcFQriQ9wBnqpMBxA0BgYciuMngeTn4Yr3mDKtPfBdQB7bB2owwAbX4GKrDNuYnO69N0TAp1xVCvPuF63UZkN2Rul55HX8M3RbzhccZi9xXspaSwx/vgWehyVQoaVQo4oQoNGd+4PmAH2KntslDYd/ohcAWoni1q7BSMTPB6Dyl66iT+269zrn8TKZEkFcmqU10WnKGdWZ5JXm4dSpmSC34SOBblboDxDSn1qE0Cx0Gu5eogPbnYqyupaWJ5YaGpzLhoruRX+w+8jIWAiV+jk3J93hHsjZuNr58vkgMmd1tXqDSxt7SF7daxPt9f1HSo7BEC0WzQyBNj6ltQCxH2QpXVaP0IQBG4cJtWe/5VURF0viZ4DeNl68dyo57gj7gGs5VakiE2UZ6057+0U1zTz4cZMAK5L8GewTzekneu1sONd6fnga8AtlLTKNAAiXCMsdea9lImtwnCb08tOm+3UGwlxDCHIIQitrRurXL2kTI9/noLGUzvhGAwim9Kkmvu238Lo7PtCKrkKHs+GpuOszpVqzx+IewA/e9OnC/cGRFHsNSntbdhZSxOk9c1SYGbixImIomh2Ke2no6+cG07G4pybI3IVLYGTpOcpf5/XR7PL6kktrkMmE7pF0GrTsU0AjPIZhZ3KTnrToIe9/5Oex1wvzVhZ6NVYKeTMHhUEwC/7jvealk9nRSaDiU9I4jx1RUxK38JrY17qVIeq1Wv5+1AhhdXNONkouWFY97dOSy5PBiDWPRYy10HedpAppNZvst7Z69XChTEi2IUgt9boeS+bBJMJMqaGTOONQXO4Q2dNVH5ilz9bUN3EBxsyuO+7/TS06AnztOOmYd0kgHj4N6jKk1IbE+4EIKUyBaBzGZaFXsXwYBeslTJKaltIbFUr7+0IgsBVA64CAVbbqql38Ia6Ylj3/CktCo8W1VJa14JaKWd48MVlQHaJsnQpzV4QSAubyP+SpXu8WeGzGO493PjjWzAZvS21HUBv0FPRVMHx+uN9snTJ4pybKc3Bl0pP8ndKqs5dZNVhqX3aqBBXnG1VF23HrZG3ck/0PVwRfEXHmxlroDofrOwl59xCn2BCuDthHnY0afV819pOrNdj7QCXvSjVdufvQrny8fYoxcb8jTy88VG+3iM5z7NHBaFWda+zrDVoadJJ7XSi7fxhe2uEb+hscAnp1rEsmD8ymdDulC5PKqS+pXekEZ6IR9QNTMUGSg5DeeZZ180sree11anc/+1+/jlSgk4vEuntwIKpg1DIu+H2o74M9re2/Rnxb7CyxyAa2iPng1wGXfwYFkyCtVLOJRGSIO4X23Mx9BKn4VyM9hnNrPBZvDTuVeymvgoqWyg6BNve6dQKanO6FDUfE+rWM73N9y0FoDxoDG9m/IRO1DHCawQzw2Yaf2wLJuXE1PZGbe8oa5QJMuq19Wj0Ghq1vVCX4hxYnHMzxWAvCcMhdl0YrkmjZ3NrGtQV0d3TBkqtUDMlcArBjq11uDoN7P9Sej7kVunCYqFPIJMJ3DlW+j+vOVJMcc35tSEzW9zC4LKXpH21OBn+uA9tWSq/Z/5OekU+xxVfYu+Sjo9HBeVN5d06C6uUKXlr4lt8PG4xLlta09ldQyHulm4bw0LvYmSIKwGuNjRp9L2zhMTGBYLG0YDIir1v8+mhT09Z5XBBDc/9eZiHf0pkW0Y5BhESgpx59dpoXrsuBs/uaJsGcOBL0DZKHQ/CLgcgtzaXZn0zaoWaAIfuz4Sx0HPcODwAG5WcnPIG1qf20trzkxAEgevCr5PakTkHwZTnpVrZ1L+lLBAkUd9tGZI4a4+ktJccgfydiILA24pGajQ1BNoHcl/cfcj6UB2vhTNjZy1NADVoekcUWhAE7JX2ANRqzLsN8IVgOerMGDHiKulJ6goplfwcbEorpUmrx9dJTbTvxdXyiaJ4+lqO1L+lNCxbN0kIzkKfIsrXkaEBThhE+GnvMVOb030EjIBrPpLabNQVo/zrIZ7zvpzmJmcMQj3VViv4v10LeWD9A9y68laWZ3VPL2cAmqpxWfd/0sSAyg4mPSUJmFjol8hkAje2R88LaOiF0XMir0KHyLclO1l/9EfK8ne2R/0O5lfx1LJkDuZXIxMk5+K9m4bw/PTB3VNj3oa2CTI3SM+Hz23veJBakQpI7RUtjkXvxlGt5Mbh0rHy9c5cmjS9I6p3PhyxtWN1+Djpxc4P4fg+9udVUd+iw9VOddH3cl2itUxRCJ/GTTF34Wvny6PDHu1Qw7bQ57GzkgQHm7V6dL0kS8Xeyh4BgSZdExp9HyjFPAHLlcucCRoL1o7QUAb5ZxeGE0WRla0p7dOivdpFcAyigV/Sf+G7lO9o0bd0eei0qjQWbFnAxvyNHW9qm+DA19LzobNBYXV+38dCr+CmEVK0aUNqSd+JnoMUpbjmY/CNB20T6rWLuKrcA1dxBMN9YvG08UQhKNCLemwUNu0f0+q1F5Q2JYoi2toi+OtBKE+XtBmmvwOu3dQ6ykKvZcwANwJcbGho0fP3oV4YPfcZiqN3HAP1MmiqZN8/D8MPN2HYtYTl6zcjGkRGBLvwyW0JPHLZQILdjJBhlbNFipo7+klZZq2oFWoCHQIZ7Da4+8e00ONcGS2JdFY3avn1wHFTm9Ot5NXm8dLOl/iqPoMjQcOlTMk1z1K+/UsUopYJ4e5dE/XVXsR1ujARCvZLOihDZxPlFsXiCYvxsPG48G1a6HWoFDLUSim1vbapd4iVKmVK1EppAqmvRc8tzrk5I1fBwGnS89SzC8OlFteRW96ASiFj8qCOk6qAQE1LDcuzlvPstmcpbig+57CF9YUsPbyUvLo80qrSOhYc/h2aqqReggOvOPMGLPRqBnk5EB/o3Pei5yDVoF/xBkTNpKZJy9VNa1msqOaFYY/z3uT3+OaKb/hoykeM8hkFQJOuidf2vsare149r8ktgKKSRO7+4xreqktBtHGD6e9JKfYW+j0ymcD1rdHzPw4W0thLWti0IwhwxZskDL4RrBzYqxChroi6XV9z8/EXebZxEfNDi7q980En0lZKf8OnSva0MilgEq+Pf53pIdONN7aFHkOlkHHH6CAAlh04Tlnd+Z2HzZlAh0DG+Y3DgIH3hGpqvAaj1zQQkf89z9S9yBWK/WfOmmypgyPL4Le74YupUvT7fJWrRRFh/1KSBR0FA8aDgzeAJeOkn+JoI0XPa5u1vUYF3UHlAEC9pr5PCcNZjkBzp7XnOfm7zioMt+KQ1D5tfJg79tYd/TAFQeDyIKkWL68ujye3Psm+4n2n3YYoiqzOXc2CLQvIq83DTmknKYsCNNdC0g/S8/g7QN4DPTctmIy2VMINqSUU1TSZ2JpuRianYPA9fCm/DoMgI6JxH/z1X2ioQCbIcFW7YquUIn0VTRVk12STVpXGO/vfQWfoohNVmcOhNY/TrG+hQWWDcM2Hln7mFjoxLtQNXyc19S06ViWfe9LU7FCoSIi+FRy8SXELomzMY2zVRaITFIRbV2Oz9RWp3eZFUtZYxsKdC1mTe0LrttoiKeInCBB++Wk/Z2mh1ncYNcCVKF8HtHqRr3fmmtqcbuXOqDvxs/OjWlPL+x7eHAy5lyrBGXdZHZ6J78Mvt0P2ZsnxFkVpv9/wMnwzUxKRK8+Q3j/wNWxadIrq+9lQliZxvCSRxcomnm5KJ7cm11hf00IvwFalQC4T0OnFXlNuZaOwQSGTMh6bdX0n09PinJs7Tv7gM+SswnBldS1szZCE4K6M8aJR28jPaT+3OxL+9v58NOUjwp3DadQ18sa+N/gx9cdOs0wVTRW8svsVvjj8BRqDhmi3aF4f/7okWgJw6CdpptY5CEIvMepXtmB6Toye/7y3b6USAqxKLmKX1Wg2hz2F0sYRylJh2b9PUZ/2s/djwbAFqGQqDpQeYEnSknPPzpamwl8PkqStAoUVMUPvAfvuEWi00HeQyQRmDvUFYM3R4l4TqTgRL1svAuwDMAjwXmETn1jN4eOAt3AYOAEMOli/UCqHukAMooEPEz/kaMVRfkj9AW2b45Eu9V/GNx7sOjLFalpqOtax0GcQBIG7xgYjCLAprYz0kjpTm9RtWCuseSj+IazkViRXHObNymJetn+S4si7pLLG6mOw9jnp+vTTrdJEcsYa0GvAJRhG/wfG/FcSlUv/B1Y/AZqGcw8sihgOf8NiRSPNakeCnMPwtfc1/hfuJQiCcNbHCy+8YFLb/vjjj3Out3nzZiZPnoyLiws2NjaEhYVx++23o9Gcvj5bEMDeShKGq+klqe2CIOCudsff3h8bpc25P9BLsDjnvYGI1vS8MwjDLU8qxCBCtJ8jnk7w0q6X+C3jN5YeXtq+jqvaledGPcfUoKkALMtcxitbn6F+1ePUH/6dBVsWcKj8EEqZkjui7uCpEU/hqnaVPtxYCcm/Ss+H3d0uvGOhb3PT8I7a88LqvhM9b9bqWZdSAkD8yAlwzRJwCpC0HZbPg9ztndYf6DKQh+MfRoaMrQVb+eboN50dKYNB6hF76Bf452n4679om2s4amUFjv7E+I3uya9noRcxLswda6WMwupmjhb1zpq5YV7D0OpFNuXtBOC28RHIJj0hiYZWH4OdH1zwtv/O/ru9Z3mjrpEDpQek4y39H2mF8Gmd1v8+5Xvm/DOHtXlrL3hMC+ZJqIc9kwZKEzGfb83ulZNZZ8Lf3p+7o+9GpxdJb1xPqfo3giffATf9APG3g1INZWlQc1x6Puhfkn7KdV9A9HUQNROmviotO74Plj8IDeVnHVOft42PG1MoloG7SxgPxz+MUmbJiGyjqKio/fHOO+/g4ODQ6b1HH330vLZ3JofYWBw9epSpU6eSkJDAli1bSE5O5v3330elUqHXn1lY0d5KAQI0avRodL1DgNFGaYNKfvGto80Ji5fVGwgad0ZhuIYWHf+0CsFdFmXHwp0LyarJwl5pzyUBnSPcbY73f4b8ByuZiqZju7DK34Xd9neZIHNggOMAXhv/GlODpnauOTr4LeiawX2QJFJnoV8w0Mu+I3q+r+/Unm/NKKehRY+ngxVD/J3B0VdScm8VimPN05KjfcLN31DPodwXdx8AK7NX8sfBjyHxB1i1AL76F/w+V3JCcreBrpkMzzCaHX1wsHYm0MGSzm7h9KhVcsaGSq2S1h3tna2iErwSqKrXI4oyYvwcSAh0lq5Xk56SQjEpf0tpuRdAvaYekJwXgK3Ht0JxEtQVSa0RT7oepVSmoDPocFf3QPspCz3ObaMCsVLISCmqY3tmhanN6VbG+40nXH0pgmhFkEMo7vZWoLKlKe4mng6J5scBwygceQ/c+jtMeAw8IztpLRAwAqa/C2pnqMiEP+6HypxTB9Jp0Jam8O2uVzks16OycePREU/haNUDqvBtiKJ0rTXFo4uTOl5eXu0PR0dHBEFof93Q0MAtt9yCp6cndnZ2DBs2jHXr1nX6fFBQEC+++CKzZ8/GwcGBe+65B4DPPvsMf39/bGxsmDFjBm+99RZOTk6dPvvnn38ydOhQrK2tCQkJYeHCheh0uvbtAsyYMQNBENpfn8yaNWvw8vLi9ddfJyoqigEDBjB16lQ+++wz1OoOFf5t27Yxbtw41Go1AQEBPPbofAStpOtQ06SjtLSU6dOno1arCQ4O5rvvviMoKIh33nkHgNzcXARBIDExsX2b1dXVCILApk2b2t87fPgw06ZNw87ODk9PT2677TbKyzsmkCZOnMiDDz7I448/jouLC15eXqdkJ1RXV/Pvf/8bT09PrK2tiYqK4u+/O/S4Tvwu/v7+PPjggzQ0dCGLxAyx9PPpDShUkgBb0g+Q8hcEjWlftDK5kDpdOS7OdSw79gvFjcU4Wznz9Min229oTmas71gCcnZicywXpdwK9FpuzN6HMGwuCruT0prqiiGlta3U8Hs6Xwws9HluHhHA/rwqNqaWcn2CPz5Ovbu1iiiKrGhVx54W5d2hhGtlD9Neh+3vSMfYzg+gOg/GPCS1PastYnxdDXV6G76uOsTy8nQma+xwbJvfVNmCVzR4x4F3LIcqkyDrD6Ldoi3iOhbOyiWRHqxLKWFbZhn3jA9BrZKb2qTzorHeBZvKB1AIKuaOG9BR6+0bD7E3Q+J3sOUN8IjolILeFW6OuJnRPqORC3Ie3fIoB0sPUldbjz3AgMmg7BCcq2quoqSxBAGBcOfw7vuCFswGNzsrZg7144c9+Xy5I4fhwS6oFH3j/GowiFSVDMWrcSA3Dwtof/9w+WEy6/PJBJYfL2Sa0sC1YdeePoXXfaAUUV/1mJS1svw/MOLfiI1VCFU5UJmNWJ3HfxS1VAkGEGTcP/xxghyDeux7AlKwZ+nUnh2zjTtXSxkGF0F9fT1XXHEFL7/8MlZWVnz99ddMnz6dtLQ0AgI6/neLFy/mueee4/nnnwdg+/bt3Hvvvbz22mtcddVVrFu3jmeffbbTtrdu3crs2bN57733GDduHFlZWe2O/fPPP8/evXvx8PDgiy++YOrUqcjlp79eeHl5UVRUxJYtWxg/fvxp18nKymLq1Km89NJLLF26lNLSUubNm0fNk4/w3BsfUNusZd7tcygqKmTjxo0olUoefPBBSkvPbyK5urqayZMnc/fdd/P222/T1NTEggULuP7669mwYUP7el999RXz589n9+7d7Ny5kzlz5jBmzBguvfRSDAYD06ZNo66ujm+//ZYBAwZw9OjR9u9/8ncpKytj3rx5zJs3jy+++OK87DUHLM55L0EbfhnFh77l+PGtOOZvIzJgLFq9gWXJKZTaLAEra3SNCjzUHjwz8hk8bT3PvLGCAwQcXQHIYPIzUJWLct8XsPdzQJTapLWx/ytJYMRnCPgONfbXtGBmhHtK0fP9eVX8tPcYD1/au296M0rrySprQCkXuCTypGNEroBxj0gp7rs+kpz08nSpfq9Gqru/EtDJlMQq7HEMHCYdF96x4BraqdzjUPq3AMS6x2LBwtmI9HbAx8mawupmtmWWc+nJ+6UZYzCILN2WiwwVl0Z6EnRyy7SEO6U2TWWpsOEl+Nc7XSqLEkWx3clvcxyuGnAVEQ7BqFe/IK0U3vnmvi39PcAhoE/VHlrozMyhvvxzpJiS2hb+Sirk2ng/U5vULWxOL6Ogugk7KyWTBnZ8p4EuA7k/9n62F24nqSyJv7P/ZnvBdm6JuIWxvmNPFT508IarP6R01SPsKT9M0o6FVAoii7W2CAgIwACZNRlKBZf5XsmIgMk9+0X7ALGxscTGdlzbX3zxRZYtW8by5cuZN29e+/uTJ0/mkUceaX/99NNPM23atPaU+PDwcHbs2NEp+rtw4UKeeOIJbr/9dgBCQkJ48cUXefzxx3n++edxd5eygpycnPDyOrOWzaxZs/jnn3+YMGECXl5ejBw5kilTprRH8gEWLVrELbfcwkMPPQRAaGgob7/9NlOmTOGZV94iJz+P1atXsWfPHoYNGwbA//73PyIiIs7r9/rggw8YMmQIr7zySvt7S5cuxd/fn/T0dMLDpfvKmJiY9omMsLAwPvjgA9avX8+ll17KunXr2LNnDykpKe3rh4SEtG/v5O8SFhbGe++9x4QJE/j444+xtjZi5xAjYHHOzRCtXsvust3UV9ZT2FBIQX0BJQ0lGGwMoG1k9LYXifQaR361gfFldVS5NhFl5UCIbSDXD5+Pq+1ZohPNNbDxFSm1Z9C/IGSi9L4gl5zzvf+T6trj50DNsQ7hnWF3W6Lm/ZS26PmmtFJuGNa7o+dtXQ3GhrnjqD5NfZ0gQMz14OALG16U6vxAEtvxjATfBK72GyZFAWWtM7bVWQSgR9kaRRdFkZE+I7FSWBHtHt0j38tC70UQBC6J8OTrnXmsO1rSq5zzzellZJTWo1bKuXVkIGWNZbiqXTuyReQKmPIs/DYXipKkKPrQ2866zSMVR/g57Wfui70PL9uOm89bIm6B1JWga5GEUj079zFPrUwFIMLl/G4cLfQurJVyZo8K5J11Gfyy/xhXxnhjrexd2SYno9Ub+G53HgDXDvXD1qrj1txB5cAE/wlM8J/AgZIDfHnkS0oaS/gg8QPW56/nyRFPYiW3AqCgvoA9RXvYXbybHEUt2KulVG65itLoW/H0jAWXEB5Q2WAlt6asrMwk3xeFtRTBNtXYF0l9fT0vvPACK1asoKioCJ1OR1NTE/n5+Z3WS0hI6PQ6LS2NGTNmdHpv+PDhnZzzpKQktm/fzssvv9z+nl6vp7m5mcbGRmxsujbxKJfL+eKLL3jppZfYsGEDu3fv5pVXXuG1115jz549eHt7k5SUxKFDh/juu+/aPyeKIgaDgaqS42RlpKNQKBg6tCMwN2jQoFPS8M9FUlISGzduxM7O7pRlWVlZnZzzE/H29m6P0icmJuLn59e+7unGONN3ycnJOe8JBVNjcc7NEEEQ+DbrW2RyGZzgD6ttPfGtysensRoxYy3Kykam6AxcV6vETVcIRYVQ/bx0M+Tgc+qGRVFKL2woA0c/GN0xw8fQ20CmgN1LYP+XktJuzXFJJT5wDHhFGf17WzBP+kr0vLZZ29HVINr77CsHjYGrP4SsDZLWgs8QsDr1wpJTk8PCnQsJcQzhkYRHsFfZIwgCVw24qqMNoQUL52DyIA++3ZXH0aJaCqqb8O0FE2DNWj1ftba1ui7Bjw8OvU5yeTILRy9kkMugjhUd/WDsQ9Kk8L6l0rF0hutJo7aRjxI/orypnBXZK7gr+q7OK6Svkv6GTztlsrjNOR/oMrA7vp4FM2bSQA9+2JNPSW0L2zLKT82C6mW0ZQI426qYHnuae7dWhnoOJdotmr+z/+b3jN9xUDm0O+Y/pv7Issxl7evKBDmDAieS4JlAtFs07vZ+0iQzYAMYDCbsCS0IF51abkoeffRR1q5dy+LFiwkNDUWtVnPdddedIvpma2t7hi2cmfr6ehYuXMjMmTNPWXYh0V9fX19uu+02brvtNl588UXCw8NZsmQJCxcupL6+nn//+988+OCDgOTM6nQ6FAoFvv7+JB6WspFadAZszpA+L5N1BCXa0Go7K73X19czffp0XnvttVM+7+3dcS+mVHYOmAiC0L6fnlgnfzpO/i4ncmKpQW/B4pybIQqZggS3BFzsXfB38MfXzhdfe1+cVU4IhQegvoScojJW7MvATqXhphhXEJsllc7So/DrXVJ6bthJLc9S/oKcrZITPuX5U0+OcTdJy3Z+IInAtTHspBskC/2OW/pA9Hzd0RK0epEB7raEe57qaJ+C6wDpcRbqNfUICKRUpvDMtmd4YvgTeNudw/G3YOEkXO2sGBIgTYCtTylh9qggU5t0Tv44WEBFvQYPeyuuifPl02QnAPYW7+3snAOEXQbH9kDmOim9PexSKQKuawJts1SDqmvhC10x5TThYefFzRE3d95GzXGKiw6yQa7DVa3ixO7mDdoG8mulqJUlct73kckELh/sxdc781h1uLhXO+dNGj0/7ZUEV28c5n/OLAClXMmMsBmM8xvXmqQuMchlEApBQZRbFMO9hpPgldCzIm/9iO3btzNnzpz2KHh9fT25ubnn/NzAgQPZu3dvp/dOfj106FDS0tIIDQ0943aUSuVZFdfPhLOzM97e3u0iaUOHDuXo0aPtY53onAuCQNTgSHQ6HVt27GbqJEl8My0tjerq6vZttqXZFxUVMWTIEIBO4nBt4/z2228EBQWhUFyY2xkTE8Px48c7pcGfPMaJ36W30zeUNPogt4fezl3RdzE1eCrR7tG4WLsgyGTglwCDruR/NfH8Yz0N7bD7sJryBFzyAlz7P0mUStsopeRufAU0jdIGq3I7WtoMvwfczxD9jJkFY06YeQqdck4HxULfJ8zTnoQgSbm9LVrWmzAYRFYmS10NrozxObVO7wKJdo/mpTEv4a52p7ixmGe2P8PSw0upaanplu1b6D9c1upgrE8pRW8w7zZRLTo9vx8sAOD20UGoFDKGeUk1iXuL957a5koQYOzDYO8tKa0f+BoO/QRHl0s9m3O2sLtgG1sqDiGrzmNe8NWoFSdNAKavJl2m50+1nJWF204Z45aIW7gk4BKcrZ2N9r0tmA+XRnoilwmkl9SRVVZvanMumL+SCqlu1OLlaN1+DugKbmq3jna3QJRbFJ9e9ilPjniSKYFTLI65EQkLC+P3338nMTGRpKQkbr755i5lIvznP/9h5cqVvPXWW2RkZPDJJ5+watWqTvcjzz33HF9//TULFy7kyJEjpKSk8OOPP/LMM8+0rxMUFMT69espLi6mqqrqtGN98skn3HfffaxZs4asrCyOHDnCggULOHLkCNOnS+2ZFyxYwI4dO5g3bx6JiYlkZGR0qpuPjxnMuEmX8Mh/57Fj507279/P3Xff3SmKrVarGTlyJK+++iopKSls3ry5k60ADzzwAJWVldx0003s3buXrKws/vnnH+64444uTzJMmDCB8ePHc+2117J27VpycnJYtWoVq1evPuN3+fPPPztpAPQmLM55LyS7rJ6kYzXIBLgq7oQUKHtPqZVG/BwpfSn9H6nFU3EyrH9RilT4JUD0rLMPEHUtTHpaqkcfcZ8xv4qFXsTto4KQCbAjs4JDx6tNbc55cfBYFSW1zdhayRkX5tat2/Z38OflsS8T5hRGvbaef3L/4Z6196DVa8/9YQsWWhkW7IKDWkFlg4aD+ae/4TIX9uZU0aTR425vxdhQ6XiKcY9BKVNS0ljC8brjp37Iyg6mvgIR02HwNRB7k3StGnEvB2Nn8JGLK8iUXK0RGLjhdUhf0/HZ1t7mwwxKrNSuFDcWk1Gd0b7YVmnL9AHTmRsz17hf3ILZ4GSjYvQAyTld3dpOtrdR26zl1wPSsXLryEAU8gu/JVfIFNgqzz+N2sL589Zbb+Hs7Mzo0aOZPn06l19+eae67DMxZswYlixZwltvvUVsbCyrV6/m4Ycf7pSufvnll/P333+zZs0ahg0bxsiRI3n77bcJDOxoyfrmm2+ydu1a/P3926PVJzN8+HDq6+u59957GTx4MBMmTGDXrl388ccfTJgwAZCi0Zs3byY9PZ1x48YxdOhQFi5ciI+P5FdYK2W89cEneHh6MXnSJGbOnMk999yDh0dnXaulS5ei0+mIj4/noYce4qWXXuq03MfHh+3bt6PX67nsssuIjo7moYcewsnJqT0tviv89ttvDBs2jJtuuonIyEgef/zxduf+5O8yZMgQnnvuufbv0tsQxFOmuM2P3NxcXnzxRTZs2EBxcTE+Pj7ceuutPP3006hUXW88X1tbi6OjIzU1Ne1qheaIwWCgtLQUDw+P0+64b61JY2NaGePC3Hh86qDTbAFJfGfDS1B/QssDa0e47guwdT39ZyyYLefaJ3qKjzdlsTK5iEBXG969cQhyWe8QCVz41xH25VZxdZwPd48LOfcHLgCNXsPHSR+zo3AHQz2GsmD4AqOM04a57BMWuo/PtmSzPKmQ0aGuPDnt/NOze2qfeOnvo+zOqeS6eD9uHx3U/v5re17jQOkBbhh4AzPDTq2ZPB37S/azeO9iDBiIdgpnQU0jyuP7pIWRV8OoedIE84r5oLLjg5jL2Fq0g8uDLufOqDuN8O36Hn31XHG4oIYnf0/GWinjqzuHY6PqXZWaS7flsOxgAcFutrxzQ1xHa88eoCf3iebmZnJycggODu51qtnGZu7cuaSmprJ161ZTm3JKWjtATZOG0toWlHIZga427b3VH3rooXZldAudOdv+3lU/tFecpVNTUzEYDHzyySccOXKEt99+myVLlvDUU0+Z2rQep6yuhc0Z5YDUUuSMeMdKae7BJ/Q3nPiExTG3cFHcMjIAOysFeRWNrDpcZGpzusTG1FL25VYhCDDtXEJwF4FKruLBIQ/y3KjnuD/ufqONY6HvMiVCikjszq6kpsk8My/qmrXsy5Mi+xMHundadmJqe1eJdI3E38GfSf6TWDD6OZTT3oB4qY0QR/+UejUf+kl6HTqZsf5S1GdHwQ60Bi1avZYtx7dQ2lh6ajq9hT7NYB8H/JzVNGsNbEozkfL4BVJe38LfhwoBuH10YI865hZMx+LFi0lKSiIzM5P333+fr776qr1tmjlib6VEJhPQ6g00as6/zt3ChdErphmnTp3K1KkdPU1DQkJIS0vj448/ZvHixSa0rOdZnlSIwSAS7edIqIf92Ve2doBL/w/ytgMCBI7uERst9F0crJXcOjKQJZuz+G5XPuPD3XGwPk1LMjMhu6ye9zdI6a83DPM3ugq2IAgMdh187hUtWDgNIe52hHrYkVlaz6a0Uq6OO8sErInYnlmB3iAS6GpDoGvnNNp4z3gEBLJrsilvKsdNffoSkhZ9CyqZCkEQUCvUvDDqBdQKdUftZcKd4BEpZX+VpXZ8cOAVRLuF42TlRHVLNUmlSdgqbfkw8UMcVY58cuknxvraFswQQRCYGuXF51tzWJlcxLQor27TEzE2P+zOR6sXGezjwNAAi05Cf2HPnj28/vrr1NXVERISwnvvvcfdd99tarPOiEwm4GCtoLpRS2ldC74XUXphoev0Cuf8dNTU1ODi4nLWdVpaWmhpaWl/XVtbC0jpPCZtI3EODAZDe3++E2lo0bH6cBEiItfE+XT9OwSMbttwN1tqoac40z5hCi6L9GBVchG5lQ18uzOXeyeYp2BgXbOWl1ekoNEbiA9w5oZ4P7P4/boLc9onLHQfUwa5k1Fax9qjJfwr+vycjZ7YJzallSIiMiHc7ZRx7JX2zAydia+dL7YKW/R6/Sn2lzWW8fq+1xnrO5arB1wNgLXcGlEUO0e+/YbDjE8Q1r0A5engHIToGo6AwGjv0azMWcmW41sIdAgEUWqhdso2LAB9+1wxMdyNr3fkklvRwNHCGiK8zbdksY2CqibWppQgInLbyACT7Lc9uU+0jWU5PuGnn3465T1z+k3abDnRJmcbFY0aPRqdgYKqRtIys1DJZWZltznRtp+fztfs6vHWK53ztnSQc0XNFy1axMKFC095v6ysjObmZmOZd9EYDAZqamoQRbFTLdCvSaXUNbbg62iFn7WG0tLSs2zFQl/iTPuEqbguypFX19fwd+JxEryUBDibVx2ZQRR5e/MxCiobcLNTMjvOmfLy3pX2eC7MbZ+w0D1EOIFg0JNZXMPetGMEuXT92DL2PlHRoCUxrwKASGfhtNeg8U5SKVVNRQ0bizby17G/sFPYYae0w05hR15DHnXaOqoaqohTx52qyt4JOYx8Fqu8jejcItGXScdwpDqSdaxDpVORWJCIVqfFR+5juSaegb5+rhjqo2Zrdg2/7cnmnlHmLwD16bbjaDRa4nztcJU3U1ra8/ejPblPaLVaDAYDOp0OnU5n1LEsXDiiKLYLrJ08qeppp6S4ToNGZ+B4ZSNeDipUlij6adHpdBgMBioqKk7p3V5XV9elbZjUOX/iiSdO25T+RFJSUhg0qEP0rKCggKlTpzJr1izmzj27MuuTTz7J/Pnz21/X1tbi7++Pu7u72QvCCYKAu7t7+0mzsLqJ9ZlZKJQK5k4Mx8vz7FkDFvoWp9snTImHB+woaGFHVgXLjtby0jX+ZpVO+P3ufFLKWrCxVvHCNTEEu/U9FVtz2ycsdB9jw2vZmlnOwVIdwwd5nPsDrRh7n9h2oACFUkGUjyMRwedOuReqBfSCnhp9DTX6jvaCoS6hPJbwWKdWUGfF+7ZOL91Fdz4P/By5IOfuNXejVCgZETQCD8eu/1b9ib5+rrh2hJqdxw6RWNSEtYOzWZdaHS6o4WBRE0qlknsmD8LD1TTXpp7cJ5qbm6mrq0OhUFxwn2sLPcfJDiVIzqKfs4LC6iZadAZK6rT4OqlRKfre+eRiUSgUyGQyXF1dTxGE66ogokmPkkceeYQ5c+acdZ2QkA5l5cLCQiZNmsTo0aP59NNPz7l9KysrrKysTnlfJpOZ/QVKEIROdn6xIw+dQWRogDMjQlzNyhGy0DOcvE+YmrvHhrAvt4rDhbXszK5ibDe3KLtQ9uRU8tO+4wgI/Gdy2Lm1GXox5rZPWOgeLhvsxbbMCrakl3PbqCDsrLp+qTbmPrEloxwBgYkDu3ZDf3Xo1Uzwm0CtppY6TR21mloEBEb6jDxHxPzcyJGTU5NDk74JtVJNkFMQMsFyHJyJvnyuGOjlQKi7HVllDWxMK2PGED9Tm3QKTRo93+/JZ3liAQICkwa6E+Ju2mtTT+0TMpkMQRDaHxbME1EU2/8/p/s/KeQCvs5qCqqbadHqKahuwtdJjZVS3tOmmjVt+/npjq2uHmsmdc7d3d1xd3c/94pIEfNJkyYRHx/PF1980ScvMGdif14le3IqkckE5o4LsZzcLJgFHg7WXBfvzw978lm6PYeEIGesTXySLqxu4s01aQBcGePNpPOIOlqwYC7E+jnh6WBFSW0LC347xAvTB+Nuf+pEc0+SX9FITnkDcpnAmNCuTcSpFWrUdmq8MU6XhJSKFAA8bDwsjnk/RhKG8+bDjZmsPlzM1bG+Rlc/r2nU8t6GDHLKGxgX5saUQZ4EuNqcdt2dWRV8siWLinoNAKNDXZk73jgtPS1YMCZymQxfJ2sKq5tpbnXQfZzUJr/362v0iqtZQUEBEydOJCAggMWLF1NWVkZxcTHFxcWmNs3oaPUGPtuSA8D0GG/8XU5/8rdgwRTMHOqLm52KsroWfj9QYFJbmrV6Xl6ZQqNGzyAve+4aG2xSeyxYuFBkMoGnrojA2VZFfkUjj/6SRHZZvUlt2pQu1XPHBzpjbyZpw5uObQIgxi3GpHZYMD0Twt1RK+UUVjdzqKDmtOvo9AaatRffDupoYS3//ekge3Iq2699D3x/gPk/JbLiUBF1zVIbxNLaZl78+yivrEyhol6Dp4MVz0+P5MlpEWZzDFmwcL7IZbJ2h1xvECmobkKjM12bNVEU0Rv6ljhdryj+WLt2LZmZmWRmZuLn1zldqa+rBa44VERBdRNONkpuGh5ganMsWOiEtURusLEAACf7SURBVFLOnWODeX11Gr/uP4YgwIwhvj06i9qs1bPmaAl/HCygrK4FJxslT0wbhNIiVmKhFxPibsfiWTEsXH6U/MpGnvgtmQXTBhEf2PNtlwwGkc2tfaRP7m1uSh5JeIQtBVuYHjLd1KZYMDFqlZzJER6sOFTEqsNFxPk7AVDbrGV/bhV7cyvZn1eF3iDy2OUDGRHSRb2DExBFkT8TC/liRy4Gg4ifs5qZQ/3YnV3B3rwqMkrrySit5/Nt2cT5O5F8vIYWnQGZTODaob5cn+BviTBa6BPIZQI+TmoKq5to1uopqmnG39nG6Bkrp6NBo6e0thlXWxWONqoeH98Y9Iq71zlz5nRqw9BfWjJUNWr4fnc+ALNHBWF7HnWHFiz0FGND3Rg1wBWtXuT73fnc881+1hwpxnCWmUxRFMkqq2djWilVDZoLGremScv3u/O588u9fLYlu90xf+qKCFztTJsCbMFCd+Bhb81r18UQ7edIk1bP//11hDVHej5jLLW4jtK6FtRKOcODzUeM1NPWk1nhs7BWmFe3CAumYepgLwB2ZVfy0958nvjtELd9vpu31qazNaOcRo2eFp2BV1amsO5oyXltu75Fx6JVqfxvWw4Gg8j4cDfeuj6OSyM9eeZfkXx1xzDuHhdMkJstOr3IvtwqWnQGBvs48P6NQ5g9KsjimFs4I3PmzOGaa65pfz1x4kQeeuihHrdj8+bNyGQyqqurz7muXCbg7WiNQi5DozNQUtfc436ZKIpU1LegN4ho+1D03OLtmTHf7MyjSasnzMOOKZbaWQtmiiAIPDltEFszyvl6Zy4ltS28vyGTP5MKuXNMEEMDnBEEAY3OwKHj1ezOqWRvbmV7/Z1cJjA+3J2rYn0I9bA753gltc38mVjAmiMltOiknpFejtbMHOLL5AgPrBSWGyALfQc7KwULrxrM++sz2JhWxvsbMimta+GWEQE9pj/SltI+coCr5fiyYLYEudkS4W1PSlEd3+7Kb38/0NWGEcEuJAS5sPpwMRtSS3l3fQa1zVpmDj23eFxWWT2LVqZSUtuMQi5p/0yL8up0/DnZqLg6zperYn3ILm9gd3Ylfs5qxoW5WXSCeilz5szhq6++AiQF84CAAGbPns1TTz1ldNX533///bSq6adj06ZNTJo0iaqqKpycnIxqF0BSUhLPPvssu3btora2Fk8vL6Ji43n25TdQh/jh1IPR65omLRqdAblMwLmPRM3B4pybLdkVTaxLLUVAYO74EJOkiliw0FUEQXKwR4a4supwET/uOUZ+RSMvLD9KrL8jaqWcg/nV7c40gJVChqeDNfmVjWxMLWVjaimDfRy4KtaHESGuyGUCoihSWtfC4YIajhTWcqSwhsLqjp6wA9xtuTbejzED3CzHiIU+i1Iu4+FLw/FwsOanvcf4ae8xdmVXEORqi5+zGl9nNX7ONng5dP/NiU5vYFtGOWBeKe0WLJyOW0YE8va6dAJcbBge7MKwIBc8HToyKwZ62uOgVvLHwQK+2J5LTZOWOaODTutAl9Q281dSISuTi9DqRTwdrFgwdRBhnmdWWRcEgQHudgxwP/dEswXzZ+rUqXzxxRe0tLSwcuVKHnjgAZRKJU8++eQp62o0GlSq7jkHu7iYT4bSiZSVlTFlyhT+9a9/8c8//+Dk5ERubi6//LaMxsYGyus1WClkqFXGdy/1BpHK1sxLF1sV8j50D9gr0tr7GwaDyLf7pJSrSQPdifA2357sFiyciEoh4+o4Xz6dHc+MIb4o5AJJx2rYlV1Ji86Aq52KqVFePD89ku/mjuDDW4by5vWxTAh3RyYTOFJYy6JVqdzz9T5eXZXKHV/u5e6v9vHOugzWHi1pd8xj/R158Zoo3r4hjnFh7hbH3EKfRxAEbh0ZyINTwpDJBPIqGtmcXsZ3u/N5fXUaD/5wkOs/2c2Tf2eRUlTbbeMeyK+mrlmHk42SWD+nbtuuBQvGINbfiS/vGM7/XR3Fv2J8OjnmIIkt3jU2mDmjgwD4/UAB763PbBeUEkWRQ8ereenvo8z9eh9/Jhai1YsMC3Lh7RvizuqYWzg/mnXNZ3xo9dour6vRa7q07oVgZWWFl5cXgYGB3HfffVxyySUsX74c6EhFf/nll/Hx8WHgwIEAHDt2jOuvvx4nJydcXFy4+uqryc3Nbd+mXq9n/vz5ODk54erqyuOPP35KOvjJae0tLS0sWLAAf39/rKysCA0N5X//+x+5ublMmjQJAGdnKUuxrUW1wWBg0aJFBAcHo1ariY2N5ddff+00zsqVKwkPD0etVjN58mTy8vLO+nts376dmpoaPv/8c4YMGUJwcDCTJk3iw/ffJXJgKKIoUlzbQmLSIaZNm4adnR2enp7cdtttlJeXt2+noaGB2bNnY2dnh7e3N2+++eYp31kQBP74449O4zs5OfHll18CUunv8WPHePjftxPk43Ha37rtf7R48WK8vb1xdXXlgQceQKvt2L/O9Nu2cfjw4bN+F2NgiZybIRvTy8iuaMLexorbWy8gFiz0Juytldw5NpgrY7xZmVyElULOiBAXQtxsT4lQhHva8+jlA7ljTBArk4tYfaSY0roWSutaAOlmKszDjsE+DkR6OxDp42BRurXQb7k00pMhAU5klNRTUN3E8apGjldJf+tbdBTValm8Jp2PbolHrbr4FPTNrSnt48Pc+1RkwkL/5tp4PxzUSj7YkMG6lBLqW7QMC3Lhr0NF5JY3tK83NMCJ6bE+xAc6W9LTu5nbV99+xmVDPIbwxPAn2l/fs/YeWvQtp103wiWCF0a/0P563oZ51GnqTlnvp3/9dOHGtqJWq6moqGh/vX79ehwcHFi7di0AWq2Wyy+/nFGjRrF161YUCgUvvfQSU6dO5dChQ6hUKt58802+/PJLli5dSkREBG+++SbLli1j8uTJZxx39uzZ7Ny5k/fee4/Y2FhycnIoLy/H39+f3377jWuvvZa0tDQcHBxQq9UALFq0iG+//ZYlS5YQFhbGli1buPXWW3F3d2fChAkcO3aMmTNn8sADD3DPPfewd+9eHn300bN+fy8vL3Q6HcuWLeO6667r1Bfdw96aFl0j5RWVXH7JFObefTdvv/02TU1NLFiwgOuvv54NGzYA8Nhjj7F582b+/PNPPDw8eOqppzhw4ABxcXFd+j9o9QbKahq588YZjB595t8aYOPGjXh7e/9/e/ceF0W5/wH8sxfuC6yCsIuCEOYRFBU0Cam8gGbHEtOsjBQv2UvB8l5ejmnHQi05ZtpBy1J/WacslQzrZYSClxQVkNQQkDBMIUxFQFiB3ef3h4c5LSBiCkPweb9evGJmHme+z+w3dr/7zDyDffv24ezZs3jmmWfQu3dvTJkypcFzCwDFxcUYPHgwXmigL02BxXkLU15Zjf87fPObq6f7duLEVvSX5upgjYnBjXukmZPGCuOCPPH0A+44mPM7Ll+vRDedPbq62nMiHaI/cNZYwbnWe4MQAr+XGjDrs1RcKruBLYfPYeoA77s6TkWlESk/XwEADOAl7dTKDPF1hcZKjbf3nMGRn6/gyH9z3UqtxKBuLhjRy42PryUAN/++JiYmYs+ePXjppZek9XZ2dti4caNUCG7duhUmkwkbN26UCtdNmzZBq9UiKSkJQ4cOxTvvvIMFCxZg1KhRAID169djz549tzx2dnY2tm3bhoSEBISGhgIA7rvvPml7zSXwLi4u0j3nN27cQHR0NL7//nsEBQVJ/+bgwYPYsGEDBgwYgNjYWHh7eyMmJgYA0LVrV2RkZGDVqlW3jOXBBx/EwoUL8dxzz2Hq1Kno168fBg8ejPHjx8PV1RV6R2usefsD+PToidkLl6KD/c33qY8++gju7u7Izs6Gm5sbPvzwQ2zduhUhISEAgC1bttR5GldDLpfdwO64LwEIbP7oQyiVynrPNXDzioJ169ZBpVKhW7duGD58OBITEzFlypTbntt169bB398f0dHR0ro/9qVr166NjvlOsDhvYa7fMMK9nQ2Upmo80dNN7nCImp2VWoUQH1e5wyD6S1EoFHDSWGFiPz1WH7h5n+zD9zuju5vjn9pfeWU1vjj+K25Um6B3tMb9jZiskeivJsjbCa+P6IHobzJhY6nCcD89hnZ35dVZzWDLsC233KZSmH8h//6Q92/ZVqkwv0N33eB1dxfYH8THx0Oj0aCqqgomkwnPPfccli5dKm338/Mzu888IyMDZ8+ehb29+e0PBoMBubm5uHbtGgoKChAYGChtU6vV6Nu37y1nOj9x4gRUKhUGDBjQ6LjPnj2L8vJyDBkyxGx9ZWUl/P39AQCZmZlmcQA3i+/befPNNzF79mzs3bsXKSkpWL9+PaKjo7F//374+fkhL/s0Ug4dgKfOCbUvNsnNzUVFRQUqKyvNjt2+fXvptoDbqTKaUGqoxpmfTuHcz7lwcDC/9bfmXNfo3r07VKr/5ZNer8fJkycB3P7cZmRkYN++fdBo6r7/5ebmsjhvKzrYW2FZWHecPV8ASzWnBCAiosbrrrNDaDcXJJ65hLWJZ/HuWP9Gv5cIIXCmsBTfnf4NB3IuSRM4hvq68pJearX8Ojni48n9oFIqmOfN6E4egdhUbW9n0KBBiI2NhaWlJdzc3OrM0m5nZ2e2XFZWhj59+uCTTz6ps68OHf7c1Uc1l6nfibKyMgDA7t270bFjR7NtVlZ3f0Wuk5MTxowZgzFjxiA6Ohr+/v5YtWoVtmzZAkNFOYY+NhwzFyyBQnHzcWuW/33Kh16vx9mzZxt1DIVCUecLi6qqKpRW3LxfvMpQ0ahzXXvWe4VCAZPp5nvb7c5tWVkZnnjiCaxcubLONr1e36h+/BkszlsghUIBR2u+NEREdOcmBnsiNb8YF4or8PmxfIwL8myw/bWKKiRlFeG7078h/0q5tL5TOxsM66HjVVzU6qlVHAyhuuzs7NClS5dGtw8ICMDnn38OFxeXOiO6NfR6PVJSUvDII48AAKqrq5GamoqAgIB62/v5+cFkMiE5OVm69PqPakbujUajtM7X1xdWVlbIz8+/5aiwj4+PNLldjZSUlNt3sp7je3t74/r1m3M1BAQEYPv27ejifR+qTApYqpVwb2crTdzr7e0NCwsLpKSkwMPDAwBw9epVZGdnm8XaoUMHFBQUSMs5OTkoLy9HlVFAoVAgqF8ffL3zywbP9e3c7tzW9MXT07PJH5/3R/xrRERE1IrYW1sgcuDND5Rfpv6K3Etl9bYzmQS+OnEBkzYfw8YDeci/Ug4rtRIhPi5YObon/h0egLDeHfk0BCKiRggPD4ezszPCwsJw4MAB5OXlISkpCS+//DJ+/fVXAMCMGTOwYsUKxMXF4cyZM4iMjERxcfEt9+np6YmIiAhMmjQJcXFx0j63bdsGAOjcuTMUCgXi4+Nx6dIllJWVwd7eHnPnzsWsWbOwZcsW5ObmIi0tDWvXrpWe3T516lTk5ORg3rx5yMrKwqeffoqPP/64wf7Fx8fj+eefR3x8PLKzs5GVlYVVq1bhm2++QVhYGAAgKioKV65cwdxpk3D6x3ScPXsWn8d9jYkTJ8JoNEKj0WDy5MmYN28e9u7di1OnTmHChAnSfeM1Bg8ejHXr1iE9PR3Hjx/H1KlTpVHwdrYWGD9u3G3P9e3c7tzW9GXs2LE4duwYcnNzsWfPHqkvTYXFORERUSsT5O2E4C7OMAlgzfc5qDaazLYXXjNgUdxJbDyQh8pqE+7rYIeoQd7YMqkfZoZ2ha+bAy/xJSK6A7a2tti/fz88PDwwatQo+Pj4YPLkyTAYDNLo7pw5czBu3DhEREQgKCgI9vb2ePLJJxvcb2xsLJ566ilERkaiW7dumDJlijRS3bFjR7z++uuYP38+XF1dMX36dADAsmXLsHjxYixfvhw+Pj4YNmwYdu/eDS+vm5P0enh4YPv27YiLi0OvXr2wYcMGLFu2rME4fH19YWtrizlz5qB379548MEHsW3bNmzcuBHjxo0DALi5ueHQoUMwmUyY+HQYHh8UhH/MnwcbO3upAH/77bfx8MMP44knnkBoaCgeeugh9OnTx+xYMTExcHd3x8MPP3xzArrpM2BtYwuFEmhna9moc90YDZ3bmr4YjUYMHToUfn5+mDlzJrRabZ0vE+4lhbjVDAStUElJCRwdHXHt2rU/fQlEczCZTCgqKoKLi0uTvvj018GcoNqYE1Rb7ZwoLq/EtK1pKLtRjfFBnTGmrztMJoFvTxVi8w95MFSZYG2hxOSHvPBodx2L8VaKfyuotubMCYPBgLy8PHh5ecHa+t7dD073lhAC1dXVUKvV9/S9oLi8EpdKb0ChUKCj1ho2lvVfHj5w4ED07t0b77zzjtn6mxPAVeFqeRVMJgEXB2s42rTcCRsbyvfG1qG8sZmIiKgV0tpaYsojXlidkIP/HM1HFxcNtqf9iozz1wAAPTo6YGZoV7g68AMzERHde442FjBUGVFqqEZhyQ24t1Pedo4Hk0mg7EY1Sg1VKK8yAv8dRra2UMGhDczJ1fp7SERE1EYN+psLkrMuIS2/GK99dRoAYKlWIqK/Jx730/N+ciIiajIKhQIu9ta4UV2OymoTCksM6Ki1qTM6L3BzlPy3EgPKDNUw/eHCbhtLFRysLaCxurej+i0Vi3MiIqJWSqFQIGpQF0R9mgZDlQnddPaYOaQrOmrv/PE8REREd0qpVEDvaIPzV8pRUWnE72WV0NpaoKLKCEOlERVVRmz8/GsAQMl/H5VmoVLC3kYNB2sLWLSxpymwOCciImrFXByssWJ0TxQUG9Df24mj5URE1Kws1Uq4Olih4JoBxeWVKC6vrLeNjYUK9tZqWFuo2sQoeX1YnBMREbVy3h008O6gkTsMImqj2tD803QLGmsLtKs24er1SigUCliplbC2UMHG4uZ/b3cv+l/BvchzFudERERERHTP1Tybury8HDY2vJ2mrXOys4SDtRpqpbJVXsVVXl4O4H95/2ewOCciIiIiontOpVJBq9WiqKgIwM1ngbfVy5VbsqZ6lNqt1L2o/a9NCIHy8nIUFRVBq9VCpVL96X2xOCciIiIioiah0+kAQCrQqeURQsBkMkGpVPLLk7ug1WqlfP+zWJwTEREREVGTUCgU0Ov1cHFxQVVVldzhUD1MJhMuX74MJycnKJV//Xu/5WBhYXFXI+Y1WJwTEREREVGTUqlU96R4oXvPZDLBwsIC1tbWLM5lxrNPREREREREJDMW50REREREREQyY3FOREREREREJLM2dc95zYPhS0pKZI6kYSaTCaWlpbzvgyTMCaqNOUG1MSeoPswLqo05QbUxJ5peTf1ZU4/eSpsqzktLSwEA7u7uMkdCREREREREbUlpaSkcHR1vuV0hble+tyImkwkXL16Evb19i36GX0lJCdzd3XH+/Hk4ODjIHQ61AMwJqo05QbUxJ6g+zAuqjTlBtTEnmp4QAqWlpXBzc2vw6oQ2NXKuVCrRqVMnucNoNAcHB/4PQmaYE1Qbc4JqY05QfZgXVBtzgmpjTjSthkbMa/CmAiIiIiIiIiKZsTgnIiIiIiIikhmL8xbIysoKS5YsgZWVldyhUAvBnKDamBNUG3OC6sO8oNqYE1Qbc6LlaFMTwhERERERERG1RBw5JyIiIiIiIpIZi3MiIiIiIiIimbE4JyIiIiIiIpIZi3MiIiIiIiIimbE4b4Hee+89eHp6wtraGoGBgTh69KjcIVEzWL58OR544AHY29vDxcUFI0eORFZWllkbg8GAqKgoODk5QaPRYPTo0fjtt99kipia24oVK6BQKDBz5kxpHXOibbpw4QKef/55ODk5wcbGBn5+fjh+/Li0XQiB1157DXq9HjY2NggNDUVOTo6MEVNTMhqNWLx4Mby8vGBjYwNvb28sW7YMf5zzlznRuu3fvx9PPPEE3NzcoFAoEBcXZ7a9Ma//lStXEB4eDgcHB2i1WkyePBllZWXN2Au6lxrKiaqqKrz66qvw8/ODnZ0d3NzcMH78eFy8eNFsH8yJ5sfivIX5/PPPMXv2bCxZsgRpaWno1asXHn30URQVFckdGjWx5ORkREVF4ciRI0hISEBVVRWGDh2K69evS21mzZqFr7/+Gl988QWSk5Nx8eJFjBo1SsaoqbkcO3YMGzZsQM+ePc3WMyfanqtXryI4OBgWFhb49ttv8dNPPyEmJgbt2rWT2rz11lt49913sX79eqSkpMDOzg6PPvooDAaDjJFTU1m5ciViY2Oxbt06ZGZmYuXKlXjrrbewdu1aqQ1zonW7fv06evXqhffee6/e7Y15/cPDw3H69GkkJCQgPj4e+/fvx4svvthcXaB7rKGcKC8vR1paGhYvXoy0tDTs2LEDWVlZGDFihFk75oQMBLUo/fr1E1FRUdKy0WgUbm5uYvny5TJGRXIoKioSAERycrIQQoji4mJhYWEhvvjiC6lNZmamACAOHz4sV5jUDEpLS8X9998vEhISxIABA8SMGTOEEMyJturVV18VDz300C23m0wmodPpxNtvvy2tKy4uFlZWVuI///lPc4RIzWz48OFi0qRJZutGjRolwsPDhRDMibYGgNi5c6e03JjX/6effhIAxLFjx6Q23377rVAoFOLChQvNFjs1jdo5UZ+jR48KAOKXX34RQjAn5MKR8xaksrISqampCA0NldYplUqEhobi8OHDMkZGcrh27RoAoH379gCA1NRUVFVVmeVHt27d4OHhwfxo5aKiojB8+HCz1x5gTrRVu3btQt++fTFmzBi4uLjA398fH3zwgbQ9Ly8PhYWFZnnh6OiIwMBA5kUr1b9/fyQmJiI7OxsAkJGRgYMHD+Kxxx4DwJxo6xrz+h8+fBharRZ9+/aV2oSGhkKpVCIlJaXZY6bmd+3aNSgUCmi1WgDMCbmo5Q6A/uf333+H0WiEq6ur2XpXV1ecOXNGpqhIDiaTCTNnzkRwcDB69OgBACgsLISlpaX0R7OGq6srCgsLZYiSmsNnn32GtLQ0HDt2rM425kTb9PPPPyM2NhazZ8/GwoULcezYMbz88suwtLRERESE9NrX917CvGid5s+fj5KSEnTr1g0qlQpGoxFvvvkmwsPDAYA50cY15vUvLCyEi4uL2Xa1Wo327dszR9oAg8GAV199FWPHjoWDgwMA5oRcWJwTtUBRUVE4deoUDh48KHcoJKPz589jxowZSEhIgLW1tdzhUAthMpnQt29fREdHAwD8/f1x6tQprF+/HhERETJHR3LYtm0bPvnkE3z66afo3r07Tpw4gZkzZ8LNzY05QUQNqqqqwtNPPw0hBGJjY+UOp83jZe0tiLOzM1QqVZ2Zln/77TfodDqZoqLmNn36dMTHx2Pfvn3o1KmTtF6n06GyshLFxcVm7ZkfrVdqaiqKiooQEBAAtVoNtVqN5ORkvPvuu1Cr1XB1dWVOtEF6vR6+vr5m63x8fJCfnw8A0mvP95K2Y968eZg/fz6effZZ+Pn5Ydy4cZg1axaWL18OgDnR1jXm9dfpdHUmH66ursaVK1eYI61YTWH+yy+/ICEhQRo1B5gTcmFx3oJYWlqiT58+SExMlNaZTCYkJiYiKChIxsioOQghMH36dOzcuRN79+6Fl5eX2fY+ffrAwsLCLD+ysrKQn5/P/GilQkJCcPLkSZw4cUL66du3L8LDw6XfmRNtT3BwcJ3HLGZnZ6Nz584AAC8vL+h0OrO8KCkpQUpKCvOilSovL4dSaf6RTqVSwWQyAWBOtHWNef2DgoJQXFyM1NRUqc3evXthMpkQGBjY7DFT06spzHNycvD999/DycnJbDtzQiZyz0hH5j777DNhZWUlNm/eLH766Sfx4osvCq1WKwoLC+UOjZrYtGnThKOjo0hKShIFBQXST3l5udRm6tSpwsPDQ+zdu1ccP35cBAUFiaCgIBmjpub2x9nahWBOtEVHjx4VarVavPnmmyInJ0d88sknwtbWVmzdulVqs2LFCqHVasVXX30lfvzxRxEWFia8vLxERUWFjJFTU4mIiBAdO3YU8fHxIi8vT+zYsUM4OzuLV155RWrDnGjdSktLRXp6ukhPTxcAxL/+9S+Rnp4uzbzdmNd/2LBhwt/fX6SkpIiDBw+K+++/X4wdO1auLtFdaignKisrxYgRI0SnTp3EiRMnzD533rhxQ9oHc6L5sThvgdauXSs8PDyEpaWl6Nevnzhy5IjcIVEzAFDvz6ZNm6Q2FRUVIjIyUrRr107Y2tqKJ598UhQUFMgXNDW72sU5c6Jt+vrrr0WPHj2ElZWV6Natm3j//ffNtptMJrF48WLh6uoqrKysREhIiMjKypIpWmpqJSUlYsaMGcLDw0NYW1uL++67TyxatMjsQzZzonXbt29fvZ8hIiIihBCNe/0vX74sxo4dKzQajXBwcBATJ04UpaWlMvSG7oWGciIvL++Wnzv37dsn7YM50fwUQgjRfOP0RERERERERFQb7zknIiIiIiIikhmLcyIiIiIiIiKZsTgnIiIiIiIikhmLcyIiIiIiIiKZsTgnIiIiIiIikhmLcyIiIiIiIiKZsTgnIiIiIiIikhmLcyIiIiIiIiKZsTgnIiKiv4wJEyZg5MiRDbZJSkqCQqFAcXFxs8RERER0L7A4JyIiugOXLl3CtGnT4OHhASsrK+h0Ojz66KM4dOiQ3KG1GAqFQvpxdHREcHAw9u7de0/2vWbNGmzevFlaHjhwIGbOnGnWpn///igoKICjo+M9OSYREVFzYHFORER0B0aPHo309HRs2bIF2dnZ2LVrFwYOHIjLly/LHVqLsmnTJhQUFODQoUNwdnbG448/jp9//vmu9+vo6AitVttgG0tLS+h0OigUirs+HhERUXNhcU5ERNRIxcXFOHDgAFauXIlBgwahc+fO6NevHxYsWIARI0aYtXvhhRfQoUMHODg4YPDgwcjIyDDb14oVK+Dq6gp7e3tMnjwZ8+fPR+/evaXt9Y0Ijxw5EhMmTJCWb9y4gblz56Jjx46ws7NDYGAgkpKSpO2bN2+GVqvFnj174OPjA41Gg2HDhqGgoMBsvx999BG6d+8OKysr6PV6TJ8+/Y76Uh+tVgudTocePXogNjYWFRUVSEhIAAAkJyejX79+0vHmz5+P6upq6d9++eWX8PPzg42NDZycnBAaGorr168DML+sfcKECUhOTsaaNWukkfpz587Ve1n79u3bpT56enoiJibGLF5PT09ER0dj0qRJsLe3h4eHB95///3b9pOIiOheYXFORETUSBqNBhqNBnFxcbhx48Yt240ZMwZFRUX49ttvkZqaioCAAISEhODKlSsAgG3btmHp0qWIjo7G8ePHodfr8e9///uO45k+fToOHz6Mzz77DD/++CPGjBmDYcOGIScnR2pTXl6OVatW4eOPP8b+/fuRn5+PuXPnSttjY2MRFRWFF198ESdPnsSuXbvQpUuXRvelMWxsbAAAlZWVuHDhAv7+97/jgQceQEZGBmJjY/Hhhx/ijTfeAAAUFBRg7NixmDRpEjIzM5GUlIRRo0ZBCFFnv2vWrEFQUBCmTJmCgoICFBQUwN3dvU671NRUPP3003j22Wdx8uRJLF26FIsXLza7PB4AYmJi0LdvX6SnpyMyMhLTpk1DVlZWo/tJRER0VwQRERE12pdffinatWsnrK2tRf/+/cWCBQtERkaGtP3AgQPCwcFBGAwGs3/n7e0tNmzYIIQQIigoSERGRpptDwwMFL169ZKWBwwYIGbMmGHWJiwsTERERAghhPjll1+ESqUSFy5cMGsTEhIiFixYIIQQYtOmTQKAOHv2rLT9vffeE66urtKym5ubWLRoUb19bUxf6gNA7Ny5UwghxPXr10VkZKRQqVQiIyNDLFy4UPztb38TJpPJLCaNRiOMRqNITU0VAMS5c+fq3XdERIQICwuTlus7T/v27RMAxNWrV4UQQjz33HNiyJAhZm3mzZsnfH19peXOnTuL559/Xlo2mUzCxcVFxMbG3rKfRERE9xJHzomIiO7A6NGjcfHiRezatQvDhg1DUlISAgICpFHYjIwMlJWVwcnJSRpp12g0yMvLQ25uLgAgMzMTgYGBZvsNCgq6ozhOnjwJo9GIrl27mh0nOTlZOg4A2NrawtvbW1rW6/UoKioCABQVFeHixYsICQmp9xiN6cutjB07FhqNBvb29ti+fTs+/PBD9OzZE5mZmQgKCjK7Hzw4OBhlZWX49ddf0atXL4SEhMDPzw9jxozBBx98gKtXr97RuaktMzMTwcHBZuuCg4ORk5MDo9EorevZs6f0u0KhgE6nk84VERFRU1PLHQAREdFfjbW1NYYMGYIhQ4Zg8eLFeOGFF7BkyRJMmDABZWVl0Ov1Zvd+17jdRGZ/pFQq61zKXVVVJf1eVlYGlUqF1NRUqFQqs3YajUb63cLCwmybQqGQ9ltzufmt3E1fVq9ejdDQUDg6OqJDhw4Ntv0jlUqFhIQE/PDDD/juu++wdu1aLFq0CCkpKfDy8mr0fv6M+s6VyWRq0mMSERHV4Mg5ERHRXfL19ZUmLAsICEBhYSHUajW6dOli9uPs7AwA8PHxQUpKitk+jhw5YrbcoUMHs4nbjEYjTp06JS37+/vDaDSiqKioznF0Ol2j4ra3t4enpycSExPr3d6YvtyKTqdDly5d6hTmPj4+OHz4sNkXD4cOHYK9vT06deoE4GZRHBwcjNdffx3p6emwtLTEzp076z2OpaWl2eh3fXx8fOo86u7QoUPo2rVrnS82iIiI5MLinIiIqJEuX76MwYMHY+vWrfjxxx+Rl5eHL774Am+99RbCwsIAAKGhoQgKCsLIkSPx3Xff4dy5c/jhhx+waNEiHD9+HAAwY8YMfPTRR9i0aROys7OxZMkSnD592uxYgwcPxu7du7F7926cOXMG06ZNM5t9vGvXrggPD8f48eOxY8cO5OXl4ejRo1i+fDl2797d6D4tXboUMTExePfdd5GTk4O0tDSsXbu20X25U5GRkTh//jxeeuklnDlzBl999RWWLFmC2bNnQ6lUIiUlRZooLz8/Hzt27MClS5fg4+NT7/48PT2RkpKCc+fO4ffff693pHvOnDlITEzEsmXLkJ2djS1btmDdunVmE+MRERHJjZe1ExERNZJGo0FgYCBWr16N3NxcVFVVwd3dHVOmTMHChQsB3Bz1/eabb7Bo0SJMnDgRly5dgk6nwyOPPAJXV1cAwDPPPIPc3Fy88sorMBgMGD16NKZNm4Y9e/ZIx5o0aRIyMjIwfvx4qNVqzJo1C4MGDTKLZ9OmTXjjjTcwZ84cXLhwAc7OznjwwQfx+OOPN7pPERERMBgMWL16NebOnQtnZ2c89dRTje7LnerYsSO++eYbzJs3D7169UL79u0xefJk/OMf/wAAODg4YP/+/XjnnXdQUlKCzp07IyYmBo899li9+5s7dy4iIiLg6+uLiooK5OXl1WkTEBCAbdu24bXXXsOyZcug1+vxz3/+0+yxdERERHJTiNo3tBEREVGzW7p0KeLi4nDixAm5QyEiIiIZ8LJ2IiIiIiIiIpmxOCciIiIiIiKSGS9rJyIiIiIiIpIZR86JiIiIiIiIZMbinIiIiIiIiEhmLM6JiIiIiIiIZMbinIiIiIiIiEhmLM6JiIiIiIiIZMbinIiIiIiIiEhmLM6JiIiIiIiIZMbinIiIiIiIiEhm/w9tykccQaTlZAAAAABJRU5ErkJggg==\n"
},
"metadata": {}
}
],
"source": [
"x_test, y_test = next(dataset(1, 1))\n",
"y_pred = model(x_test)\n",
"\n",
"plt.figure(figsize=(12, 6))\n",
"plt.subplot(2, 1, 1)\n",
"plt.plot(x_test[0], label='Input Sequence', alpha=0.8)\n",
"plt.plot(y_test[0], label='Target Sequence', alpha=0.8)\n",
"plt.plot(y_pred[0], label='Predicted Sequence', linestyle='--', alpha=0.8)\n",
"plt.xlabel('Sequence Position')\n",
"plt.ylabel('Value')\n",
"plt.title('Example Sequence Prediction')\n",
"plt.legend()\n",
"plt.grid(True, alpha=0.3)"
]
},
{
"cell_type": "markdown",
"id": "aa58e237",
"metadata": {
"id": "aa58e237"
},
"source": [
"## 3. Transformer Scaling with Tensor Parallelism"
]
},
{
"cell_type": "markdown",
"id": "373419be",
"metadata": {
"id": "373419be"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"id": "a36c340b",
"metadata": {
"id": "a36c340b"
},
"source": [
" Image Source: [Megatron-LM](https://arxiv.org/abs/1909.08053) "
]
},
{
"cell_type": "markdown",
"id": "97fa5689",
"metadata": {
"id": "97fa5689"
},
"source": [
"## 4. Scaling Transformers in Flax"
]
},
{
"cell_type": "markdown",
"id": "XxWJxaO6WkGW",
"metadata": {
"id": "XxWJxaO6WkGW"
},
"source": [
"### 4.1 Setup for training a small Transformer Language Model"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "OJNWFSa7WvJl",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "OJNWFSa7WvJl",
"outputId": "7736de6b-3216-45f1-94a0-3c54396e4a29"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"--2025-06-17 01:06:45-- https://huggingface.co/datasets/roneneldan/TinyStories/resolve/main/TinyStories-train.txt?download=true\n",
"Resolving huggingface.co (huggingface.co)... 18.172.134.124, 18.172.134.24, 18.172.134.4, ...\n",
"Connecting to huggingface.co (huggingface.co)|18.172.134.124|:443... connected.\n",
"HTTP request sent, awaiting response... 302 Found\n",
"Location: https://cdn-lfs.hf.co/repos/42/7f/427f7497b6c6596c18b46d5a72e61364fcad12aa433c60a0dbd4d344477b9d81/c5cf5e22ff13614e830afbe61a99fbcbe8bcb7dd72252b989fa1117a368d401f?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27TinyStories-train.txt%3B+filename%3D%22TinyStories-train.txt%22%3B&response-content-type=text%2Fplain&Expires=1750126005&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc1MDEyNjAwNX19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5oZi5jby9yZXBvcy80Mi83Zi80MjdmNzQ5N2I2YzY1OTZjMThiNDZkNWE3MmU2MTM2NGZjYWQxMmFhNDMzYzYwYTBkYmQ0ZDM0NDQ3N2I5ZDgxL2M1Y2Y1ZTIyZmYxMzYxNGU4MzBhZmJlNjFhOTlmYmNiZThiY2I3ZGQ3MjI1MmI5ODlmYTExMTdhMzY4ZDQwMWY%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=N0bHmaWe-%7ETjLo%7EkOX31-6FqrTQ-DLzyfXMhj%7EbqyA6xO2WHPmBAUIIPZgpB77wo-Fx0MG-I4VZ-3G-PUwDvPzDlcUw5tE61MQygGqynyv4C5MMn91pe0LVp230V73Wb7KC-gsrYLaqym%7Ec1lyq72FTu0dLVwf8JD5aHyVi6WrQ9WJas7Id2cZCMAyXymIfsxC6eLebaSkiSzYT6Y11y0pC36A5imVZca-psHhL3AY-anuW53lmGl0wV1ZAWeGoqLd8OzB4Hxs0t9CnEgf0mqWYZhtG989Zc5Rzmfj%7EhE4kDIh%7EQqq-8Pn8%7EaUk%7EYAnpjanaE%7E30FWZlJzaGms1DXQ__&Key-Pair-Id=K3RPWS32NSSJCE [following]\n",
"--2025-06-17 01:06:45-- https://cdn-lfs.hf.co/repos/42/7f/427f7497b6c6596c18b46d5a72e61364fcad12aa433c60a0dbd4d344477b9d81/c5cf5e22ff13614e830afbe61a99fbcbe8bcb7dd72252b989fa1117a368d401f?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27TinyStories-train.txt%3B+filename%3D%22TinyStories-train.txt%22%3B&response-content-type=text%2Fplain&Expires=1750126005&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc1MDEyNjAwNX19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5oZi5jby9yZXBvcy80Mi83Zi80MjdmNzQ5N2I2YzY1OTZjMThiNDZkNWE3MmU2MTM2NGZjYWQxMmFhNDMzYzYwYTBkYmQ0ZDM0NDQ3N2I5ZDgxL2M1Y2Y1ZTIyZmYxMzYxNGU4MzBhZmJlNjFhOTlmYmNiZThiY2I3ZGQ3MjI1MmI5ODlmYTExMTdhMzY4ZDQwMWY%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=N0bHmaWe-%7ETjLo%7EkOX31-6FqrTQ-DLzyfXMhj%7EbqyA6xO2WHPmBAUIIPZgpB77wo-Fx0MG-I4VZ-3G-PUwDvPzDlcUw5tE61MQygGqynyv4C5MMn91pe0LVp230V73Wb7KC-gsrYLaqym%7Ec1lyq72FTu0dLVwf8JD5aHyVi6WrQ9WJas7Id2cZCMAyXymIfsxC6eLebaSkiSzYT6Y11y0pC36A5imVZca-psHhL3AY-anuW53lmGl0wV1ZAWeGoqLd8OzB4Hxs0t9CnEgf0mqWYZhtG989Zc5Rzmfj%7EhE4kDIh%7EQqq-8Pn8%7EaUk%7EYAnpjanaE%7E30FWZlJzaGms1DXQ__&Key-Pair-Id=K3RPWS32NSSJCE\n",
"Resolving cdn-lfs.hf.co (cdn-lfs.hf.co)... 3.167.152.37, 3.167.152.106, 3.167.152.12, ...\n",
"Connecting to cdn-lfs.hf.co (cdn-lfs.hf.co)|3.167.152.37|:443... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 1924281556 (1.8G) [text/plain]\n",
"Saving to: ‘TinyStories-train.txt’\n",
"\n",
"TinyStories-train.t 100%[===================>] 1.79G 311MB/s in 6.0s \n",
"\n",
"2025-06-17 01:06:52 (304 MB/s) - ‘TinyStories-train.txt’ saved [1924281556/1924281556]\n",
"\n"
]
}
],
"source": [
"!wget https://huggingface.co/datasets/roneneldan/TinyStories/resolve/main/TinyStories-train.txt?download=true -O TinyStories-train.txt"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "24340e12",
"metadata": {
"id": "24340e12"
},
"outputs": [],
"source": [
"from dataclasses import dataclass\n",
"import grain.python as pygrain\n",
"import pandas as pd\n",
"import tiktoken\n",
"import time"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "QR2QYRa1W_-u",
"metadata": {
"id": "QR2QYRa1W_-u"
},
"outputs": [],
"source": [
"tokenizer = tiktoken.get_encoding(\"gpt2\")"
]
},
{
"cell_type": "markdown",
"id": "6UywwoVBX47m",
"metadata": {
"id": "6UywwoVBX47m"
},
"source": [
"### 5.2 Define a 2D Mesh"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5UUusIPNX8qs",
"metadata": {
"id": "5UUusIPNX8qs"
},
"outputs": [],
"source": [
"# Create a `Mesh` object representing TPU device arrangement.\n",
"mesh = Mesh(mesh_utils.create_device_mesh((4, 2)), ('batch', 'model'))"
]
},
{
"cell_type": "markdown",
"id": "pDp_YV17XAVI",
"metadata": {
"id": "pDp_YV17XAVI"
},
"source": [
"### 5.3 Define the Sharded Transformer in Flax"
]
},
{
"cell_type": "markdown",
"id": "ZswcXmfvXqVh",
"metadata": {
"id": "ZswcXmfvXqVh"
},
"source": [
"#### 5.3.1 Define Sharded Transformer Block"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "KpmgWSdIXuLO",
"metadata": {
"id": "KpmgWSdIXuLO"
},
"outputs": [],
"source": [
"# Define a triangular mask for causal attention with `jax.numpy.tril` and `jax.numpy.ones`.\n",
"def causal_attention_mask(seq_len):\n",
" return jnp.tril(jnp.ones((seq_len, seq_len)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1uyVHA9bXI9S",
"metadata": {
"id": "1uyVHA9bXI9S"
},
"outputs": [],
"source": [
"class TransformerBlock(nnx.Module):\n",
" \"\"\" A single Transformer block.\n",
"\n",
" Each Transformer block processes input sequences via self-attention and feed-forward networks.\n",
"\n",
" Args:\n",
" embed_dim (int): Embedding dimensionality.\n",
" num_heads (int): Number of attention heads.\n",
" ff_dim (int): Dimensionality of the feed-forward network.\n",
" rngs (flax.nnx.Rngs): A Flax NNX stream of JAX PRNG keys.\n",
" rate (float): Dropout rate. Defaults to 0.1.\n",
" \"\"\"\n",
" def __init__(self, embed_dim: int, num_heads: int, ff_dim: int, *, rngs: nnx.Rngs, rate: float = 0.1):\n",
" # Multi-Head Attention (MHA) with `flax.nnx.MultiHeadAttention`.\n",
" # Specifies tensor sharding (depending on the mesh configuration)\n",
" # where we shard the weights across devices for parallel computation.\n",
" self.mha = nnx.MultiHeadAttention(num_heads=num_heads,\n",
" in_features=embed_dim,\n",
" kernel_init=nnx.with_partitioning(nnx.initializers.xavier_uniform(), NamedSharding(mesh, P(None, 'model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P('model'))),\n",
" rngs=rngs)\n",
" # The first dropout with `flax.nnx.Dropout`.\n",
" self.dropout1 = nnx.Dropout(rate=rate)\n",
" # First layer normalization with `flax.nnx.LayerNorm`.\n",
" self.layer_norm1 = nnx.LayerNorm(epsilon=1e-6,\n",
" num_features=embed_dim,\n",
" scale_init=nnx.with_partitioning(nnx.initializers.ones_init(), NamedSharding(mesh, P('model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P('model'))),\n",
" rngs=rngs)\n",
" # The first linear transformation for the feed-forward network with `flax.nnx.Linear`.\n",
" self.linear1 = nnx.Linear(in_features=embed_dim,\n",
" out_features=ff_dim,\n",
" kernel_init=nnx.with_partitioning(nnx.initializers.xavier_uniform(), NamedSharding(mesh, P(None, 'model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P('model'))),\n",
" rngs=rngs)\n",
" # The second linear transformation for the feed-forward network with `flax.nnx.Linear`.\n",
" self.linear2 = nnx.Linear(in_features=ff_dim,\n",
" out_features=embed_dim,\n",
" kernel_init=nnx.with_partitioning(nnx.initializers.xavier_uniform(), NamedSharding(mesh, P(None, 'model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P('model'))),\n",
" rngs=rngs)\n",
" # The second dropout with `flax.nnx.Dropout`.\n",
" self.dropout2 = nnx.Dropout(rate=rate)\n",
" # Second layer normalization with `flax.nnx.LayerNorm`.\n",
" self.layer_norm2 = nnx.LayerNorm(epsilon=1e-6,\n",
" num_features=embed_dim,\n",
" scale_init=nnx.with_partitioning(nnx.initializers.ones_init(), NamedSharding(mesh, P(None, 'model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P(None, 'model'))),\n",
" rngs=rngs)\n",
"\n",
"\n",
" # Apply the Transformer block to the input sequence.\n",
" def __call__(self, inputs, training: bool = False):\n",
" input_shape = inputs.shape\n",
" _, seq_len, _ = input_shape\n",
"\n",
" # Instantiate the causal attention mask.\n",
" mask = causal_attention_mask(seq_len)\n",
"\n",
" # Apply Multi-Head Attention with the causal attention mask.\n",
" attention_output = self.mha(\n",
" inputs_q=inputs,\n",
" mask=mask,\n",
" decode=False\n",
" )\n",
" # Apply the first dropout.\n",
" attention_output = self.dropout1(attention_output, deterministic=not training)\n",
" # Apply the first layer normalization.\n",
" out1 = self.layer_norm1(inputs + attention_output)\n",
"\n",
" # The feed-forward network.\n",
" # Apply the first linear transformation.\n",
" ffn_output = self.linear1(out1)\n",
" # Apply the ReLU activation with `flax.nnx.relu`.\n",
" ffn_output = nnx.relu(ffn_output)\n",
" # Apply the second linear transformation.\n",
" ffn_output = self.linear2(ffn_output)\n",
" # Apply the second dropout.\n",
" ffn_output = self.dropout2(ffn_output, deterministic=not training)\n",
" # Apply the second layer normalization and return the output of the Transformer block.\n",
" return self.layer_norm2(out1 + ffn_output)\n"
]
},
{
"cell_type": "markdown",
"id": "J-FnRQnLXk4p",
"metadata": {
"id": "J-FnRQnLXk4p"
},
"source": [
"#### 5.3.2 Define Embeddings"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ELCpQVw9XkO7",
"metadata": {
"id": "ELCpQVw9XkO7"
},
"outputs": [],
"source": [
"class TokenAndPositionEmbedding(nnx.Module):\n",
" \"\"\" Combines token embeddings (words in an input sentence) with\n",
" positional embeddings (the position of each word in a sentence).\n",
"\n",
" Args:\n",
" maxlen (int): Matimum sequence length.\n",
" vocal_size (int): Vocabulary size.\n",
" embed_dim (int): Embedding dimensionality.\n",
" rngs (flax.nnx.Rngs): A Flax NNX stream of JAX PRNG keys.\n",
" \"\"\"\n",
" def __init__(self, maxlen: int, vocab_size: int, embed_dim: int, *, rngs: nnx.Rngs):\n",
" # Initialize token embeddings (using `flax.nnx.Embed`).\n",
" # Each unique word has an embedding vector.\n",
" self.token_emb = nnx.Embed(num_embeddings=vocab_size, features=embed_dim, rngs=rngs)\n",
" # Initialize positional embeddings (using `flax.nnx.Embed`).\n",
" self.pos_emb = nnx.Embed(num_embeddings=maxlen, features=embed_dim, rngs=rngs)\n",
"\n",
" # Takes a token sequence (integers) and returns the combined token and positional embeddings.\n",
" def __call__(self, x):\n",
" # Generate a sequence of positions for the input tokens.\n",
" positions = jnp.arange(0, x.shape[1])[None, :]\n",
" # Look up the positional embeddings for each position in the input sequence.\n",
" position_embedding = self.pos_emb(positions)\n",
" # Look up the token embeddings for each token in the input sequence.\n",
" token_embedding = self.token_emb(x)\n",
" # Combine token and positional embeddings.\n",
" return token_embedding + position_embedding\n"
]
},
{
"cell_type": "markdown",
"id": "ZA6K73cDXb1t",
"metadata": {
"id": "ZA6K73cDXb1t"
},
"source": [
"#### 5.3.3 Define the Transformer Module"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "RGT3M7G_XagA",
"metadata": {
"id": "RGT3M7G_XagA"
},
"outputs": [],
"source": [
"class MiniGPT(nnx.Module):\n",
" \"\"\" A miniGPT transformer model, inherits from `flax.nnx.Module`.\n",
"\n",
" Args:\n",
" maxlen (int): Maximum sequence length.\n",
" vocab_size (int): Vocabulary size.\n",
" embed_dim (int): Embedding dimensionality.\n",
" num_heads (int): Number of attention heads.\n",
" feed_forward_dim (int): Dimensionality of the feed-forward network.\n",
" num_transformer_blocks (int): Number of transformer blocks. Each block contains attention and feed-forward networks.\n",
" rngs (nnx.Rngs): A Flax NNX stream of JAX PRNG keys.\n",
" \"\"\"\n",
" # Initialize miniGPT model components.\n",
" def __init__(self, maxlen: int, vocab_size: int, embed_dim: int, num_heads: int, feed_forward_dim: int, num_transformer_blocks: int, rngs: nnx.Rngs):\n",
" # Initiliaze the `TokenAndPositionEmbedding` that combines token and positional embeddings.\n",
" self.embedding_layer = TokenAndPositionEmbedding(\n",
" maxlen, vocab_size, embed_dim, rngs=rngs\n",
" )\n",
" # Create a list of `TransformerBlock` instances.\n",
" # Each block processes input sequences using attention and feed-forward networks.\n",
" self.transformer_blocks = [TransformerBlock(\n",
" embed_dim, num_heads, feed_forward_dim, rngs=rngs\n",
" ) for _ in range(num_transformer_blocks)]\n",
" # Initialize the output `flax.nnx.Linear` layer producing logits over the vocabulary for next-token prediction.\n",
" self.output_layer = nnx.Linear(in_features=embed_dim,\n",
" out_features=vocab_size,\n",
" kernel_init=nnx.with_partitioning(nnx.initializers.xavier_uniform(), NamedSharding(mesh, P(None, 'model'))),\n",
" bias_init=nnx.with_partitioning(nnx.initializers.zeros_init(), NamedSharding(mesh, P(None, 'model'))),\n",
" rngs=rngs)\n",
"\n",
" def __call__(self, inputs, training: bool = False):\n",
" # Pass the input tokens through the `embedding_layer` to get token embeddings.\n",
" # Apply each transformer block sequentially to the embedded input, use the `training` flag for the behavior of `flax.nnx.Dropout`.\n",
" x = self.embedding_layer(inputs)\n",
" for transformer_block in self.transformer_blocks:\n",
" x = transformer_block(x, training=training)\n",
" # Pass the output of the transformer blocks through the output layer,\n",
" # and obtain logits for each token in the vocabulary (for next token prediction).\n",
" outputs = self.output_layer(x)\n",
" return outputs\n",
"\n",
" # Text generation.\n",
" def generate_text(self, max_tokens: int, start_tokens: [int], top_k=10):\n",
" # Sample the next token from a probability distribution based on\n",
" # `logits` and `tok_k` (top-k) sampling strategy.\n",
" def sample_from(logits):\n",
" logits, indices = jax.lax.top_k(logits, k=top_k)\n",
" # Convert logits to probabilities (using `flax.nnx.softmax`).\n",
" logits = nnx.softmax(logits)\n",
" return jax.random.choice(jax.random.PRNGKey(0), indices, p=logits)\n",
"\n",
" # Generate text one token at a time until the maximum token limit is reached (`maxlen`).\n",
" def generate_step(start_tokens):\n",
" pad_len = maxlen - len(start_tokens)\n",
" # Index of the last token in the current sequence.\n",
" sample_index = len(start_tokens) - 1\n",
" # If the input is longer than `maxlen`, then truncate it.\n",
" if pad_len < 0:\n",
" x = jnp.array(start_tokens[:maxlen])\n",
" sample_index = maxlen - 1\n",
" # If the input is shorter than `maxlen`, then pad it (`pad_len`).\n",
" elif pad_len > 0:\n",
" x = jnp.array(start_tokens + [0] * pad_len)\n",
" else:\n",
" x = jnp.array(start_tokens)\n",
"\n",
" # Add a batch dimension.\n",
" x = x[None, :]\n",
" logits = self(x)\n",
" next_token = sample_from(logits[0][sample_index])\n",
" return next_token\n",
"\n",
" # Store generated tokens.\n",
" generated = []\n",
" # Generate tokens until the end-of-text token is encountered or the maximum token limit is reached.\n",
" for _ in range(max_tokens):\n",
" next_token = generate_step(start_tokens + generated)\n",
" # Truncate whatever is after '<|endoftext|>' (stop word)\n",
" if next_token == tokenizer.encode('<|endoftext|>', allowed_special={'<|endoftext|>'})[0]:\n",
" # Stop text generation if the end-of-text token is encountered.\n",
" break\n",
" generated.append(int(next_token))\n",
" # Decode the generated token IDs into text.\n",
" return tokenizer.decode(start_tokens + generated)"
]
},
{
"cell_type": "markdown",
"id": "68otGuYcXPxF",
"metadata": {
"id": "68otGuYcXPxF"
},
"source": [
"#### 5.3.4 Create the Model"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "GDLHM8wrYTPx",
"metadata": {
"id": "GDLHM8wrYTPx"
},
"outputs": [],
"source": [
"vocab_size = tokenizer.n_vocab\n",
"num_transformer_blocks = 8\n",
"maxlen = 256\n",
"embed_dim = 256\n",
"num_heads = 8\n",
"feed_forward_dim = 256\n",
"batch_size = 256\n",
"num_epochs = 1"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6KUp1vWSXOwn",
"metadata": {
"id": "6KUp1vWSXOwn"
},
"outputs": [],
"source": [
"# Creates the miniGPT model with 4 transformer blocks.\n",
"def create_model(rngs):\n",
" return MiniGPT(maxlen, vocab_size, embed_dim, num_heads, feed_forward_dim, num_transformer_blocks=4, rngs=rngs)"
]
},
{
"cell_type": "markdown",
"id": "rLAJra8HX_Zg",
"metadata": {
"id": "rLAJra8HX_Zg"
},
"source": [
"### 5.4 Data Loading"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "VrTUOqyTYFN_",
"metadata": {
"id": "VrTUOqyTYFN_"
},
"outputs": [],
"source": [
"@dataclass\n",
"class TextDataset:\n",
" data: list\n",
" maxlen: int\n",
"\n",
" def __len__(self):\n",
" return len(self.data)\n",
"\n",
" def __getitem__(self, idx: int):\n",
" # Use Tiktoken for tokenization\n",
" encoding = tokenizer.encode(self.data[idx], allowed_special={'<|endoftext|>'})[:self.maxlen] # Tokenize and truncate\n",
" return encoding + [0] * (self.maxlen - len(encoding)) # Pad to maxlen\n",
"\n",
"def load_and_preprocess_data(file_path, batch_size, maxlen):\n",
"\n",
" with open(file_path, 'r') as f:\n",
" text = f.read()\n",
"\n",
" stories = text.split('<|endoftext|>')\n",
" stories = [story+'<|endoftext|>' for story in stories if story.strip()]\n",
" df = pd.DataFrame({'text': stories})\n",
" data = df['text'].dropna().tolist()\n",
" dataset = TextDataset(data, maxlen)\n",
"\n",
" sampler = pygrain.IndexSampler(\n",
" len(dataset),\n",
" shuffle=False,\n",
" seed=42,\n",
" shard_options=pygrain.NoSharding(),\n",
" num_epochs=num_epochs,\n",
" )\n",
"\n",
" dl = pygrain.DataLoader(\n",
" data_source=dataset,\n",
" sampler=sampler,\n",
" operations=[pygrain.Batch(batch_size=batch_size, drop_remainder=True)],\n",
" )\n",
"\n",
" return dl\n",
"\n",
"text_dl = load_and_preprocess_data('TinyStories-train.txt', batch_size, maxlen)"
]
},
{
"cell_type": "markdown",
"id": "_4XgtvUWYZz_",
"metadata": {
"id": "_4XgtvUWYZz_"
},
"source": [
"### 5.5 Loss Function and Training Step"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "Y6h0I6XtYfjM",
"metadata": {
"id": "Y6h0I6XtYfjM"
},
"outputs": [],
"source": [
"# Defines the loss function using `optax.softmax_cross_entropy_with_integer_labels`.\n",
"def loss_fn(model, batch):\n",
" logits = model(batch[0])\n",
" loss = optax.softmax_cross_entropy_with_integer_labels(logits=logits, labels=batch[1]).mean()\n",
" return loss, logits\n",
"\n",
"# Define the training step with the `flax.nnx.jit` transformation decorator.\n",
"@nnx.jit\n",
"def train_step(model: MiniGPT, optimizer: nnx.Optimizer, metrics: nnx.MultiMetric, batch):\n",
" grad_fn = nnx.value_and_grad(loss_fn, has_aux=True)\n",
" (loss, logits), grads = grad_fn(model, batch)\n",
" metrics.update(loss=loss, logits=logits, lables=batch[1])\n",
" optimizer.update(grads)"
]
},
{
"cell_type": "markdown",
"id": "Gdz1y5rpYggA",
"metadata": {
"id": "Gdz1y5rpYggA"
},
"source": [
"### 5.6 Train the model"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "_3WJfH3-Yp2N",
"metadata": {
"id": "_3WJfH3-Yp2N"
},
"outputs": [],
"source": [
"model = create_model(rngs=nnx.Rngs(0))\n",
"optimizer = nnx.Optimizer(model, optax.adam(1e-3))\n",
"metrics = nnx.MultiMetric(\n",
" loss=nnx.metrics.Average('loss'),\n",
")\n",
"rng = jax.random.PRNGKey(0)\n",
"\n",
"start_prompt = \"Once upon a time\"\n",
"start_tokens = tokenizer.encode(start_prompt)[:maxlen]\n",
"generated_text = model.generate_text(\n",
" maxlen, start_tokens\n",
")\n",
"print(f\"Initial generated text:\\n{generated_text}\\n\")\n",
"\n",
"\n",
"metrics_history = {\n",
" 'train_loss': [],\n",
"}\n",
"\n",
"prep_target_batch = jax.vmap(lambda tokens: jnp.concatenate((tokens[1:], jnp.array([0]))))\n",
"\n",
"step = 0\n",
"for epoch in range(num_epochs):\n",
" start_time = time.time()\n",
" for batch in text_dl:\n",
" if len(batch) % len(jax.devices()) != 0:\n",
" continue # skip the remaining elements\n",
" input_batch = jnp.array(jnp.array(batch).T)\n",
" target_batch = prep_target_batch(input_batch)\n",
" train_step(model, optimizer, metrics, jax.device_put((input_batch, target_batch), NamedSharding(mesh, P('batch', None))))\n",
"\n",
" if (step + 1) % 200 == 0:\n",
" for metric, value in metrics.compute().items():\n",
" metrics_history[f'train_{metric}'].append(value)\n",
" metrics.reset()\n",
"\n",
" elapsed_time = time.time() - start_time\n",
" print(f\"Step {step + 1}, Loss: {metrics_history['train_loss'][-1]}, Elapsed Time: {elapsed_time:.2f} seconds\")\n",
" start_time = time.time()\n",
"\n",
" generated_text = model.generate_text(\n",
" maxlen, start_tokens\n",
" )\n",
" print(f\"Generated text:\\n{generated_text}\\n\")\n",
" step += 1\n",
"\n",
"# Final text generation\n",
"generated_text = model.generate_text(\n",
" maxlen, start_tokens\n",
")\n",
"print(f\"Final generated text:\\n{generated_text}\")"
]
},
{
"cell_type": "markdown",
"id": "6b08042b",
"metadata": {
"id": "6b08042b"
},
"source": [
"**LLM Output**\n",
"\n",
"```\n",
"Initial generated text:\n",
"Once upon a timeaciaGender gearuser Analysisval {} Bruce Lauren helic Lauren Bruce againstliterally SQU retire Path {}valascript northwest {} Bruceuit Pathascript northwestdrops freelyvic996 curated hysteria survivor {}sclaxteradvert Sitting qualifiers snack {} scenariovalameron {} Path {}Nick VeganExcept peasantascript Whites retire {} retire {} Analysisrest {} Mine psychedelic flankForgeModLoader Path Bravo {} inflic {} strutConnector psychedelic beyond Beforeocker interesting Dani {}sclaxter retire {}Nick sorrow Typesrest interestingUV FSyrus resorts {} Dani {} perished {} retire interesting sorrow reversibleurned {} Womanlast 118 reass gentlestudyManager {} retire {} verb Captain forbid Bruce {} Analysis ox {} inexplicable tumor psychedelic {} serverpel perished Tang {} cropDisclaimeruti nond {} scenario teach serverlast {} Woman {}absor northwestroid variable {} Whites {} dancers iPod {} {}valolate Assist hiding ox {}ampionscre lineman servesShould decision psychedelicShould beyondwaves {} retire interesting Tangresterv ribbon complicationsaggressiverest {} SessionSmith {}Nick abnorm dissatisfiedundrum {} perished {} Gustav rolled shamefulundrum retire {}valundrumlast {}val {} perished Brigham Analysis developerscre Atom {}scl HouthInteger {} northwest appease miles {} perished THR Hyundai Captainケ {} Cube psychedelic {} inflic {} retire {} Whites dancers {}scl FS lore appease Din {} Whites abnorm[] {} {}scl FS appease dangling Bruce abnormcre97 psychedeliccrecrecrecre\n",
"\n",
"Step 200, Loss: 4.653054714202881, Elapsed Time: 108.56 seconds\n",
"Generated text:\n",
"Once upon a time, there a little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little little!!!!\n",
"\n",
"\n",
"Final generated text:\n",
"Once upon a time, there was a little girl named Lucy. She was very excited to go to the park. She put on her shoes and ran to the park.\n",
"When she got to the park, she saw a big slide. She wanted to go on it. She ran to the slide and started to slide down. She was so fast!\n",
"Suddenly, she heard a loud noise. It was a big, scary dog. The dog was barking loudly. Lucy was scared. She ran back to the park and started to run.\n",
"The dog was so fast that it ran away. Lucy was safe. She was so happy she had gone on the slide.\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "I4CfAK69Y2VF",
"metadata": {
"id": "I4CfAK69Y2VF"
},
"source": [
"#### 5.7 Inspect Training Curve and Save Checkpoint"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "IWCqOHBUY6gQ",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 472
},
"id": "IWCqOHBUY6gQ",
"outputId": "8b74ec45-38d1-4156-eda3-64d0eb3c3c19"
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAjcAAAHHCAYAAABDUnkqAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjAsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvlHJYcgAAAAlwSFlzAAAPYQAAD2EBqD+naQAASRhJREFUeJzt3Xl4VPXd///XZJuQZSYhkAUIYd8FZA98FVoQUOoNbq0Uf6BWWxXuG7rdLW1VxHqDenu3Wltc2kpVLFUqUK0oiAY3QHZZI3sC2diSyTpJZs7vjySjkRCSMDNnMnk+rutcyZw5Z/I+OZW8+lnOx2IYhiEAAIAgEWJ2AQAAAN5EuAEAAEGFcAMAAIIK4QYAAAQVwg0AAAgqhBsAABBUCDcAACCoEG4AAEBQIdwAAICgQrgB4HN33nmnunXr1qJzFy1aJIvF4t2CAAQ1wg3QhlksliZtGRkZZpdqijvvvFMxMTFmlwGgmSysLQW0Xa+++mq91y+//LI2bNigV155pd7+6667TklJSS3+OVVVVXK73bJarc0+t7q6WtXV1YqMjGzxz2+pO++8U6tWrVJJSYnffzaAlgszuwAA5rnjjjvqvd6yZYs2bNhw0f5vKisrU1RUVJN/Tnh4eIvqk6SwsDCFhfFPFYCmo1sKQKMmTJigQYMGaceOHbr22msVFRWlX/3qV5KktWvXatq0aerUqZOsVqt69uypRx99VC6Xq95nfHPMzYkTJ2SxWPS///u/euGFF9SzZ09ZrVaNHDlS27Ztq3duQ2NuLBaL5s2bpzVr1mjQoEGyWq0aOHCg3n333Yvqz8jI0IgRIxQZGamePXvq+eef9/o4njfeeEPDhw9Xu3bt1KFDB91xxx06ffp0vWPy8vJ01113qUuXLrJarUpJSdH06dN14sQJzzHbt2/XlClT1KFDB7Vr107du3fX3Xff7bU6gbaC/zsE4LLOnTun66+/XrfffrvuuOMOTxfV8uXLFRMTo5/85CeKiYnRBx98oIceekgOh0NPPvnkZT/3tddeU3FxsX70ox/JYrHoiSee0M0336xjx45dtrXnk08+0ZtvvqkHHnhAsbGxeuaZZ3TLLbcoKytLCQkJkqRdu3Zp6tSpSklJ0SOPPCKXy6XFixerY8eOV/5LqbV8+XLdddddGjlypJYsWaL8/Hw9/fTT+vTTT7Vr1y7FxcVJkm655Rbt379f//mf/6lu3bqpoKBAGzZsUFZWluf15MmT1bFjR/3yl79UXFycTpw4oTfffNNrtQJthgEAtebOnWt885+F8ePHG5KM55577qLjy8rKLtr3ox/9yIiKijIqKio8++bMmWOkpaV5Xh8/ftyQZCQkJBjnz5/37F+7dq0hyXjrrbc8+x5++OGLapJkREREGEeOHPHs27NnjyHJ+MMf/uDZd+ONNxpRUVHG6dOnPfsOHz5shIWFXfSZDZkzZ44RHR19yfcrKyuNxMREY9CgQUZ5ebln/9tvv21IMh566CHDMAzjwoULhiTjySefvORnrV692pBkbNu27bJ1AWgc3VIALstqtequu+66aH+7du083xcXF+vs2bO65pprVFZWpkOHDl32c7/3ve8pPj7e8/qaa66RJB07duyy506aNEk9e/b0vB48eLBsNpvnXJfLpffff18zZsxQp06dPMf16tVL119//WU/vym2b9+ugoICPfDAA/UGPE+bNk39+vXTv//9b0k1v6eIiAhlZGTowoULDX5WXQvP22+/raqqKq/UB7RVhBsAl9W5c2dFRERctH///v266aabZLfbZbPZ1LFjR89g5KKiost+bteuXeu9rgs6lwoAjZ1bd37duQUFBSovL1evXr0uOq6hfS1x8uRJSVLfvn0veq9fv36e961Wqx5//HGtW7dOSUlJuvbaa/XEE08oLy/Pc/z48eN1yy236JFHHlGHDh00ffp0vfTSS3I6nV6pFWhLCDcALuvrLTR1CgsLNX78eO3Zs0eLFy/WW2+9pQ0bNujxxx+XJLnd7st+bmhoaIP7jSY8oeJKzjXDggUL9OWXX2rJkiWKjIzUgw8+qP79+2vXrl2SagZJr1q1Sps3b9a8efN0+vRp3X333Ro+fDhT0YFmItwAaJGMjAydO3dOy5cv1/z58/Wd73xHkyZNqtfNZKbExERFRkbqyJEjF73X0L6WSEtLkyRlZmZe9F5mZqbn/To9e/bUT3/6U61fv1779u1TZWWlnnrqqXrHjBkzRo899pi2b9+uFStWaP/+/Vq5cqVX6gXaCsINgBapazn5ektJZWWl/vSnP5lVUj2hoaGaNGmS1qxZo5ycHM/+I0eOaN26dV75GSNGjFBiYqKee+65et1H69at08GDBzVt2jRJNc8FqqioqHduz549FRsb6znvwoULF7U6DR06VJLomgKaiangAFpk7Nixio+P15w5c/Rf//VfslgseuWVVwKqW2jRokVav369xo0bp/vvv18ul0vPPvusBg0apN27dzfpM6qqqvTb3/72ov3t27fXAw88oMcff1x33XWXxo8fr5kzZ3qmgnfr1k0//vGPJUlffvmlJk6cqO9+97saMGCAwsLCtHr1auXn5+v222+XJP3tb3/Tn/70J910003q2bOniouL9eKLL8pms+mGG27w2u8EaAsINwBaJCEhQW+//bZ++tOf6je/+Y3i4+N1xx13aOLEiZoyZYrZ5UmShg8frnXr1ulnP/uZHnzwQaWmpmrx4sU6ePBgk2ZzSTWtUQ8++OBF+3v27KkHHnhAd955p6KiorR06VL94he/UHR0tG666SY9/vjjnhlQqampmjlzpjZu3KhXXnlFYWFh6tevn15//XXdcsstkmoGFH/++edauXKl8vPzZbfbNWrUKK1YsULdu3f32u8EaAtYWwpAmzNjxgzt379fhw8fNrsUAD7AmBsAQa28vLze68OHD+udd97RhAkTzCkIgM/RcgMgqKWkpOjOO+9Ujx49dPLkSS1btkxOp1O7du1S7969zS4PgA8w5gZAUJs6dar+/ve/Ky8vT1arVenp6fqf//kfgg0QxGi5AQAAQYUxNwAAIKgQbgAAQFBpc2Nu3G63cnJyFBsbK4vFYnY5AACgCQzDUHFxsTp16qSQkMbbZtpcuMnJyVFqaqrZZQAAgBbIzs5Wly5dGj2mzYWb2NhYSTW/HJvNZnI1AACgKRwOh1JTUz1/xxvT5sJNXVeUzWYj3AAA0Mo0ZUgJA4oBAEBQIdwAAICgQrgBAABBhXADAACCCuEGAAAEFcINAAAIKoQbAAAQVAg3AAAgqBBuAABAUCHcAACAoEK4AQAAQYVwAwAAggrhxkuqXG7lOyqUda7M7FIAAGjTCDdesu3EeY3+n426+2/bzC4FAIA2jXDjJXHtIiRJhWVVJlcCAEDbRrjxkriocElSUXmlDMMwuRoAANouwo2X1IWbKpehskqXydUAANB2EW68pF14qCJCa36dheV0TQEAYBbCjZdYLBZP601hWaXJ1QAA0HYRbrzIM+6GQcUAAJiGcONFnhlTdEsBAGAawo0X2T3dUoQbAADMQrjxorh2teGmnDE3AACYhXDjRYy5AQDAfIQbL4qLqhlzc4HZUgAAmCZgws3SpUtlsVi0YMGCSx6zfPlyWSyWeltkZKT/irwMezvG3AAAYLYwswuQpG3btun555/X4MGDL3uszWZTZmam57XFYvFlac3iec4Ns6UAADCN6S03JSUlmjVrll588UXFx8df9niLxaLk5GTPlpSU5Icqm6ZuKjhjbgAAMI/p4Wbu3LmaNm2aJk2a1KTjS0pKlJaWptTUVE2fPl379+9v9Hin0ymHw1Fv85WvWm4YcwMAgFlMDTcrV67Uzp07tWTJkiYd37dvX/31r3/V2rVr9eqrr8rtdmvs2LE6derUJc9ZsmSJ7Ha7Z0tNTfVW+RdhzA0AAOYzLdxkZ2dr/vz5WrFiRZMHBaenp2v27NkaOnSoxo8frzfffFMdO3bU888/f8lzFi5cqKKiIs+WnZ3trUu4SF3LjbParYoqVgYHAMAMpg0o3rFjhwoKCjRs2DDPPpfLpY8++kjPPvusnE6nQkNDG/2M8PBwXX311Tpy5Mglj7FarbJarV6ruzEx1jCFhljkchsqLKtSsr3x+gEAgPeZFm4mTpyovXv31tt31113qV+/fvrFL35x2WAj1YShvXv36oYbbvBVmc1isVgU1y5c50orVVheqWR74ExTBwCgrTAt3MTGxmrQoEH19kVHRyshIcGzf/bs2ercubNnTM7ixYs1ZswY9erVS4WFhXryySd18uRJ3XPPPX6v/1LsUbXhhnE3AACYIiCec3MpWVlZCgn5aljQhQsXdO+99yovL0/x8fEaPny4PvvsMw0YMMDEKuuLY1AxAACmCqhwk5GR0ejr3/3ud/rd737nv4JaoG4JhiKmgwMAYArTn3MTbGi5AQDAXIQbL6truWEJBgAAzEG48TLPU4ppuQEAwBSEGy+rCzeMuQEAwByEGy9jCQYAAMxFuPEyz5gbwg0AAKYg3HhZ3WypIgYUAwBgCsKNl301oJgxNwAAmIFw42Vx7Wq6pUorXaqsdptcDQAAbQ/hxstiI8NksdR8T9cUAAD+R7jxspAQy9dmTNE1BQCAvxFufMCzBAMtNwAA+B3hxgfsTAcHAMA0hBsfiKNbCgAA0xBufOCrJRhouQEAwN8INz4QxxIMAACYhnDjA54xNyyeCQCA3xFufICWGwAAzEO48QHG3AAAYB7CjQ98tb4U4QYAAH8j3PhAHGNuAAAwDeHGBxhzAwCAeQg3PlDXclNcUa1qFyuDAwDgT4QbH7BFhnm+d1RUm1gJAABtD+HGB8JCQxRbG3BYggEAAP8i3PiIZ8YU08EBAPArwo2PxLWrGXdTxKBiAAD8inDjI1+13NAtBQCAPxFufMTOdHAAAExBuPERnlIMAIA5CDc+4hlzw4BiAAD8inDjI1+13DDmBgAAfyLc+EjdmJsLdEsBAOBXhBsf+WrxTMINAAD+RLjxkbpuqSK6pQAA8CvCjY94Vgan5QYAAL8i3PiIva7lprxKbrdhcjUAALQdhBsfqRtQbBhSMSuDAwDgN4QbH7GGhSoqIlQSSzAAAOBPhBsfimMJBgAA/C5gws3SpUtlsVi0YMGCRo9744031K9fP0VGRuqqq67SO++8458CW4Dp4AAA+F9AhJtt27bp+eef1+DBgxs97rPPPtPMmTP1gx/8QLt27dKMGTM0Y8YM7du3z0+VNg9PKQYAwP9MDzclJSWaNWuWXnzxRcXHxzd67NNPP62pU6fq5z//ufr3769HH31Uw4YN07PPPuunapsn7mszpgAAgH+YHm7mzp2radOmadKkSZc9dvPmzRcdN2XKFG3evPmS5zidTjkcjnqbv9hrF89kzA0AAP4TZuYPX7lypXbu3Klt27Y16fi8vDwlJSXV25eUlKS8vLxLnrNkyRI98sgjV1RnS33VLUW4AQDAX0xrucnOztb8+fO1YsUKRUZG+uznLFy4UEVFRZ4tOzvbZz/rm756SjFjbgAA8BfTWm527NihgoICDRs2zLPP5XLpo48+0rPPPiun06nQ0NB65yQnJys/P7/evvz8fCUnJ1/y51itVlmtVu8W30RfrS9Fyw0AAP5iWsvNxIkTtXfvXu3evduzjRgxQrNmzdLu3bsvCjaSlJ6ero0bN9bbt2HDBqWnp/ur7GbxjLlhQDEAAH5jWstNbGysBg0aVG9fdHS0EhISPPtnz56tzp07a8mSJZKk+fPna/z48Xrqqac0bdo0rVy5Utu3b9cLL7zg9/qbgqngAAD4n+mzpRqTlZWl3Nxcz+uxY8fqtdde0wsvvKAhQ4Zo1apVWrNmzUUhKVAwFRwAAP+zGIbRppasdjgcstvtKioqks1m8+nPyiuq0JglGxUWYtHhx66XxWLx6c8DACBYNefvd0C33LR2dS031W5DpZUuk6sBAKBtINz4UGR4qKxhNb9ixt0AAOAfhBsf40F+AAD4F+HGx+JYggEAAL8i3PiYPYqnFAMA4E+EGx/zLMFAyw0AAH5BuPExnnUDAIB/EW58LC6qbswN3VIAAPgD4cbHmC0FAIB/EW58LI7FMwEA8CvCjY95xtzQcgMAgF8QbnzMM1uKqeAAAPgF4cbH7Iy5AQDArwg3PuaZLVVepTa2ADsAAKYg3PhYXbdUZbVbFVVuk6sBACD4EW58LCoiVOGhFkmMuwEAwB8INz5msVhkZ/FMAAD8hnDjBzzIDwAA/yHc+EHduJsiuqUAAPA5wo0f0HIDAID/EG78wM4SDAAA+A3hxg9ouQEAwH8IN37AmBsAAPyHcOMHtNwAAOA/hBs/sNcuwXChjJYbAAB8jXDjB56VwWm5AQDA5wg3flDXLVXEbCkAAHyOcOMH8VEsvwAAgL8QbvzAXttyU17lUkWVy+RqAAAIboQbP4i1hik0pGZlcAddUwAA+BThxg9qVgavHVRMuAEAwKcIN37CjCkAAPyDcOMnds+D/HjWDQAAvkS48ZM4uqUAAPALwo2fxNVOBy+iWwoAAJ8i3PjJVwOK6ZYCAMCXCDd+wuKZAAD4B+HGTxhzAwCAfxBu/IQxNwAA+Afhxk88U8EZcwMAgE+ZGm6WLVumwYMHy2azyWazKT09XevWrbvk8cuXL5fFYqm3RUZG+rHiluMhfgAA+EeYmT+8S5cuWrp0qXr37i3DMPS3v/1N06dP165duzRw4MAGz7HZbMrMzPS8tlgs/ir3itAtBQCAf5gabm688cZ6rx977DEtW7ZMW7ZsuWS4sVgsSk5O9kd5XlXXclPsrFaVy63wUHoEAQDwhYD5C+tyubRy5UqVlpYqPT39kseVlJQoLS1Nqampmj59uvbv39/o5zqdTjkcjnqbGWy14UZiZXAAAHzJ9HCzd+9excTEyGq16r777tPq1as1YMCABo/t27ev/vrXv2rt2rV69dVX5Xa7NXbsWJ06deqSn79kyRLZ7XbPlpqa6qtLaVRoiEW2yJqGMqaDAwDgOxbDMAwzC6isrFRWVpaKioq0atUq/fnPf9amTZsuGXC+rqqqSv3799fMmTP16KOPNniM0+mU0+n0vHY4HEpNTVVRUZFsNpvXrqMprn3iQ2WdL9M/7x+r4Wnxfv3ZAAC0Zg6HQ3a7vUl/v00dcyNJERER6tWrlyRp+PDh2rZtm55++mk9//zzlz03PDxcV199tY4cOXLJY6xWq6xWq9fqvRJxUeHKOs/K4AAA+JLp3VLf5Ha767W0NMblcmnv3r1KSUnxcVXeUTdjiungAAD4jqktNwsXLtT111+vrl27qri4WK+99poyMjL03nvvSZJmz56tzp07a8mSJZKkxYsXa8yYMerVq5cKCwv15JNP6uTJk7rnnnvMvIwmYwkGAAB8z9RwU1BQoNmzZys3N1d2u12DBw/We++9p+uuu06SlJWVpZCQrxqXLly4oHvvvVd5eXmKj4/X8OHD9dlnnzVpfE4gqFs8s4huKQAAfMb0AcX+1pwBSd72f+sz9cwHRzQ7PU2Lpw/y688GAKA1a87f74AbcxPM7Iy5AQDA5wg3fsSYGwAAfI9w40eMuQEAwPcIN35UF25ouQEAwHcIN35kb8eYGwAAfI1w40d1LTeOiiq53G1qkhoAAH5DuPEje+2AYsOQiitovQEAwBcIN34UHhqiGGvtyuB0TQEA4BOEGz+zMx0cAACfItz4mWfGFNPBAQDwCcKNn3medUPLDQAAPkG48bM4poMDAOBThBs/s3u6pQg3AAD4AuHGz75aX4oxNwAA+ALhxs++Wl+KlhsAAHyBcONncVG1Y24YUAwAgE8QbvzM0y3FVHAAAHyCcONnnpYbuqUAAPAJwo2feR7iR7cUAAA+Qbjxs693S7lZGRwAAK8j3PiZrTbcuA2ppLLa5GoAAAg+hBs/iwwPVbvwUElMBwcAwBcINyaI4ynFAAD4DOHGBHaeUgwAgM8QbkxAyw0AAL5DuDGBZ2VwpoMDAOB1hBsTfLW+FN1SAAB4G+HGBHa6pQAA8BnCjQnolgIAwHcINyZgQDEAAL5DuDFB3RIMRUwFBwDA6wg3JmDMDQAAvtOicJOdna1Tp055Xn/++edasGCBXnjhBa8VFswYcwMAgO+0KNx8//vf14cffihJysvL03XXXafPP/9cv/71r7V48WKvFhiMvpoKXiXDYGVwAAC8qUXhZt++fRo1apQk6fXXX9egQYP02WefacWKFVq+fLk36wtK8VE1LTeVLrfKq1wmVwMAQHBpUbipqqqS1WqVJL3//vv6j//4D0lSv379lJub673qglRkeIgiwmp+9edKGFQMAIA3tSjcDBw4UM8995w+/vhjbdiwQVOnTpUk5eTkKCEhwasFBiOLxaKu7aMkSUfOlJhcDQAAwaVF4ebxxx/X888/rwkTJmjmzJkaMmSIJOlf//qXp7sKjRvYySZJ2n+6yORKAAAILmEtOWnChAk6e/asHA6H4uPjPft/+MMfKioqymvFBbOBnWxauztH+3McZpcCAEBQaVHLTXl5uZxOpyfYnDx5Ur///e+VmZmpxMTEJn/OsmXLNHjwYNlsNtlsNqWnp2vdunWNnvPGG2+oX79+ioyM1FVXXaV33nmnJZdgukGd7JJEuAEAwMtaFG6mT5+ul19+WZJUWFio0aNH66mnntKMGTO0bNmyJn9Oly5dtHTpUu3YsUPbt2/Xt7/9bU2fPl379+9v8PjPPvtMM2fO1A9+8APt2rVLM2bM0IwZM7Rv376WXIapBtR2S2WdL5OjgufdAADgLS0KNzt37tQ111wjSVq1apWSkpJ08uRJvfzyy3rmmWea/Dk33nijbrjhBvXu3Vt9+vTRY489ppiYGG3ZsqXB459++mlNnTpVP//5z9W/f389+uijGjZsmJ599tmWXIap4qIi1DmunSTpAK03AAB4TYvCTVlZmWJjYyVJ69ev180336yQkBCNGTNGJ0+ebFEhLpdLK1euVGlpqdLT0xs8ZvPmzZo0aVK9fVOmTNHmzZtb9DPN5hlUTLgBAMBrWhRuevXqpTVr1ig7O1vvvfeeJk+eLEkqKCiQzWZr1mft3btXMTExslqtuu+++7R69WoNGDCgwWPz8vKUlJRUb19SUpLy8vIu+flOp1MOh6PeFigGesbdMGMKAABvaVG4eeihh/Szn/1M3bp106hRozwtLevXr9fVV1/drM/q27evdu/era1bt+r+++/XnDlzdODAgZaU1aAlS5bIbrd7ttTUVK999pWqa7mhWwoAAO9pUbi59dZblZWVpe3bt+u9997z7J84caJ+97vfNeuzIiIi1KtXLw0fPlxLlizRkCFD9PTTTzd4bHJysvLz8+vty8/PV3Jy8iU/f+HChSoqKvJs2dnZzarPlwZ2rgk3hwtKVMEyDAAAeEWLwo1UEzSuvvpq5eTkeFYIHzVqlPr163dFBbndbjmdzgbfS09P18aNG+vt27BhwyXH6EiS1Wr1TDWv2wJFsi1S7aMj5HIbyswrNrscAACCQovCjdvt1uLFi2W325WWlqa0tDTFxcXp0UcfldvtbvLnLFy4UB999JFOnDihvXv3auHChcrIyNCsWbMkSbNnz9bChQs9x8+fP1/vvvuunnrqKR06dEiLFi3S9u3bNW/evJZchuksFguDigEA8LIWPaH417/+tf7yl79o6dKlGjdunCTpk08+0aJFi1RRUaHHHnusSZ9TUFCg2bNnKzc3V3a7XYMHD9Z7772n6667TpKUlZWlkJCv8tfYsWP12muv6Te/+Y1+9atfqXfv3lqzZo0GDRrUkssICAM72fXx4bMMKgYAwEsshmEYzT2pU6dOeu655zyrgddZu3atHnjgAZ0+fdprBXqbw+GQ3W5XUVFRQHRRvbUnR//5910amhqnNXPHmV0OAAABqTl/v1vULXX+/PkGx9b069dP58+fb8lHtll13VKH8hxyuZudMwEAwDe0KNwMGTKkwacCP/vssxo8ePAVF9WWdEuIVnREqCqq3Dp2psTscgAAaPVaNObmiSee0LRp0/T+++97Zipt3rxZ2dnZrXYhS7OEhFjUP8Wm7ScvaH+OQ72TYs0uCQCAVq1FLTfjx4/Xl19+qZtuukmFhYUqLCzUzTffrP379+uVV17xdo1Br65rat9pBhUDAHClWtRyI9UMKv7mrKg9e/boL3/5i1544YUrLqwt+WoZBqaDAwBwpVr8ED94zwDPs26K1ILJawAA4GsINwGgT1KswkMtclRU69SFcrPLAQCgVSPcBICIsBD1qR1ITNcUAABXplljbm6++eZG3y8sLLySWtq0gZ1s2p/j0IGcIk0ddOmFQAEAQOOaFW7sdvtl3589e/YVFdRW1QwqPkXLDQAAV6hZ4eall17yVR1tHgtoAgDgHYy5CRD9U2yyWKQ8R4XOljjNLgcAgFaLcBMgoq1h6p4QLYnWGwAArgThJoB8/Xk3AACgZQg3AYQnFQMAcOUINwGkblDxAcINAAAtRrgJIHXh5vjZUpU4q02uBgCA1olwE0ASYqxKsUdKkg7m0noDAEBLEG4CjOd5N6cZVAwAQEsQbgLMAAYVAwBwRQg3Aaau5WYf4QYAgBYh3ASYunBzOL9YzmqXydUAAND6EG4CTOe4drK3C1e129Dh/BKzywEAoNUh3AQYi8XytUU0GVQMAEBzEW4CECuEAwDQcoSbADSoMzOmAABoKcJNAKpruTmY65DLbZhcDQAArQvhJgB17xCjduGhKqt06cS5UrPLAQCgVSHcBKDQEIv6pcRKkvbxpGIAAJqFcBOgWCEcAICWIdwEqIEswwAAQIsQbgLU1591YxgMKgYAoKkINwGqT1KsQkMsulBWpdyiCrPLAQCg1SDcBKjI8FD1ToyRRNcUAADNQbgJYANYhgEAgGYj3ASwQQwqBgCg2Qg3AcwzqJhn3QAA0GSEmwBW1y2VU1ShC6WVJlcDAEDrQLgJYLGR4UpLiJJE1xQAAE1FuAlwAxlUDABAs5gabpYsWaKRI0cqNjZWiYmJmjFjhjIzMxs9Z/ny5bJYLPW2yMhIP1XsfzypGACA5jE13GzatElz587Vli1btGHDBlVVVWny5MkqLW18JWybzabc3FzPdvLkST9V7H9MBwcAoHnCzPzh7777br3Xy5cvV2Jionbs2KFrr732kudZLBYlJyf7uryAUNctdexsqcoqqxUVYeotAwAg4AXUmJuioprWifbt2zd6XElJidLS0pSamqrp06dr//79lzzW6XTK4XDU21qTxNhIdYy1yjCkg7nFZpcDAEDAC5hw43a7tWDBAo0bN06DBg265HF9+/bVX//6V61du1avvvqq3G63xo4dq1OnTjV4/JIlS2S32z1bamqqry7BZwbVtt7syrpgciUAAAQ+ixEgS07ff//9WrdunT755BN16dKlyedVVVWpf//+mjlzph599NGL3nc6nXI6nZ7XDodDqampKioqks1m80rtvvbSp8f1yFsHNKp7e73+o3SzywEAwO8cDofsdnuT/n4HRMvNvHnz9Pbbb+vDDz9sVrCRpPDwcF199dU6cuRIg+9brVbZbLZ6W2tz3YAkSdL2E+d1rsR5maMBAGjbTA03hmFo3rx5Wr16tT744AN179692Z/hcrm0d+9epaSk+KDCwNAlPkqDOtvkNqSNBwvMLgcAgIBmariZO3euXn31Vb322muKjY1VXl6e8vLyVF5e7jlm9uzZWrhwoef14sWLtX79eh07dkw7d+7UHXfcoZMnT+qee+4x4xL8ZvKAmtlh6w/kmVwJAACBzdRws2zZMhUVFWnChAlKSUnxbP/4xz88x2RlZSk3N9fz+sKFC7r33nvVv39/3XDDDXI4HPrss880YMAAMy7BbyYPrOma+ujwWZU6q02uBgCAwBUwA4r9pTkDkgKJYRia8L8ZOnmuTMtmDdP1VwVvNxwAAN/U6gYU4/IsFosm1w4sXn8g3+RqAAAIXISbVmTKwJpxNxsP5qvK5Ta5GgAAAhPhphW5umu8OsREyFFRra3HzptdDgAAAYlw04qEhlg0qX9d1xSzpgAAaAjhppWp65pavz9fbnebGgsOAECTEG5amfSeCYqOCFWeo0J7TxeZXQ4AAAGHcNPKRIaHakLfREl0TQEA0BDCTStU90C/9/YzJRwAgG8i3LRC3+qXqPBQi44UlOjomRKzywEAIKAQblohW2S40nt2kCRt4IF+AADUQ7hppeqeVvzefsbdAADwdYSbVuq62nCzK6tQBY4Kk6sBACBwEG5aqSRbpK7uGieJtaYAAPg6wk0rNnlA7QP9CDcAAHgQblqxKbVTwjcfPStHRZXJ1QAAEBgIN61Yj44x6pUYoyqXoQ8PFZhdDgAAAYFw08rVzZqiawoAgBqEm1aubiHNjEMFqqhymVwNAADmI9y0cld1tivZFqnSSpc2Hz1ndjkAAJiOcNPKhYRYPM+8YSFNAAAIN0Ghrmtqw4F8udyGydUAAGAuwk0QGN2jvWyRYTpbUqldWRfMLgcAAFMRboJAeGiIJvZn1hQAABLhJmh8fSFNw6BrCgDQdhFugsS1fToqIixEJ8+V6cv8ErPLAQDANISbIBFtDdO1vTtIqmm9AQCgrSLcBJGvFtIk3AAA2i7CTRCZ2D9RIRZp32mHTheWm10OAACmINwEkYQYq0Z0ay9JWk/XFACgjSLcBJm6B/q9suWkqlxuk6sBAMD/CDdB5rYRXZQQHaFjZ0q1YstJs8sBAMDvCDdBxhYZrh9f10eS9PuNh1VUVmVyRQAA+BfhJgjdPjJVfZJiVFhWpWc+OGx2OQAA+BXhJgiFhYboN9MGSJJe3nxCx8+WmlwRAAD+Q7gJUtf26ahv9e2oKpeh/3nnoNnlAADgN4SbIPbraf0VGmLRhgP5+uzoWbPLAQDALwg3QaxXYqzuGN1VkvTo2wflcrOgJgAg+BFugtyCSX1kiwzTwVyHVu3INrscAAB8jnAT5OKjI/RfE3tLkp5870uVOKtNrggAAN8i3LQBs9O7qVtClM6WOLUs44jZ5QAA4FOmhpslS5Zo5MiRio2NVWJiombMmKHMzMzLnvfGG2+oX79+ioyM1FVXXaV33nnHD9W2XhFhIVp4Q39J0osfH9epC2UmVwQAgO+YGm42bdqkuXPnasuWLdqwYYOqqqo0efJklZZe+rksn332mWbOnKkf/OAH2rVrl2bMmKEZM2Zo3759fqy89Zk8IEljerRXZbVbj797+QAJAEBrZTEMI2Cm0Jw5c0aJiYnatGmTrr322gaP+d73vqfS0lK9/fbbnn1jxozR0KFD9dxzz132ZzgcDtntdhUVFclms3mt9tZgf06RvvOHT2QY0j/vH6vhafFmlwQAQJM05+93QI25KSoqkiS1b9/+ksds3rxZkyZNqrdvypQp2rx5c4PHO51OORyOeltbNbCTXbcN7yJJevTtA3IzNRwAEIQCJty43W4tWLBA48aN06BBgy55XF5enpKSkurtS0pKUl5eXoPHL1myRHa73bOlpqZ6te7W5meT+yoqIlS7swv11hc5ZpcDAIDXBUy4mTt3rvbt26eVK1d69XMXLlyooqIiz5ad3baf9ZJoi9QDE3pKkh5fd0jllS6TKwIAwLsCItzMmzdPb7/9tj788EN16dKl0WOTk5OVn59fb19+fr6Sk5MbPN5qtcpms9Xb2rp7rumhznHtlFNUob98cszscgAA8CpTw41hGJo3b55Wr16tDz74QN27d7/sOenp6dq4cWO9fRs2bFB6erqvygw6keGh+u+pfSVJf8o4qgJHhckVAQDgPaaGm7lz5+rVV1/Va6+9ptjYWOXl5SkvL0/l5eWeY2bPnq2FCxd6Xs+fP1/vvvuunnrqKR06dEiLFi3S9u3bNW/ePDMuodX6jyGddHXXOJVVurT03UNmlwMAgNeYGm6WLVumoqIiTZgwQSkpKZ7tH//4h+eYrKws5ebmel6PHTtWr732ml544QUNGTJEq1at0po1axodhIyLWSwWPfidAZKkN3ee1jMbD5tcEQAA3hFQz7nxh7b8nJuG/PnjY/rtvw9Kkn55fT/dN76nyRUBAHCxVvucG/jfPdf00M+n1Iy/WbrukP7yyXGTKwIA4MoQbqC53+ql+bUrhz/69gG9svmEuQUBAHAFCDeQJC2Y1Fv31z7/5sG1+7Xy8yyTKwIAoGUIN5BUM8D4v6f01T3/r2Y6/sLVe/XPHadMrgoAgOYj3MDDYrHo19P6a056mgxD+vmqPfrXHpZoAAC0LoQb1GOxWPTwjQM1c1Sq3Ib043/s1rq9uZc/EQCAAEG4wUVCQix6bMZVumVYF7nchv7z77v0/oH8y58IAEAAINygQSEhFj1x62BNH9pJ1W5DD6zYqYzMArPLAgDgsgg3uKTQEIueum2IbrgqWZUut374yg59euSs2WUBANAowg0aFRYaoqdvv1qT+iepstqtu5dv07KMo6pyuc0uDQCABhFucFnhoSH646yagOOsduvxdw/pO898ou0nzptdGgAAFyHcoEmsYaF6cfZwPXnrYMVHhSszv1i3PrdZv/znFyosqzS7PAAAPAg3aDKLxaLbRqRq408n6LsjukiSVm7L1sSnNunNnafUxtZgBQAEKMINmq19dISeuHWI/vHDMeqVGKNzpZX6yet79P0Xt+romRKzywMAtHGEG7TY6B4Jeue/rtHPp/SVNSxEm4+d0/W//1j/t+FLVVS5zC4PANBGEW5wRSLCQjT3W7204cfjNaFvR1W63Hpm42FN/f1H+uQw08YBAP5HuIFXdE2I0kt3jtQfvz9MibFWnThXpjv+slX3v7pDWefKzC4PANCGWIw2NgrU4XDIbrerqKhINpvN7HKCUnFFlZ5a/6Ve3nxCbkOKCA3RXeO6ae63e8kWGW52eQCAVqg5f78JN/CZQ3kOPfbvg/q4tnsqITpCP76uj24fmaqwUBoNAQBNR7hpBOHGvwzD0IeZBfrtvw/q2JlSSVKfpBj9ZtoAXduno8nVAQBaC8JNIwg35qhyubViy0n9fuNhFZZVSZK+1bejfj1tgHolxphcHQAg0BFuGkG4MVdhWaWe2XhEL28+oWq3odAQi+4Y3VULJvVRfHSE2eUBAAIU4aYRhJvAcOxMif7nnUN6/2C+JMkWGaY7x3XXbcO7KLV9lMnVAQACDeGmEYSbwPLpkbN69O0DOpRX7Nk3tmeCvjsiVVMGJqtdRKiJ1QEAAgXhphGEm8Djchv6995c/WNblj49cs6zP9YaphuHdtJtw7toaGqcLBaLiVUCAMxEuGkE4SawZZ8v0z93ntIb20/pdGG5Z3/vxBjdNqKLbrq6izrGWk2sEABgBsJNIwg3rYPbbWjLsXN6fXu21u3Lk7PaLUkKDbHoW30T9R9DO2lM9/ZKtEWaXCkAwB8IN40g3LQ+jooqvbUnR29sP6Xd2YX13ktLiNLIbu01qlt7jezeXt0Soui+AoAgRLhpBOGmdTucX6xVO07p48NndTDPoW/+r7djrLUm6HSL18ju7dUv2abQEMIOALR2hJtGEG6Ch6OiSjtOXtDnx89r2/Hz+uJUkSpd7nrHxFrDNLpHe906vIsm9k9SOMs+AECrRLhpBOEmeFVUubQnu1DbTpzX5ycuaOfJCypxVnveT7JZ9b2RXTVzVKpS7O1MrBQA0FyEm0YQbtqOapdbh/KK9e+9uXp9W7bOlVZKqhmUPLFfomaNSdM1vToohG4rAAh4hJtGEG7aJme1S+/tz9eKLSe19fh5z/6u7aP0/dFdddvwLkqIYYo5AAQqwk0jCDc4nF+sFVuz9M8dp1Rc220VERqiG65K1qwxaRqRFs+MKwAIMISbRhBuUKesslpv7cnRq1uytPd0kWd/v+RYzRnbTdOHdlJURJiJFQIA6hBuGkG4QUO+OFWoV7ec1L/25KiiqmbGlS0yTN8dkao7xqSpW4dokysEgLaNcNMIwg0aU1RWpTd2ZOvlzSeVdb5MkmSxSBP6dNTssd00vnfHZg1Arqx26+iZEh3Mdaiy2q0BnWzqkxSryHAWBAWA5iDcNIJwg6Zwuw1t+vKM/rb5hDIyz3j2pyVE6f8bk6bbhqfKHhVe75wLpZU6mOvQgdrtYG6xjhQUq8pV/z+xsBCL+iTFalBnmwZ1tmtQZ7v6J9tYAR0AGkG4aQThBs11/GypXt1yUq9vz1ZxRc0A5MjwEM0Y2lkJMRE6kFMTZPIcFQ2eHxsZpv4pNlnDQrTvdJEulFVddEyIReqVGKNBnWrCTt/kWEVbw2QNC1FEWMjXvobWfB8awhR2AG0K4aYRhBu0VFlltdbsytHLm0/oUF5xg8ekJUSpf7JN/VNs6p8SqwGdbOoc184z+8owDOUUVWjvqSLtzynSvtNF2nvaobMlzmbXExFaE3jaRYRq8oAk/dfE3kpiIVEAQarVhJuPPvpITz75pHbs2KHc3FytXr1aM2bMuOTxGRkZ+ta3vnXR/tzcXCUnJzfpZxJucKUMw9Dnx8/rzZ2nFRIiDUipCTN9k2MVGxl++Q9o4PMKip21QadI+047dOxsiZxVbjmr3XJWu1RZ7fasjH4pkeEhmjO2m+4f31NxUREtvTwACEjN+ftt6jzX0tJSDRkyRHfffbduvvnmJp+XmZlZ78ISExN9UR7QIIvFotE9EjS6R4LXPi/JFqkkW6Qm9k+65HGGYajKZdQLO5XVbmWdL9MzGw9r+8kLen7TMb22NUv3je+pu8Z1u6Kp7G63oSq3W9YwxgIBaF1MDTfXX3+9rr/++mafl5iYqLi4OO8XBAQwi8WiiDCLIsLqL/7ZrUO0rundQR8cKtCT72XqUF6xnnwvUy99ekL/NbGXbh/Z9aJzLiXfUaGPvjyjjw6f1SeHz6iovEoDO9k1olu8RnVrrxHd2qtjLE9yBhDYWuUTyoYOHSqn06lBgwZp0aJFGjdu3CWPdTqdcjq/Gs/gcDj8USLgVxaLRRP7J+lbfRP1rz05+r8NXyrrfJkeWrtfL358TD+e1EfTh3ZW6DcGITurXdp2/II+OnxGH315psGxRHtru8te+vSEJKlHh2iN7Na+JvB0b6+u7aN4ojOAgBIwA4otFstlx9xkZmYqIyNDI0aMkNPp1J///Ge98sor2rp1q4YNG9bgOYsWLdIjjzxy0X7G3CCYVVa79Y/t2Xpm42GdKa4J932TYvWzKX3Vo2N0TevMl2e05dh5lVe5POdZLNLgznZd26ejru3TUSn2SO3MKtS24+e17cR5ZeYX65v/YiTGWjWye3uNTIvXwNqZXrYWjD0CgMa0mgHFX9eUcNOQ8ePHq2vXrnrllVcafL+hlpvU1FTCDdqEsspqLf/shJ7LOCpH7TT2b0qMteqa3h11bZ8OuqZ3R7WPvvRg5KKyKm0/eV7bTlzQthPn9cWpwoue4yNJnePaqV9yrPqlxKpvsk39k2PVvUO0wkKb1j0GAN/UagYUe8OoUaP0ySefXPJ9q9Uqq5UxAmiboiLC9MCEXpo1Kk3PfXRUL316XG63NLJ7vK7tXdM60y85tsndSvaocE3sn+QZ+FxR5dLu7JqWnV3ZhTqU61BOUYVOF5brdGG5Nh4q8JwbERaiXh1jagJPUqwiwkJUVulSqbO6Zqt0qayyWqXO+l9LnC653G6FhlhqNotFISEWhYXUfA21WDzvhYVYFBMZpmFd4zW6e4KGpcWxPhjQBrX6lpvrrrtOsbGxevPNN5t0PFPB0ZY5q10yDPl0+Yeisipl5hfrUF7Nww0z8xzKzCtWaaXr8id7WViIRYO72Gtmt3WvGRAdYyXsAK1Rq2m5KSkp0ZEjRzyvjx8/rt27d6t9+/bq2rWrFi5cqNOnT+vll1+WJP3+979X9+7dNXDgQFVUVOjPf/6zPvjgA61fv96sSwBaFX9M67ZHhWtU9/Ya1b29Z5/bbejUhXIdynPoUF6xDheUyDAMRUeEKcoaquiIMEVbwxRtDVVURJiiI0IVZa39GhGmsFCLXG5DLrcht2Go2m3IXfva5TbkMr76vqDYqc+Pn9fWY+eUU1ShnVmF2plVqGUZRxUaYtGgTjaN6t5eo7snaGT39rK3Y3wQEGxMDTfbt2+v91C+n/zkJ5KkOXPmaPny5crNzVVWVpbn/crKSv30pz/V6dOnFRUVpcGDB+v9999v8MF+AAJHSIhFXROi1DUhSpMHNu2Bm1di5qiuMoyaQLXl2DltPX5eW4+fU/b5cu05VaQ9p4r04sfHZbFI3RKiNSDFpgGdap8qnWJXks3a5K46wzB0urBch3KLlZlfrIO5NQHubIlThlHzviFJhmToq9eGIRkyZBjyPGX6thGpGpEWz+wz4AoFTLeUv9AtBbRdOYXl2nr8nLYeO6+tx8/r+NnSBo9rHx1RG3TqQo9NPTvGqKLKpS/zi3Uwt6bbLTOvWIdyi1XsbHiwdkt0S4jSrcO76KZhXdQ5rp3XPhdo7VrlbCl/IdwAqHO2xFmzkntO7WruOQ4dO1sql/vifxbDQy0Nzgyre69nx5jaGWI29UuO9awpZrFIFtWMK6z5KllUs7/OqQvlenPnKf17b67KascmWSzSuJ4ddNuILpo8IJlV4/2g2uVW9oVyHSko0fGzJbLIovbREWofE6GE6AjFR0UoISaCQeomIdw0gnADoDF1rTM1q73XhJ6DucUqqW2dSbZF1k5xj1X/ZJv6pcSqR4eYJj8FujGlzmq9uy9Pb+zI1pZj5z37Y61h+s6QFN06PFXDusZd1G1lGIac1W6V1M48K66o+VrirFZoiEWxkeGyRYYpNjJcsZFhiooI9WnX1/nSSu3JLtSu7ELtzi7UgRyHOsVFamzPDhrXK0Eju7X36aD2yymrrNbRglIdPVOiIwUlOnqmZjtxtkyVrsbXcJNq1nFLiLaqfXSE4qNrgk/nuHYa3MWuoV3jlBjLAra+QLhpBOEGQHO53TXjamKsYYpv5DlA3pR9vkz/3HlKq3ac0qkL5Z793RKilBBjVUlFTXipCzTVDbQ2XUpoiEUx1jDFfi3w2CLDZG8XoUSbVUmxViXaIpUYa1WSLVIdY62XDCPOapcO5Di0uzbI7M4u1MlzZY3+/IjQEA1Li9O4nh00tlcHDelib9EzkCqr3bpQVqniimoVV1TV/D4qasJdsef7mv3FzmoVllXq+JlS5RRVXPIzI8ND1KNDjHomxijEUhPUzpVU6kJZpc6VVqryMgvYSjXPeRqaGqeru8ZpaGqcBnW2mxrmggXhphGEGwCtidttaOvx81q145Te2Ztb74nSDYmOCFW0NUwx1poZaC63oWJnVW0AqG6wy60pbJFhSrJFKtFmVWJspNpFhGp/jkMHcxwNtnb06Bhd8wc+NU4DOtl18lypPj1yTp8dPavcb4SLGGuYRndvr7G9alp2OsW105lipwocThUUV+hMsdOzFXi+VuhCWVWLrkWSEqIj1DMxRj07xqhnx2j1qv2+c1w7hYQ03KplGIZKK106X1Kp82WVOl/q1LmSSp0vrdTRMyXanV1YOxOw/nlhIRb1S4nV0NQ4DU2NV9+kWDmrXXJUVMlRXl37tUqOiurar1/tL3FWq1tCtK5OjdPQrnEakhoXsE8Ad7sNbT52Tq9tzVK/5Fj958TeXv18wk0jCDcAWqsSZ7U+PXJWhlETCGIiwxRj/VqYiQi75B9mqeaPc3mVy9PSUVRe87Uu+Fwoq9SZYqfyHRUqqA0Q+Q7nZVsr4qPCPX+4r+4apyFd4mSPavgPsGEYOn62VJ8eOatPj5zT5mPnVFTe8pASYpFiI8O/1hIVVvu7qWmRirWGeX5XtshwpSVEqWfHGJ+1wBVXVGnvqSJPl9zu7ELPEijeYLFIPTvG1GsZ6psUa+rTv8+XVmrVjmz9/fNszyD9JJtVn/1y4kXr2V0Jwk0jCDcA0HSGYchRXu0JOgXFNcGnuKJKfZJqWiOuZPFUl9vQgRyHPj16Vp8eOattJ86rosqtWGuYOtqsSoy1qmNsZO1X69e+1nSXxbULbzTQmc0wDOUUVWh3VqF2Z1/Q7uxCHT9bphhrqGztwmWLDJetXVjt15qxUV/fbw0LVWZesScoZZ2/uMuvXXiorupi19WpcUptH6V24aGKDA9VZHjIN77WbmE1r9uFh7b4d2cYhraduKAVW09q3d48T+tdjDVMN13dWd8f3VX9U7z7N5Zw0wjCDQAEriqXW9Uug9lhl3C2xFkzWDurJuzsyS5s8aMIIsJC1KNDtPomx6pPUqx6J8aoT1KsUttHXbLFpaisSv/ceUqvfZ6lIwUlnv2Du9j1/VFddeOQTor20VPACTeNINwAAIKF223o6JkS7aoNOmeKnaqodquiyiVnlUsVVW6VV7lUUbdVuy/bzWgNC1Gv2qBTs8WoXUSo/rnjtN7+IkfO2vOjIkI1fWgnfX9Umq7qYvf5tRJuGkG4AQC0ZW63oYpql84WV+rL/GJ9WVCsw/kl+jK/WEcKSjzh5VL6Jcdq1pg0zRjaSbF+HNzcataWAgAA/hUSYlFURJi6JoSpa0KUJg1I8rznchvKOl+mL/OLdTi/WF/Whp4zxU5N6JuoWWO66urUi5+1FGgINwAAQFLNM5C6d4hW9w7RmuKHdeB8xby5YwAAAD5AuAEAAEGFcAMAAIIK4QYAAAQVwg0AAAgqhBsAABBUCDcAACCoEG4AAEBQIdwAAICgQrgBAABBhXADAACCCuEGAAAEFcINAAAIKoQbAAAQVMLMLsDfDMOQJDkcDpMrAQAATVX3d7vu73hj2ly4KS4uliSlpqaaXAkAAGiu4uJi2e32Ro+xGE2JQEHE7XYrJydHsbGxslgsXv1sh8Oh1NRUZWdny2azefWzA0GwX58U/NfI9bV+wX6NXF/r56trNAxDxcXF6tSpk0JCGh9V0+ZabkJCQtSlSxef/gybzRa0/6OVgv/6pOC/Rq6v9Qv2a+T6Wj9fXOPlWmzqMKAYAAAEFcINAAAIKoQbL7JarXr44YdltVrNLsUngv36pOC/Rq6v9Qv2a+T6Wr9AuMY2N6AYAAAEN1puAABAUCHcAACAoEK4AQAAQYVwAwAAggrhxkv++Mc/qlu3boqMjNTo0aP1+eefm12S1yxatEgWi6Xe1q9fP7PLarGPPvpIN954ozp16iSLxaI1a9bUe98wDD300ENKSUlRu3btNGnSJB0+fNicYlvoctd45513XnRPp06dak6xLbBkyRKNHDlSsbGxSkxM1IwZM5SZmVnvmIqKCs2dO1cJCQmKiYnRLbfcovz8fJMqbp6mXN+ECRMuuof33XefSRU3z7JlyzR48GDPQ97S09O1bt06z/ut+d7Vudw1tub715ClS5fKYrFowYIFnn1m3kfCjRf84x//0E9+8hM9/PDD2rlzp4YMGaIpU6aooKDA7NK8ZuDAgcrNzfVsn3zyidkltVhpaamGDBmiP/7xjw2+/8QTT+iZZ57Rc889p61btyo6OlpTpkxRRUWFnyttuctdoyRNnTq13j39+9//7scKr8ymTZs0d+5cbdmyRRs2bFBVVZUmT56s0tJSzzE//vGP9dZbb+mNN97Qpk2blJOTo5tvvtnEqpuuKdcnSffee2+9e/jEE0+YVHHzdOnSRUuXLtWOHTu0fft2ffvb39b06dO1f/9+Sa373tW53DVKrff+fdO2bdv0/PPPa/DgwfX2m3ofDVyxUaNGGXPnzvW8drlcRqdOnYwlS5aYWJX3PPzww8aQIUPMLsMnJBmrV6/2vHa73UZycrLx5JNPevYVFhYaVqvV+Pvf/25ChVfum9doGIYxZ84cY/r06abU4wsFBQWGJGPTpk2GYdTcs/DwcOONN97wHHPw4EFDkrF582azymyxb16fYRjG+PHjjfnz55tXlJfFx8cbf/7zn4Pu3n1d3TUaRvDcv+LiYqN3797Ghg0b6l2T2feRlpsrVFlZqR07dmjSpEmefSEhIZo0aZI2b95sYmXedfjwYXXq1Ek9evTQrFmzlJWVZXZJPnH8+HHl5eXVu592u12jR48OqvspSRkZGUpMTFTfvn11//3369y5c2aX1GJFRUWSpPbt20uSduzYoaqqqnr3sV+/furatWurvI/fvL46K1asUIcOHTRo0CAtXLhQZWVlZpR3RVwul1auXKnS0lKlp6cH3b2TLr7GOsFw/+bOnatp06bVu1+S+f8NtrmFM73t7NmzcrlcSkpKqrc/KSlJhw4dMqkq7xo9erSWL1+uvn37Kjc3V4888oiuueYa7du3T7GxsWaX51V5eXmS1OD9rHsvGEydOlU333yzunfvrqNHj+pXv/qVrr/+em3evFmhoaFml9csbrdbCxYs0Lhx4zRo0CBJNfcxIiJCcXFx9Y5tjfexoeuTpO9///tKS0tTp06d9MUXX+gXv/iFMjMz9eabb5pYbdPt3btX6enpqqioUExMjFavXq0BAwZo9+7dQXPvLnWNUuu/f5K0cuVK7dy5U9u2bbvoPbP/GyTc4LKuv/56z/eDBw/W6NGjlZaWptdff10/+MEPTKwMLXX77bd7vr/qqqs0ePBg9ezZUxkZGZo4caKJlTXf3LlztW/fvlY9Dqwxl7q+H/7wh57vr7rqKqWkpGjixIk6evSoevbs6e8ym61v377avXu3ioqKtGrVKs2ZM0ebNm0yuyyvutQ1DhgwoNXfv+zsbM2fP18bNmxQZGSk2eVchG6pK9ShQweFhoZeNAI8Pz9fycnJJlXlW3FxcerTp4+OHDlidileV3fP2tL9lKQePXqoQ4cOre6ezps3T2+//bY+/PBDdenSxbM/OTlZlZWVKiwsrHd8a7uPl7q+howePVqSWs09jIiIUK9evTR8+HAtWbJEQ4YM0dNPPx0090669DU2pLXdvx07dqigoEDDhg1TWFiYwsLCtGnTJj3zzDMKCwtTUlKSqfeRcHOFIiIiNHz4cG3cuNGzz+12a+PGjfX6VoNJSUmJjh49qpSUFLNL8bru3bsrOTm53v10OBzaunVr0N5PSTp16pTOnTvXau6pYRiaN2+eVq9erQ8++EDdu3ev9/7w4cMVHh5e7z5mZmYqKyurVdzHy11fQ3bv3i1JreYefpPb7ZbT6Wz1964xddfYkNZ2/yZOnKi9e/dq9+7dnm3EiBGaNWuW53tT76PPhyy3AStXrjSsVquxfPly48CBA8YPf/hDIy4uzsjLyzO7NK/46U9/amRkZBjHjx83Pv30U2PSpElGhw4djIKCArNLa5Hi4mJj165dxq5duwxJxv/93/8Zu3btMk6ePGkYhmEsXbrUiIuLM9auXWt88cUXxvTp043u3bsb5eXlJlfedI1dY3FxsfGzn/3M2Lx5s3H8+HHj/fffN4YNG2b07t3bqKioMLv0Jrn//vsNu91uZGRkGLm5uZ6trKzMc8x9991ndO3a1fjggw+M7du3G+np6UZ6erqJVTfd5a7vyJEjxuLFi43t27cbx48fN9auXWv06NHDuPbaa02uvGl++ctfGps2bTKOHz9ufPHFF8Yvf/lLw2KxGOvXrzcMo3XfuzqNXWNrv3+X8s0ZYGbeR8KNl/zhD38wunbtakRERBijRo0ytmzZYnZJXvO9733PSElJMSIiIozOnTsb3/ve94wjR46YXVaLffjhh4aki7Y5c+YYhlEzHfzBBx80kpKSDKvVakycONHIzMw0t+hmauway8rKjMmTJxsdO3Y0wsPDjbS0NOPee+9tVWG8oWuTZLz00kueY8rLy40HHnjAiI+PN6KiooybbrrJyM3NNa/oZrjc9WVlZRnXXnut0b59e8NqtRq9evUyfv7znxtFRUXmFt5Ed999t5GWlmZEREQYHTt2NCZOnOgJNobRuu9dncausbXfv0v5Zrgx8z5aDMMwfN8+BAAA4B+MuQEAAEGFcAMAAIIK4QYAAAQVwg0AAAgqhBsAABBUCDcAACCoEG4AAEBQIdwAAICgQrgBEJDOnDmj+++/X127dpXValVycrKmTJmiTz/9VJJksVi0Zs0ac4sEEJDCzC4AABpyyy23qLKyUn/729/Uo0cP5efna+PGjTp37pzZpQEIcCy/ACDgFBYWKj4+XhkZGRo/fvxF73fr1k0nT570vE5LS9OJEyckSWvXrtUjjzyiAwcOqFOnTpozZ45+/etfKyys5v/LWSwW/elPf9K//vUvZWRkKCUlRU888YRuvfVWv1wbAN+jWwpAwImJiVFMTIzWrFkjp9N50fvbtm2TJL300kvKzc31vP744481e/ZszZ8/XwcOHNDzzz+v5cuX67HHHqt3/oMPPqhbbrlFe/bs0axZs3T77bfr4MGDvr8wAH5Byw2AgPTPf/5T9957r8rLyzVs2DCNHz9et99+uwYPHiyppgVm9erVmjFjhuecSZMmaeLEiVq4cKFn36uvvqr//u//Vk5Ojue8++67T8uWLfMcM2bMGA0bNkx/+tOf/HNxAHyKlhsAAemWW25RTk6O/vWvf2nq1KnKyMjQsGHDtHz58kues2fPHi1evNjT8hMTE6N7771Xubm5Kisr8xyXnp5e77z09HRaboAgwoBiAAErMjJS1113na677jo9+OCDuueee/Twww/rzjvvbPD4kpISPfLII7r55psb/CwAbQMtNwBajQEDBqi0tFSSFB4eLpfLVe/9YcOGKTMzU7169bpoCwn56p+7LVu21Dtvy5Yt6t+/v+8vAIBf0HIDIOCcO3dOt912m+6++24NHjxYsbGx2r59u5544glNnz5dUs2MqY0bN2rcuHGyWq2Kj4/XQw89pO985zvq2rWrbr31VoWEhGjPnj3at2+ffvvb33o+/4033tCIESP0//7f/9OKFSv0+eef6y9/+YtZlwvAyxhQDCDgOJ1OLVq0SOvXr9fRo0dVVVWl1NRU3XbbbfrVr36ldu3a6a233tJPfvITnThxQp07d/ZMBX/vvfe0ePFi7dq1S+Hh4erXr5/uuece3XvvvZJqBhT/8Y9/1Jo1a/TRRx8pJSVFjz/+uL773e+aeMUAvIlwA6BNaWiWFYDgwpgbAAAQVAg3AAAgqDCgGECbQk88EPxouQEAAEGFcAMAAIIK4QYAAAQVwg0AAAgqhBsAABBUCDcAACCoEG4AAEBQIdwAAICgQrgBAABB5f8Hi1aIxHll510AAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.plot(metrics_history['train_loss'])\n",
"plt.title('Training Loss')\n",
"plt.xlabel('Step')\n",
"plt.ylabel('Loss')\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "MoqcdZQUZCqk",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "MoqcdZQUZCqk",
"outputId": "1b7ceb74-61fe-463f-d367-b5b9b02bd971"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"array_metadatas d\t\t _METADATA _sharding\n",
"_CHECKPOINT_METADATA manifest.ocdbt ocdbt.process_0\n"
]
}
],
"source": [
"import orbax.checkpoint as orbax\n",
"\n",
"state = nnx.state(model)\n",
"\n",
"checkpointer = orbax.PyTreeCheckpointer()\n",
"checkpointer.save('/content/save', state)\n",
"\n",
"# Make sure the files are there\n",
"!ls /content/save/"
]
}
],
"metadata": {
"accelerator": "TPU",
"colab": {
"gpuType": "V28",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 5
}